Bash-скрипты, часть 9: регулярные выражения
Содержание:
- ОПЦИИ
- Синтаксис
- Оглавление
- Как найти текст, который начинает и заканчивается с определённых строк
- Рассмотрим ещё один пример поиска фрагментов из нескольких строк
- Команда grep без опций и аргумента.
- Examples
- Анкоры
- РАСШИРЕННЫЕ РЕГУЛЯРНЫЕ ВЫРАЖЕНИЯ
- Поиск файлов по содержанию (поиск текстовых строк в файлах).
- Основные команды grep
- Grep NOT
- Context line control
- Добавление контекста
- Любой символ
- Примеры использования
ОПЦИИ
Давайте рассмотрим самые основные опции утилиты, которые помогут более эффективно выполнять поиск текста в файлах grep:
- -b — показывать номер блока перед строкой;
- -c — подсчитать количество вхождений шаблона;
- -h — не выводить имя файла в результатах поиска внутри файлов Linux;
- -i — не учитывать регистр;
- — l — отобразить только имена файлов, в которых найден шаблон;
- -n — показывать номер строки в файле;
- -s — не показывать сообщения об ошибках;
- -v — инвертировать поиск, выдавать все строки кроме тех что содержат шаблон;
- -w — искать шаблон, как слово, окруженное пробелами;
- -e — использовать регулярные выражения при поиске;
- -An — показать вхождение и n строк до него;
- -Bn — показать вхождение и n строк после него;
- -Cn — показать n строк до и после вхождения;
Все самые основные опции рассмотрели, и даже больше, теперь перейдем к примерам работы команды grep linux.
Синтаксис
Рассмотрим синтаксис.
grep шаблон
Или так:
Команда | grep шаблон
Здесь под параметрами понимаются аргументы, с помощью которых настраивается поиск и вывод на экран. Например нужно найти слово «линукс», и не учитывать регистр при поиске. Тогда нужно использовать опцию «-i».
Шаблон — это выражение или строка.
Имя файла — где искать.
Основные параметры:
—help. Вывести справочную информацию.
-i. Не учитывать регистр при поиске.
-V. Узнать текущую версию.
-v. Инвертированный поиск.
-s. Не выводить на экран сообщения об ошибкам. Например сообщение о несуществующих файлах.
-r. Поиск в каталогах, подкаталогах или рекурсивный grep.
-w. Искать как слово с пробелами.
-с. Опция считает количество вхождений (счетчик).
-e. Регулярные выражения.
Примеры
Найдем все файлы в текущей директории где встречается слово «linux».
grep linux ./*

Здесь:
- linux — слово которое нужно искать;
- точка — текущая директория;
- звездочка — искать во всех файлах.
Чтобы начать поиск без учета регистра необходимо добавить аргумент «-i». В нашем примере получится так:
grep -i linux ./*

Поиск в конкретном документе. Для примера найдем в документе «test» слово «хороший». Для этого с помощью утилиты «cd» зайдем в текущую директорию, где лежит файл «test». В моем случаи он находится в домашнем каталоге, я ввожу просто «cd».
grep хороший test

Здесь:
- хороший — слово которое нужно найти;
- test — файл, где искать.
Рекурсивный поиск. Чтобы найти определенный текст в определенной директории, используют рекурсивный поиск. Для этого необходимо использовать параметр «-r». Найдем слово «vseprolinux» в домашнем каталоге root и его подкаталогах.
grep -r vseprolinux /etc/root

Найдем три слова сразу в одной строке «все про Линукс». Для этого будем использовать вертикальную черту и введет «grep» три раза.
grep «все» test | grep «про» | grep «Линукс»

Команда grep может сообщить сколько раз встречается слово. Нам поможет опция -с. Посчитаем сколько раз встречается слово «site» в документе «file».
grep -c site file

Как видно на скриншоте выше, в файле «file» три раза встречается слово «site». Однако команда также считает выражение «mysite» за «site». Как сделать чтобы mysite не попал под счетчик? Добавим опцию «-w.»
grep -cw site file

Регулярные выражения.
Регулярные выражение в утилите «grep» — это мощная функция, которая расширяет возможности поиска. Чтобы активировать эту функцию или режим, используется аргумент «-e».
Символы в выражениях:
- $ — конец строки;
- ^ — начало строки;
- [] — указывается диапазон значений или конкретные через запятую.
Найдем цифры 1-5 в документе «file».
grep file
В скобках написано диапазон значений от одного до пяти, также можно написать конкретные значения через запятую, так:
Оглавление
1. Описание программ grep
2. Вызов программы grep
3. Справка по команде grep
4 Опции grep
4.1 Общая информация о программе
4.2 Выбор типа регулярного выражения
4.3 Управление работой регулярных выражений
4.4 Управление выводом
4.5 Управление префиксом выходной строки
4.6 Управление контекстными строками
4.7 Выбор файлов и директорий
4.8 Остальные опции
5. Регулярные выражения
5.1 Фундаментальная структура
5.2 Классы символов и Выражения в квадратных скобках
5.3 Анкоры
5.4 Символы с обратным слешем и Специальные выражения
5.5 Повторения
5.6 Объединение регулярных выражений
5.7 Альтернативы в регулярных выражениях
5.8 Приоритет
5.9 Обратные ссылки и Подвыражения
Базовые и расширенные регулярные выражения
6. Переменные окружения grep
7. Статус выхода
8. Примеры использования grep
Как найти текст, который начинает и заканчивается с определённых строк
Допустим, в HTML коде есть конструкция:
<div class="onp-locker-call….. здесь интересующие нас строки </div>
Строка <div class=»onp-locker-call….. может иметь различные варианты например:
<div class="onp-locker-call" style="display: none;" data-lock-id="onpLock443607">
Или так:
<div class="onp-locker-call" style="display: none;" data-lock-id="onpLock781340">
Но суть в любом случае одна — нам нужно найти фрагмент, начинающийся и заканчивающийся с определённых строк. При этом мы не знаем точное количество строк и, возможно, окаймляющие строки также могут различаться (то есть поиск выполняется по регулярному выражению).
Имеется несколько способов выполнить такой поиск. На ум в первую очередь приходит команда grep, но у Linux есть более удобные инструменты — выражения диапазона, которые поддерживаются командами sed и awk.
Если нам нужно найти строки вида:
<div class="onp-locker-call….. здесь интересующие нас строки </div>
Тогда команда sed будет следующей:
sed -n '/<div class="onp-locker-call/,/<\/div>/p' ФАЙЛ
Рассмотрим чуть более простой пример, имется файл со следующим содержимым:
zdk aaa b12 cdn dke kdn
Мне нужно найти содержимое между любыми произвольными строками.
Допустим, я хочу найти содержимое между строками aaa и cdn, то есть я должен получить:
aaa b12 cdn
Или я хочу найти содержимое между строками zdk и dke, то есть вывод должен быть таким:
zdk aaa b12 cdn dke
Каким образом добиться этого?
Нужно задействовать команду sed, использующую выражение диапазонов.
Синтаксис запуска:
sed -n '/НАЧАЛО_ДИАПАЗОНА/,/КОНЕЦ_ДИАПАЗОНА/p' ФАЙЛ
Для указанных выше примеров запуск команды такой:
sed -n '/aaa/,/cdn/p' ФАЙЛ aaa b12 cdn
Для второго случая:
sed -n '/zdk/,/dke/p' ФАЙЛ zdk aaa b12 cdn dke
Использование опции -n подавляет автоматический вывод, то есть будут напечатаны только строки, для которых это явно запрошено. То есть это случиться когда будет найден диапазон /aaa/,/cdn/.
Эти выражения диапазонов также доступны в awk, там вы можете сказать:
awk '/zdk/,/dke/' ФАЙЛ
Конечно, все эти условия могут быть развёрнуты в более строгие выражения схожие с регулярными выражениями, к примеру:
sed -n '/^aaa$/,/^cdn$/p' ФАЙЛ
Это позволит проверять, что строки состоят из точных совпадений aaa и cdn и ничего более.
Показанные два примера можно скомпоновать в одну единственную команду sed с более сложным синтаксисом:
sed -n '
/^aaa$/,/^cdn$/w output1
/^zdk$/,/^dke$/w output2
' ФАЙЛ
Рассмотрим ещё один пример поиска фрагментов из нескольких строк
Допустим имеется файл со следующим модержимым:
kkkkkkkkkkk jjjjjjjjjjjjjjjjjj gggggggggggg/CK JHGHHHHHHHH HJKHKKLKLLL JNBHBHJKJJLKKL JLKKKLLKJLKJ/D GGGGGGGGGGGGGG GGGGGGGGGGGGGG
Мне хочется, чтобы были выбраны строки начиная с CK с конца строки и поиск совпадений был остановлен, когда строка на конце имеет D.
То есть должно быть выведено:
gggggggggggg/CK JHGHHHHHHHH HJKHKKLKLLL JNBHBHJKJJLKKL JLKKKLLKJLKJ/D
Лучше использовать awk или sed:
awk '/CK$/,/D$/' file.txt
ИЛИ:
sed -n '/CK$/,/D$/p' file.txt
Если хочется именно grep, то для GNU grep это делается следующим образом:
grep -oPz '(?s)(?<=\n)\N+CK\n.*?D(?=\n)' file.txt
Здесь:
- -P активирует perl-regexp
- -z устанавливает разделитель строк на NUL. Это принуждает grep видеть весь файл как одну строку
- -o печать только совпадающей части
- (?s) активирует PCRE_DOTALL, поэтому . (точка) это любые символы или newline
- \N совпадает со всем, кроме newline
- .*? находит . в режиме nongreedy (не жадный)
- (?<=..) это look-behind (смотреть после) выражения
- (?=..) это look-ahead (смотреть до) выражения
Рассмотрим ещё пример.
Команда grep без опций и аргумента.
Если не указано имени файла, то команда обрабатывает стандартный ввод, например строки, набранные на клавиатуре:
grep кот у меня есть кошка,(Enter) вернее это кот,(Enter) вернее это кот, который умеет(Enter) который умеет ловить мышей.(Enter) (Ctrl+c)
В скобках показано, когда я нажимал клавишу Enter, чтобы перейти на новую строку. Одновременно, при нажатии Enter, программа выводила строки, содержащие ОБРАЗЕЦ (кот), отсюда и удвоение этих строк. Видно, что команда реагировала просто на сочетание букв, а не на слово «кот», иначе строка со словом «который» не попала бы в вывод.
Тут мы подошли к очень важному определению строки.
Строкой команда grep (как и все остальные команды Юникс) считает все символы, находящиеся между двумя символами новой строки. Эти невидимые на экране символы возникают в тексте каждый раз, когда пользователь нажимает клавишу Enter
В Юниксовидных системах символ новой строки обозначается обратным слэшем с буквой n (\n). Таким образом, строка может быть любого размера, начиная с одного символа и до многомегабайтного текста. И команда grep честно выведет эту строку, при условии, что она содержит ОБРАЗЕЦ.
Examples
Tip
If you haven’t already seen our section, we suggest reviewing that section first.
grep chope /etc/passwd
Search /etc/passwd for user chope.
grep "May 31 03" /etc/httpd/logs/error_log
Search the Apache error_log file for any error entries that happened on May 31st at 3 A.M. By adding quotes around the string, this allows you to place spaces in the grep search.
grep -r "computerhope" /www/
Recursively search the directory /www/, and all subdirectories, for any lines of any files which contain the string «computerhope«.
grep -w "hope" myfile.txt
Search the file myfile.txt for lines containing the word «hope«. Only lines containing the distinct word «hope» are matched. Lines where «hope» is part of a word (e.g., «hopes») are not be matched.
grep -cw "hope" myfile.txt
Same as previous command, but displays a count of how many lines were matched, rather than the matching lines themselves.
grep -cvw "hope" myfile.txt
Inverse of previous command: displays a count of the lines in myfile.txt which do not contain the word «hope».
grep -l "hope" /www/*
Display the file names (but not the matching lines themselves) of any files in /www/ (but not its subdirectories) whose contents include the string «hope«.
Анкоры
Символ каретки (^) и знак доллара ($) считаются в регулярных выражениях анкорами. Это означает, что они вызывают совпадение, только если регулярное выражение найдено в начале строки (^) или в конце строки ($):
grep -h '^zip' dirlist*.txt zip zipcloak zipdetails zipgrep zipinfo zipnote zipsplit
grep -h 'zip$' dirlist*.txt gunzip gzip funzip gpg-zip mzip p7zip preunzip prezip unzip zip
grep -h '^zip$' dirlist*.txt zip
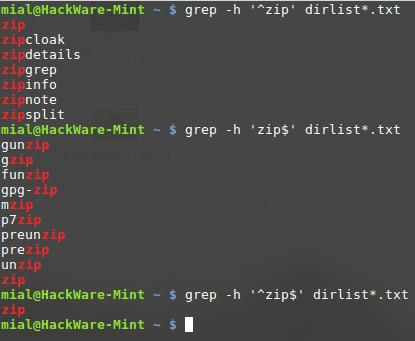
Здесь мы искали по спискам файлов строку «zip», расположенную в начале строки, в конце строки, а также в строке, где она была бы одновременно и в начале, и в конце (т.е. вся строка содержала бы только «zip»)
Обратите внимание, что регулярное выражение «^$» (начало и конец между которыми ничего нет) будет соответствовать пустым строкам.
Небольшое лирическое отступление: помощник по разгадыванию кроссвордов
Даже с нашими ограниченными на данный момент познаниями в регулярных выражениях мы можем делать что-то полезное.
Если вы когда-нибудь разгадывали кроссворды, то вам нужно было решать задачи вроде «что за слово из пяти букв, где третья буква «j», а последняя буква «r», которое означает…». Этот вопрос может заставить задуматься. Знаете ли вы, что в системе Linux есть словарь? А он есть. Загляните в директорию /usr/share/dict, там вы можете найти один или несколько словарей. Словари, размещённые там, это просто длинные списки слов по одному на строку, расположенные в алфавитном порядке. В моей системе файл словаря содержит 99171 слов. Для поиска возможных ответов на вышеприведённый вопрос кроссворда, мы можем сделать так:
grep -i '^..j.r$' /usr/share/dict/american-english Major major
Используя это регулярное выражение, мы можем найти все слова в нашем файле словаря, которое имеет длину в пять букв, имеет «j» в третьей позиции и «r» в последней позиции.
В примере использовался английский файл словаря, поскольку он присутствует в системе по умолчанию. Предварительно скачав соответствующий словарь, вы можете делать аналогичные поиски по словам на кириллице или из любых других символов.
РАСШИРЕННЫЕ РЕГУЛЯРНЫЕ ВЫРАЖЕНИЯ
GIST | Дизъюнкция. Подобно тому, как квадратные скобки задают различные возможные варианты совпадения одного символа, дизъюнкция позволяет указать альтернативные совпадения для строк символов или выражений. Для обозначения дизъюнкции используется символ вертикальной черты:
--extended-regexp --color=always 'George|John'
George Washington, 1789-1797 John Adams, 1797-1801 Thomas Jefferson, 1801-1809
George Washington, 1789-1797 John Adams, 1797-1801
GIST | Совпадение ноль или один раз. В расширенных регулярных выражениях существуют несколько дополнительных метасимволов, указывающих частоту повторения символа или выражения (подобно тому, как метасимвол звездочка указывает на совпадения 0 или более раз). Один из таких метасимволов это вопросительный знак, который делает предыдущий символ или выражение, по сути, необязательными:
--extended-regexp --color=always '^(Andrew )?John'
John Adams, 1797-1801 Andrew Johnson, 1865-1869 Lyndon Baines Johnson, 1963-1969
John Adams, 1797-1801 Andrew Johnson, 1865-1869
GIST | Совпадение один или более раз. Для этого предусмотрен метасимвол в виде знака плюс. Он работает почти как символ звездочка, за исключением того, что выражение должно совпасть хотя бы один раз:
--extended-regexp --color=always '^ ]+$'
John Adams Andrew Johnson, 1865-1869 Lyndon Baines Johnson, 1963-1969
John Adams
GIST | Совпадение указанное количество раз. Для этого можно использовать фигурные скобки. Эти метасимволы используются для указания точного количества, диапазона, а также верхнего и нижнего предела количества совпадений выражения:
--extended-regexp --color=always
'{1,3}\.{1,3}\.{1,3}\.{1,3}'
42 127.0.0.1
127.0.0.1
Команда grep настолько полезна, многофункциональна и проста в употреблении, что, однажды познакомившись с ней, невозможно представить себе работу без нее.
Поиск файлов по содержанию (поиск текстовых строк в файлах).
Стандартные утилиты для поиска текстовых строк в файлах — grep / egrep для обычных поисков выражения и fgrep для поиска литеральных строк. Чтобы искать выражение во всех файлах в текущем каталоге, просто наберите:
Если Вам трудно запомнить эти длинные команды, используйте маленький скрипт, который можно загрузить отсюда: grepfind.gz . Скрипт еще и удаляет не-печатаемые символы из строки поиска, чтобы Вы случайно не получили в результате поиска egrep -ом двоичный файл.
Очень интересная программа поиска — agrep . Agrep работает в основном подобно egrep , но позволяет искать с учетом орфографических ошибок. Чтобы искать выражение и разрешить максимум 2 орфографические ошибки, наберите:
После этого Вы можете искать строку во всех файлах, которые были предварительно индексированы
|
glimpse -i -2 «search exprission» |
glimpse — тоже допускает орфографические ошибки (как и agrep) и -2 указывает, что разрешены две ошибки. glimpse доступен на
Бывает, что вы знаете, что файл или каталог существует, но не знаете, как его
найти. Существует несколько команд, которые помогут вам в этом:
find ,
locate и which .
4.10.1. Команда find
Команда find имеет следующий формат:
Find путь образец_для_поиска
Если вы не укажете путь, find начнет поиск заданного
образца с текущего каталога и продолжит его по всем имеющимся в нем
подкаталогам.
Команда find имеет множество опций, ознакомиться с
которыми можно, прочитав man-страницу (введите в командной строке
man find). Чаще всего используется опция
-name , которая задает поиск всех файлов и каталогов,
содержащих в названии определенное сочетание букв.
Find . -name tes
Эта команда задает поиск в текущем каталоге всех файлов, содержащих в
названии «tes
».
4.10.2. Команда locate
С помощью этой команды вы можете увидеть все файлы или каталоги,
названия которых содержат искомый образец. Например, для поиска файла,
содержащего в названии слово
dog , введите в командной строке:
Locate dog
Команда locate использует базу данных для определения местонахождения файлов или каталогов,
содержащих в названии слово dog . Результаты поиска могут включать файл с
названием
dog , файл с названием
bulldog.txt , каталог с названием
/dogs/ и так далее. Чтобы узнать больше о команде
locate , обратитесь к ее man-странице (введите в командной строке man locate).
При условии, что база данных обновлена, команда locate осуществляет поиск очень быстро.
Обновление базы данных команды locate происходит каждую ночь при помощи службы cron .
cron — это небольшая программа, которая запускается в фоновом режиме и
выполняет
различные задачи (такие как обновление базы данных команды
locate) через определенные промежутки времени. Для доступа к
руководству
cron наберите в командной строке
man cron .
cron периодически обновляет базу данных
slocate , которая используется для определения местонахождения файлов или каталогов.
Переключение между операционными системами и отключение машины в конце
дня препятствует автоматическому обновлению базы данных при помощи
cron .
Чтобы обновить базу данных вручную, войдите в систему как root (набрав
в командной строке
su — и введя пароль root»а)
и наберите в командной строке updatedb .
Через некоторое время база данных slocate , используемая командой locate , обновится.
Закончив работу, для выполнения которой необходимо быть root»ом,
наберите в командной строке exit — вы вернетесь в вашу сессию.
Основные команды grep
Вывести все упоминания слова
Предположим вы запустили
CentOS Linux
и хотите посмотреть все установленные пакеты в названии которых есть слово
kernel
yum list installed | grep kernel
abrt-addon-kerneloops.x86_64 2.1.11-60.el7.centos @base
kernel.x86_64 3.10.0-1160.el7 @anaconda
kernel.x86_64 3.10.0-1160.2.2.el7 @updates
kernel.x86_64 3.10.0-1160.6.1.el7 @updates
kernel-devel.x86_64 3.10.0-1160.2.2.el7 @updates
kernel-devel.x86_64 3.10.0-1160.6.1.el7 @updates
kernel-headers.x86_64 3.10.0-1160.6.1.el7 @updates
kernel-tools.x86_64 3.10.0-1160.6.1.el7 @updates
kernel-tools-libs.x86_64 3.10.0-1160.6.1.el7 @updates
И наоборот, можно посмотреть все строки где нет слова kernel
: нужно добавить опцию -v
yum list installed | grep -v kernel
Если вам нужно найти что-то в файле, можно вместо | воспользоваться выражением
grep ‘\bkernel\b’ huge_file
Где huge_file это имя файла в текущей директории в котором мы ищем отдельные слова kernel.
То есть слова akernel или kernelz найдены не будут
Вывести всё, что начинается со слова
Если нам теперь не нужны пакеты, в которых слово
kernel
в середине, а только те, которые начинаются с
kernel добавим перед словом знак ^
yum list installed | grep ^kernel
kernel.x86_64 3.10.0-1160.el7 @anaconda
kernel.x86_64 3.10.0-1160.2.2.el7 @updates
kernel.x86_64 3.10.0-1160.6.1.el7 @updates
kernel-devel.x86_64 3.10.0-1160.2.2.el7 @updates
kernel-devel.x86_64 3.10.0-1160.6.1.el7 @updates
kernel-headers.x86_64 3.10.0-1160.6.1.el7 @updates
kernel-tools.x86_64 3.10.0-1160.6.1.el7 @updates
kernel-tools-libs.x86_64 3.10.0-1160.6.1.el7 @updates
grep -E ‘ion$’ huge_file
compensation
generation
Допустим вы знаете только начало и конец слова
grep -E ‘^to..le$’ huge_file
topbicycle
Несколько символов подряд
Найти слова с пятью гласными подряд
grep -E ‘{5}’ /usr/share/dict/words
cadiueio
Chaouia
cooeeing
euouae
Guauaenok
miaoued
miaouing
Pauiie
queueing
Grep NOT
7. Grep NOT using grep -v
Using grep -v you can simulate the NOT conditions. -v option is for invert match. i.e It matches all the lines except the given pattern.
grep -v 'pattern1' filename
For example, display all the lines except those that contains the keyword “Sales”.
$ grep -v Sales employee.txt 200 Jason Developer Technology $5,500 300 Raj Sysadmin Technology $7,000 400 Nisha Manager Marketing $9,500
You can also combine NOT with other operator to get some powerful combinations.
For example, the following will display either Manager or Developer (bot ignore Sales).
$ egrep 'Manager|Developer' employee.txt | grep -v Sales 200 Jason Developer Technology $5,500 400 Nisha Manager Marketing $9,500
Context line control
| -A NUM,—after-context=NUM | Print NUM lines of trailing context after matching lines. Places a line containing a group separator (—) between contiguous groups of matches. With the -o or —only-matching option, this has no effect and a warning is given. |
| -B NUM,—before-context=NUM | Print NUM lines of leading context before matching lines. Places a line containing a group separator (—) between contiguous groups of matches. With the -o or —only-matching option, this has no effect and a warning is given. |
| -C NUM, —NUM,—context=NUM | Print NUM lines of output context. Places a line containing a group separator (—) between contiguous groups of matches. With the -o or —only-matching option, this has no effect and a warning is given. |
Добавление контекста
Часто бывает полезно иметь возможность видеть некоторые дополнительные строки — возможно, несовпадающие — для каждой совпадающей строки. это может помочь определить, какие из совпадающих строк вам интересны.
Чтобы отобразить несколько строк после совпадающей строки, используйте параметр -A (после контекста). В этом примере мы запрашиваем три строки:
grep -A 3 -x "20-янв-06 15:24:35" geek-1.log
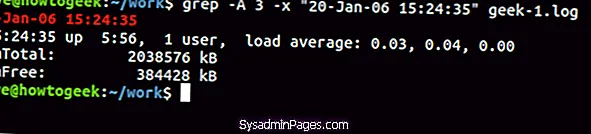
Чтобы увидеть некоторые строки перед совпадающей строкой, используйте (контекст перед) вариант.
grep -B 3 -x "20-янв-06 15:24:35" geek-1.log
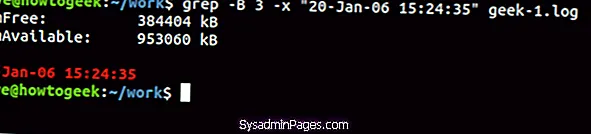
И чтобы включить строки до и после совпадающей строки, используйте (контекст) вариант.
grep -C 3 -x "20-янв-06 15:24:35" geek-1.log
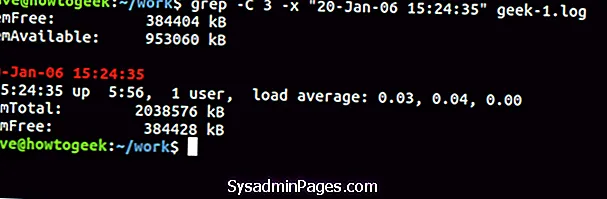
Любой символ
Первый метасимвол, с которого мы начнём знакомство, это символ точки, который означает «любой символ». Если мы включим его в регулярное выражение, то он будет соответствовать любому символу для этой позиции символа. Пример:
grep -h '.zip' dirlist*.txt bunzip2 bzip2 bzip2recover gunzip gzip funzip gpg-zip mzip p7zip preunzip prezip prezip-bin unzip unzipsfx
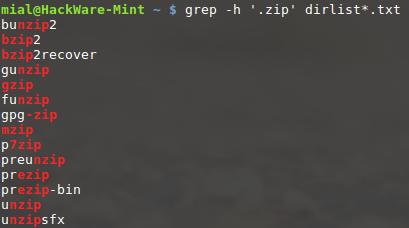
Мы искали любую строку в наших файлах, которая соответствует регулярному выражению «.zip». Нужно отметить парочку интересных моментов в полученных результатах
Обратите внимание, что программа zip не была найдена. Это от того, что включение метасимвола точка в наше регулярное выражение увеличило длину, требуемую для совпадения, до четырёх символов, а поскольку имя «zip» содержит только три, то оно не соответствует
Также если какие-либо файлы из наших списков содержали расширение файла .zip, они также считались бы подходящими, поскольку символ точки в расширении файла, также подходит под условие «любой символ».
Примеры использования
С теорией покончено, теперь перейдём к практике. Рассмотрим несколько основных примеров поиска внутри файлов Linux с помощью grep, которые могут вам понадобиться в повседневной жизни.
Поиск текста в файлах
В первом примере мы будем искать пользователя User в файле паролей Linux. Чтобы выполнить поиск текста grep в файле /etc/passwd введите следующую команду:
В результате вы получите что-то вроде этого, если, конечно, существует такой пользователь:
А теперь не будем учитывать регистр во время поиска. Тогда комбинации ABC, abc и Abc с точки зрения программы будут одинаковы:
Вывести несколько строк
Например, мы хотим выбрать все ошибки из лог-файла, но знаем, что в следующей строчке после ошибки может содержаться полезная информация, тогда с помощью grep отобразим несколько строк. Ошибки будем искать в Xorg.log по шаблону «EE»:
Выведет строку с вхождением и 4 строчки после неё:
Выведет целевую строку и 4 строчки до неё:
Выведет по две строки с верху и снизу от вхождения.
Регулярные выражения в grep
Регулярные выражения grep — очень мощный инструмент в разы расширяющий возможности поиска текста в файлах. Для активации этого режима используйте опцию -e. Рассмотрим несколько примеров:
Поиск вхождения в начале строки с помощью спецсимвола «^», например, выведем все сообщения за ноябрь:
Поиск в конце строки — спецсимвол «$»:
Найдём все строки, которые содержат цифры:
Вообще, регулярные выражения grep — это очень обширная тема, в этой статье я лишь показал несколько примеров. Как вы увидели, поиск текста в файлах grep становиться ещё эффективнее. Но на полное объяснение этой темы нужна целая статья, поэтому пока пропустим её и пойдем дальше.
Рекурсивное использование grep
Если вам нужно провести поиск текста в нескольких файлах, размещённых в одном каталоге или подкаталогах, например в файлах конфигурации Apache — /etc/apache2/, используйте рекурсивный поиск. Для включения рекурсивного поиска в grep есть опция -r. Следующая команда займётся поиском текста в файлах Linux во всех подкаталогах /etc/apache2 на предмет вхождения строки mydomain.com:
В выводе вы получите:
Здесь перед найденной строкой указано имя файла, в котором она была найдена. Вывод имени файла легко отключить с помощью опции -h:
Поиск слов в grep
Когда вы ищете строку abc, grep будет выводить также kbabc, abc123, aafrabc32 и тому подобные комбинации. Вы можете заставить утилиту искать по содержимому файлов в Linux только те строки, которые выключают искомые слова с помощью опции -w:
Количество вхождений строки
Утилита grep может сообщить, сколько раз определённая строка была найдена в каждом файле. Для этого используется опция -c (счетчик):
C помощью опции -n можно выводить номер строки, в которой найдено вхождение, например:
Получим:
Инвертированный поиск в grep
Команда grep Linux может быть использована для поиска строк в файле, которые не содержат указанное слово. Например, вывести только те строки, которые не содержат слово пар:
Вывод имени файла
Вы можете указать grep выводить только имя файла, в котором было найдено заданное слово с помощью опции -l. Например, следующая команда выведет все имена файлов, при поиске по содержимому которых было обнаружено вхождение primary: