Расчет коэффициента детерминации в microsoft excel
Содержание:
- Регрессионный анализ в Excel
- Регрессия В Excel
- Разбор результатов анализа
- Как интерпретировать результаты анализа
- Корреляционно-регрессионный анализ
- Пример регрессионного анализа №2
- Оценка параметров
- Решение эконометрики в Экселе
- Основные задачи и виды регрессии
- Примеры решений онлайн: линейная регрессия
- Парные (линейные) и частные коэффициенты корреляции
- Корреляционный анализ в Excel
Регрессионный анализ в Excel
Показывает влияние одних значений (самостоятельных, независимых) на зависимую переменную. К примеру, как зависит количество экономически активного населения от числа предприятий, величины заработной платы и др. параметров. Или: как влияют иностранные инвестиции, цены на энергоресурсы и др. на уровень ВВП.
Результат анализа позволяет выделять приоритеты. И основываясь на главных факторах, прогнозировать, планировать развитие приоритетных направлений, принимать управленческие решения.
- линейной (у = а + bx);
- параболической (y = a + bx + cx 2 );
- экспоненциальной (y = a * exp(bx));
- степенной (y = a*x^b);
- гиперболической (y = b/x + a);
- логарифмической (y = b * 1n(x) + a);
- показательной (y = a * b^x).
Рассмотрим на примере построение регрессионной модели в Excel и интерпретацию результатов. Возьмем линейный тип регрессии.
Задача. На 6 предприятиях была проанализирована среднемесячная заработная плата и количество уволившихся сотрудников. Необходимо определить зависимость числа уволившихся сотрудников от средней зарплаты.
Модель линейной регрессии имеет следующий вид:
Где а – коэффициенты регрессии, х – влияющие переменные, к – число факторов.
В нашем примере в качестве У выступает показатель уволившихся работников. Влияющий фактор – заработная плата (х).
В Excel существуют встроенные функции, с помощью которых можно рассчитать параметры модели линейной регрессии. Но быстрее это сделает надстройка «Пакет анализа».
Активируем мощный аналитический инструмент:
- Нажимаем кнопку «Офис» и переходим на вкладку «Параметры Excel». «Надстройки».
- Внизу, под выпадающим списком, в поле «Управление» будет надпись «Надстройки Excel» (если ее нет, нажмите на флажок справа и выберите). И кнопка «Перейти». Жмем.
- Открывается список доступных надстроек. Выбираем «Пакет анализа» и нажимаем ОК.
После активации надстройка будет доступна на вкладке «Данные».
Теперь займемся непосредственно регрессионным анализом.
- Открываем меню инструмента «Анализ данных». Выбираем «Регрессия».
- Откроется меню для выбора входных значений и параметров вывода (где отобразить результат). В полях для исходных данных указываем диапазон описываемого параметра (У) и влияющего на него фактора (Х). Остальное можно и не заполнять.
- После нажатия ОК, программа отобразит расчеты на новом листе (можно выбрать интервал для отображения на текущем листе или назначить вывод в новую книгу).

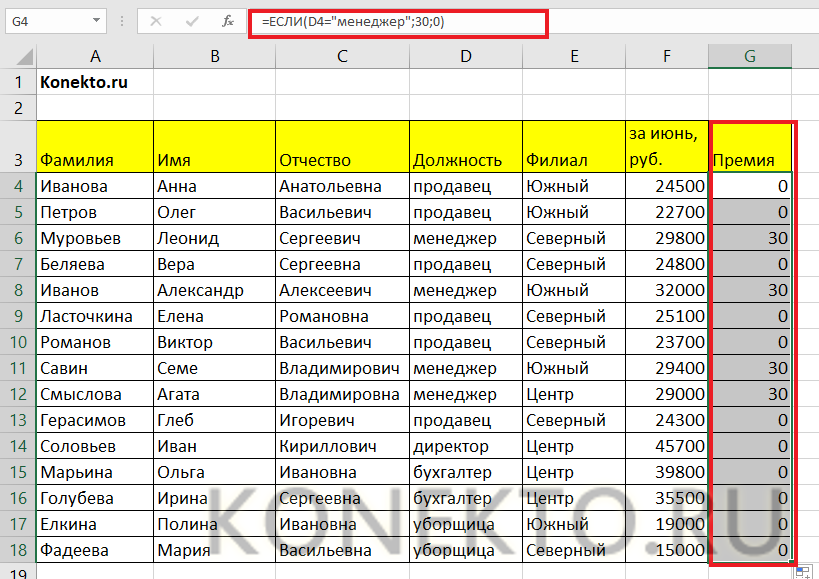
В первую очередь обращаем внимание на R-квадрат и коэффициенты. R-квадрат – коэффициент детерминации
В нашем примере – 0,755, или 75,5%. Это означает, что расчетные параметры модели на 75,5% объясняют зависимость между изучаемыми параметрами. Чем выше коэффициент детерминации, тем качественнее модель. Хорошо – выше 0,8. Плохо – меньше 0,5 (такой анализ вряд ли можно считать резонным). В нашем примере – «неплохо»
R-квадрат – коэффициент детерминации. В нашем примере – 0,755, или 75,5%. Это означает, что расчетные параметры модели на 75,5% объясняют зависимость между изучаемыми параметрами. Чем выше коэффициент детерминации, тем качественнее модель. Хорошо – выше 0,8. Плохо – меньше 0,5 (такой анализ вряд ли можно считать резонным). В нашем примере – «неплохо».
Коэффициент 64,1428 показывает, каким будет Y, если все переменные в рассматриваемой модели будут равны 0. То есть на значение анализируемого параметра влияют и другие факторы, не описанные в модели.
Коэффициент -0,16285 показывает весомость переменной Х на Y. То есть среднемесячная заработная плата в пределах данной модели влияет на количество уволившихся с весом -0,16285 (это небольшая степень влияния). Знак «-» указывает на отрицательное влияние: чем больше зарплата, тем меньше уволившихся. Что справедливо.
Регрессия В Excel
Пакет анализаСервис/Надстройки
Excel 2007Параметры ExcelПараметры Excel

 НадстройкиПакет анализаПерейти
НадстройкиПакет анализаПерейти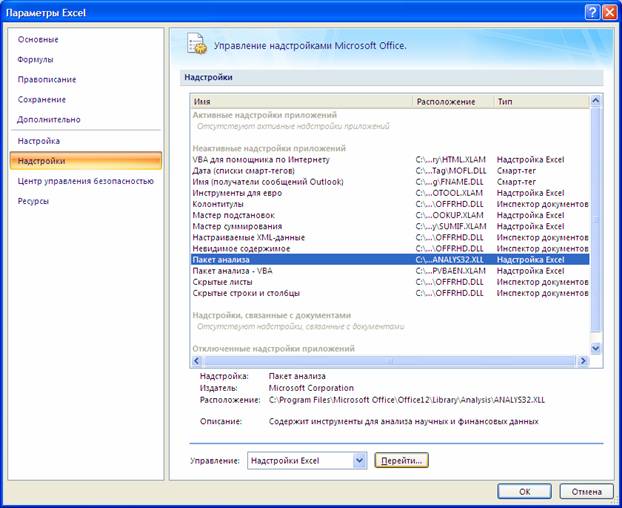
Для построения модели регрессии необходимо выбрать пункт . (В Excel 2007 этот режим находится в блоке ) Появится диалоговое окно, которое нужно заполнить:
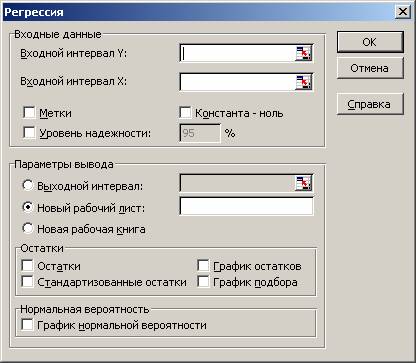 Входной интервалYyВходной интервалX12m(m≤16)МеткиУровень надежностиКонстанта-нольПараметры выводаНовый рабочий листОстатки
Входной интервалYyВходной интервалX12m(m≤16)МеткиУровень надежностиКонстанта-нольПараметры выводаНовый рабочий листОстатки
В результате выводится информация, содержащая все необходимые сведения и сгруппированная в три блока: Регрессионная статистика, Дисперсионный анализ, Вывод остатка. Рассмотрим их подробнее.
1. Регрессионная статистика:
множественный R определяется формулой ;
R-квадрат вычисляется по формуле ;
Нормированный R-квадрат вычисляется по формуле ;
Стандартная ошибка S вычисляется по формуле ;
Наблюдения ¾ это количество данных n.
2. Дисперсионный анализ, строка Регрессия:
Параметр df равен m (количество наборов факторов x);
Параметр SS определяется формулой ;
Параметр MS определяется формулой ;
Статистика F определяется формулой ;
Значимость F. Если полученное число превышает α=1-p, то принимается гипотеза R2 = 0 (нет линейной зависимости), иначе принимается гипотеза R2≠0 (есть линейная зависимость).
3. Дисперсионный анализ, строка Остаток:
Параметр df равен n-m-1;
Параметр SS определяется формулой ;
Параметр MS определяется формулой .
4. Дисперсионный анализ, строка Итого содержит сумму первых двух столбцов.
5. Дисперсионный анализ, строка Y-пересечение содержит значение коэффициента a, стандартной ошибки Sb и t-статистики tb.
P-значение ¾ это значение уровней значимости, соответствующее вычисленным t-статистикам. Определяется функцией СТЬЮДРАСП(t-статистика; n—m-1). Если P-значение превышает α=1-p, то соответствующая переменная статистически незначима и ее можно исключить из модели.
Нижние 95% и Верхние 95% ¾ это нижние и верхние границы 95-процентных доверительных интервалов для коэффициентов теоретического уравнения линейной регрессии. Если в блоке ввода данных значение доверительной вероятности было оставлено по умолчанию, то последние два столбца будут дублировать предыдущие. Если пользователь ввел свое значение доверительной вероятности, то последние два столбца содержат значения нижней и верхней границы для указанной доверительной вероятности.
6. Дисперсионный анализ, строки x1, x2,..,xm содержат значения коэффициентов, стандартных ошибок, t-статистик, P-значений и доверительных интервалов для соответствующих xi.
Блок Вывод остатка содержит значения предсказанного y (в наших обозначениях это ) и остатки .
Разбор результатов анализа
Результаты регрессионного анализа выводятся в виде таблицы в том месте, которое указано в настройках.
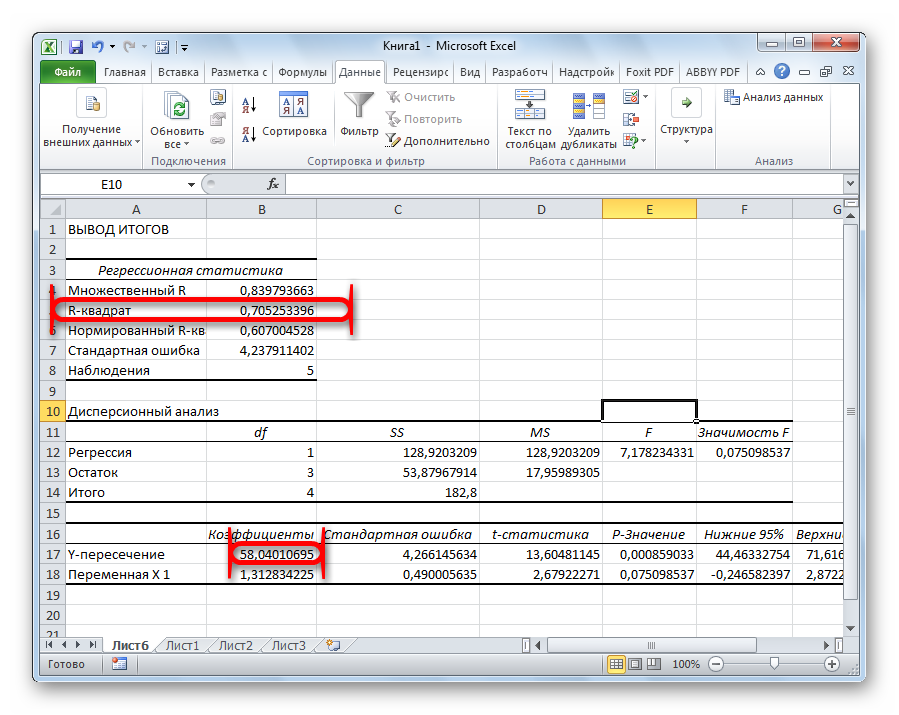
Одним из основных показателей является R-квадрат. В нем указывается качество модели. В нашем случае данный коэффициент равен 0,705 или около 70,5%. Это приемлемый уровень качества. Зависимость менее 0,5 является плохой.
Ещё один важный показатель расположен в ячейке на пересечении строки «Y-пересечение» и столбца «Коэффициенты». Тут указывается какое значение будет у Y, а в нашем случае, это количество покупателей, при всех остальных факторах равных нулю. В этой таблице данное значение равно 58,04.
Значение на пересечении граф «Переменная X1» и «Коэффициенты» показывает уровень зависимости Y от X. В нашем случае — это уровень зависимости количества клиентов магазина от температуры. Коэффициент 1,31 считается довольно высоким показателем влияния.
Как видим, с помощью программы Microsoft Excel довольно просто составить таблицу регрессионного анализа. Но, работать с полученными на выходе данными, и понимать их суть, сможет только подготовленный человек.
Как интерпретировать результаты анализа
Ознакомиться с результатами регрессионного анализа можно в том месте, которое было указано в параметрах. Выглядит он таким приблизительно образом.

Самое главное значение, на которое мы будем ориентироваться – это R-квадрат. В нем записывается качество используемой модели. Чем он выше, тем оно выше. Если оно меньше 0,5, то зависимость считается плохой, если выше – то уже лучше. Чем ближе к 1, тем лучше. Соответственно, максимальный коэффициент – 1.
Также нужно обратить внимание на еще один важный показатель. Его можно найти в ячейке, которая находится на стыке строки Y-пересечение и колонки «Коэффициенты»
Здесь можно увидеть значение Y, которое будет равно нулю при определенных условиях. Также можно понять, насколько наша зависимая переменная является зависимой от факторов. Для этого нужно посмотреть, какая цифра стоит на пересечении граф Переменная X1» и «Коэффициенты». Чем коэффициент выше, тем лучше.
Видим, что программа Microsoft Excel открывает широкие возможности для регрессионного анализа. Но конечно, нужна дополнительная подготовка, чтобы читать эти результаты. Но если вы уже разбираетесь в статистике, то будет значительно проще. А теперь давайте приведем некоторые простые примеры, чтобы было более наглядно понятно, как линейная регрессия проводится на практике.
Корреляционно-регрессионный анализ
На практике эти две методики часто применяются вместе.
Пример:
Теперь стали видны и данные регрессионного анализа.
Регрессионный анализ является одним из самых востребованных методов статистического исследования. С его помощью можно установить степень влияния независимых величин на зависимую переменную. В функционале Microsoft Excel имеются инструменты, предназначенные для проведения подобного вида анализа. Давайте разберем, что они собой представляют и как ими пользоваться.
Но, для того, чтобы использовать функцию, позволяющую провести регрессионный анализ, прежде всего, нужно активировать Пакет анализа. Только тогда необходимые для этой процедуры инструменты появятся на ленте Эксель.
Теперь, когда мы перейдем во вкладку «Данные»
, на ленте в блоке инструментов «Анализ»
мы увидим новую кнопку – «Анализ данных»
.
Пример регрессионного анализа №2
Второй случай, в котором можно проводить регрессионный анализ – это необходимость найти максимальную модель распределения расходов на разные виды рекламы для того, чтобы получить самую большую прибыль. И такую маркетинговую задачу вполне может решить обычный Excel, кто бы мог подумать?
Предположим, максимальный бюджет на рекламу, который может быть потрачен организацией – 170000 рублей. Это ограничение невозможно предусмотреть стандартным средством, описанным выше. Здесь нужно использовать совсем другую надстройку, которая называется «Поиск решения». Есть ее возможность найти в том же разделе, что и описываемую нами. И аналогично пакету анализа, нам необходимо включить эту надстройку в том же самом меню.
Что же собой являет инструмент «Поиск решения»? Это надстройка, позволяющая найти оптимальный способ решения определенной задачи. Она имеет два основных параметра: целевая функция и ограничения. Таким образом, пользователь может находить оптимальную сумму затрат для рекламу в определенных условиях. Это одно из главных преимуществ данного инструмента.
Точно также, как в случае с пакетом анализа, инструмент поиска решения требует наличия математической модели. В качестве неё и выступает целевая функция. В нашем случае она следующая: Y= 2102438,6 + 6,4004 X1 – 54,068 X2 > max. В качестве используемых ограничений используется следующее выражение: X1 + X2 <= 170000, X1>= 0, X2 >=0.
После применения инструмента «Поиск решения» оказывается, что при заданных параметрах и ограничениях оптимально тратить деньги на рекламу по телевидению, поскольку это способно обеспечить максимальную прибыль. Как же пользоваться этим инструментом на практике? Для этого нужно выполнить следующие простые действия.
- Для начала нажать «Параметры Excel», после чего отправиться в категорию «Надстройки».
- После этого в поле «Управление» найти «Надстройки Excel» и кликнуть по «Перейти».
- После этого в списке надстроек активировать «Поиск решения».
После нажатия клавиши ОК надстройка успешно активирована. Далее достаточно просто нажимать на соответствующую кнопку на вкладке «Данные» в той же группе, что и пакет анализа и задать подходящие параметры. После этого программа все сделает самостоятельно. Таким образом, использование регрессии в Excel – очень простая штука. Значительно легче, чем может показаться на первый взгляд, поскольку большую часть действий выполняет программа. Достаточно просто вбить правильные настройки, и дальше можно расслабиться. И да, нужно еще интерпретировать результаты правильно. Но это не проблема. Успехов.
Оценка параметров
Для множественной регрессии (МР) ее осуществляют, используя метод наименьших квадратов (МНК). Для линейных уравнений вида Y = a + b 1 x 1 +…+b m x m + ε строим систему нормальных уравнений (см. ниже)
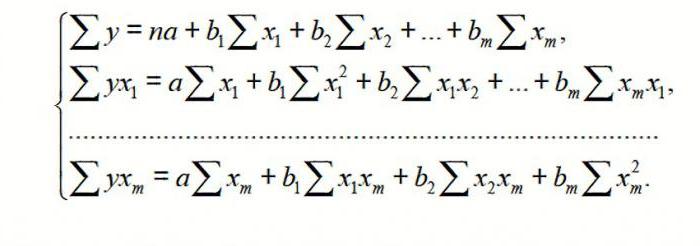
Чтобы понять принцип метода, рассмотрим двухфакторный случай. Тогда имеем ситуацию, описываемую формулой
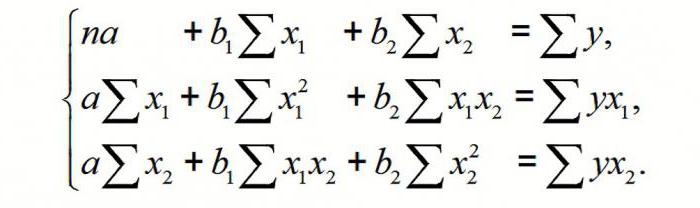
Отсюда получаем:
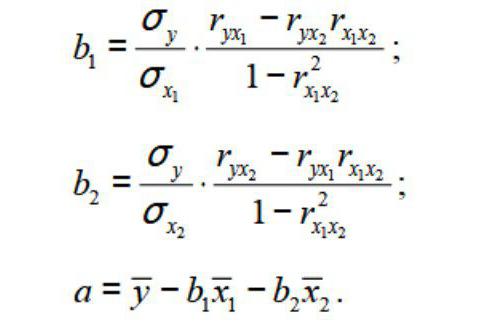
где σ — это дисперсия соответствующего признака, отраженного в индексе.
МНК применим к уравнению МР в стандартизируемом масштабе. В таком случае получаем уравнение:
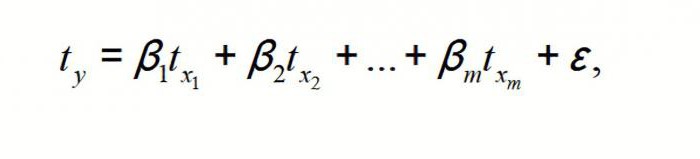
в котором t y , t x 1, … t xm — стандартизируемые переменные, для которых средние значения равны 0; β i — стандартизированные коэффициенты регрессии, а среднеквадратическое отклонение — 1.
Обратите внимание, что все β i в данном случае заданы, как нормируемые и централизируемые, поэтому их сравнение между собой считается корректным и допустимым. Кроме того, принято осуществлять отсев факторов, отбрасывая те из них, у которых наименьшие значения βi
Решение эконометрики в Экселе
Задача 1. Парная регрессия.
Для исходных данных, приведенных ниже, рассчитайте
- коэффициенты линейного регрессионного уравнения
- рассчитайте остаточную дисперсию
- вычислите значения коэффициентов корреляции и детерминации
- рассчитайте коэффициент эластичности
- рассчитайте доверительные границы уравнения регрессии (по уровню 0,95, t=2,44)
- в одной системе координат постройте: уравнение регрессии, экспериментальные точки, доверительные границы уравнения регрессии
Отчет (pdf), Расчеты (xlsx)
Задача 2. Построить требуемое уравнение регрессии. Вычислить коэффициент детерминации, коэффициент эластичности, бета коэффициент и дать их смысловую нагрузку в терминах задачи. Проверить адекватность уравнения с помощью F теста. Найти дисперсии оценок и 95% доверительные интервалы для параметров регрессии. Данные взять из таблицы. Найти прогнозируемое значение объясняемой переменной для некоторого значения объясняющей переменной, не заданной в таблице. Построить уравнение линейной регрессии объема валового выпуска (в млн. руб.) от стоимости основных производственных фондов (млн. руб.).
Отчет (pdf), Расчеты (xlsx)
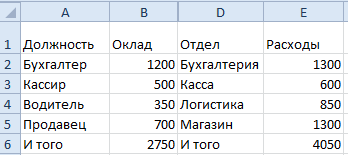
Задача 3. Множественная регрессия.
Построить требуемое уравнение регрессии. Вычислить коэффициент детерминации, частные коэффициенты эластичности, частные бета коэффициенты и дать их смысловую нагрузку в терминах задачи. Проверить адекватность уравнения с помощью F теста. Найти оценку матрицы ковариаций оценок параметров регрессии и 95% доверительные интервалы для параметров регрессии. Проверить наличие мультиколлинеарности в модели. Данные взять из таблицы.
Построить уравнение линейной регрессии себестоимости единицы товара (в сотнях руб.) от величины энерговооруженности (кВт) и производительности труда (тов/час).
Отчет (pdf), Расчеты (xlsx)
Задача 4. Трендовые модели
Проверить ряд на наличие тренда. Сгладить ряд методом простой скользящей средней $(m = 3)$, экспоненциальным сглаживанием $(\alpha = 0,3; \alpha = 0,8)$. Построить исходный и сглаженные ряды. На основании построенных рядов определить вид трендовой модели. Построить трендовую модель.
Сделать прогноз изучаемого признака на два шага вперед.
87; 77; 75; 74; 69; 66; 62; 61; 59; 57; 57; 52; 50; 48; 46; 43; 43; 41; 38; 35
Отчет (pdf), Расчеты (xlsx)
Задача 5.
По заданным статистическим данным постройте линейную модель множественной регрессии и исследуйте её.
- Постройте линейную модель множественной регрессии.
- Запишите стандартизованное уравнение множественной регрессии. На основе стандартизованных коэффициентов регрессии и средних коэффициентов эластичности ранжировать факторы по степени их влияния на результат.
- Найдите коэффициенты парной, частной и множественной корреляции. Проанализируйте их.
- Найдите скорректированный коэффициент множественной детерминации. Сравните его с нескорректированным (общим) коэффициентом детерминации.
- С помощью F-критерия Фишера оценить статистическую надежность уравнения регрессии и коэффициента детерминации $R^2_{y x_1 x_2}$.
- С помощью частных F-критериев Фишера оценить целесообразность включения в уравнение множественной регрессии фактора $x_1$ после $x_2$ и фактора $x_2$ после $x_1$.
- Составьте уравнение линейной парной регрессии, оставив лишь один значащий фактор.
Отчет (pdf), Расчеты (xlsx)
Задача 6. По данным опроса 15 женщин, находящихся в роддоме, исследовать
зависимость веса новорожденного (у) от среднего числа сигарет (х), выкуриваемых матерью в день, с учетом числа уже имеющихся у матери детей (z).
Может пригодиться: примеры решений по эконометрике, лабораторные по статистике в Excel
Заказать решение задач по эконометрике просто
Оценим уже сегодня
Основные задачи и виды регрессии
Регрессия представляет собой зависимость между заданными переменными, за счет чего можно определить прогноз будущего поведения данных переменных. Переменные — это различные периодические явления, включая и поведение человека. Такой анализ программы Excel применяется для того, чтобы проанализировать воздействие на конкретную зависимую переменную значений одной или некоторым количеством переменных.
К примеру, на продажи в магазине влияет несколько факторов, включая ассортимент, цены и место локализации магазина. Благодаря регрессии в Excel можно определять степень влияния каждого из указанных факторов по результатам имеющихся продаж, а после применить полученные данные для прогнозирования продаж на другой месяц или для другого магазина, расположенного рядом.
Обычно регрессия представлена в виде простого уравнения, раскрывающего зависимости и силу связи между двумя группами переменных, где одна группа является зависимой или эндогенной, а другая — независимой или экзогенной. При наличии группы взаимосвязанных показателей зависимая переменная Y определяется исходя из логики рассуждений, а остальные выступают в роли независимых Х-переменных.
Основные задачи построения регрессионной модели заключаются в следующем:
- Отбор значимых независимых переменных (Х1, Х2, …, Xk).
- Выбор вида функции.
- Построение оценок для коэффициентов.
- Построение доверительных интервалов и функции регрессии.
- Проверка значимости вычисленных оценок и построенного уравнения регрессии.
Регрессионный анализ бывает нескольких видов:
- парный (1 зависимая и 1 независимая переменные);
- множественный (несколько независимых переменных).
Уравнения регрессии бывает двух видов:
- Линейные, иллюстрирующие строгую линейную связь между переменными.
- Нелинейные — уравнения, которые могут включать степени, дроби и тригонометрические функции.
Инструкция построения модели
Чтобы выполнить заданное построение в Excel, необходимо следовать указаниям:
Для дальнейшего вычисления следует использоваться функцию «Линейн ()», указывая Значения Y, Значения Х, Конст и статистику. После этого определите множество точек на линии регрессии с помощью функции «Тенденция» — Значения Y, Значения Х, Новые значения, Конст. При помощи заданных параметров вычислите неизвестное значение коэффициентов, опираясь на заданные условия поставленной задачи.
Пакет MS Excel
позволяет при построении уравнения линейной регрессии большую часть работы сделать очень быстро
Важно понять, как интерпретировать полученные результаты.
Для построения модели регрессии необходимо выбрать пункт Сервис\Анализ данных\Регрессия (в Excel 2007
этот режим находится в блоке Данные/Анализ данных/Регрессия). Затем полученные результаты скопировать в блок для анализа.
Линия регрессии является графическим отражением взаимосвязи между явлениями. Очень наглядно можно построить линию регрессии в программе Excel.
Для этого необходимо:
1.Открыть программу Excel
2.Создать столбцы с данными. В нашем примере мы будем строить линию регрессии, или взаимосвязи, между агрессивностью и неуверенностью в себе у детей-первоклассников. В эксперименте участвовали 30 детей, данные представлены в таблице эксель:
1 столбик — № испытуемого
2 столбик — агрессивность
в баллах
3 столбик — неуверенность в себе
в баллах
3.Затем необходимо выделить оба столбика (без названия столбика), нажать вкладку вставка
,
выбрать точечная
, а из предложенных макетов выбрать самый первый точечная с маркерами
.
4.Итак у нас получилась заготовка для линии регрессии — так называемая — диаграмма рассеяния
. Для перехода к линии регрессии нужно щёлкнуть на получившийся рисунок, нажать вкладку конструктор,
найти на панели макеты диаграмм
и выбрать Ма
кет9
, на нем ещё написано f(x)
5.Итак, у нас получилась линия регрессии. На графике также указано её уравнение и квадрат коэффициента корреляции
6.Осталось добавить название графика, название осей. Также по желанию можно убрать легенду, уменьшить количество горизонтальных линий сетки (вкладка макет
, затем сетка
). Основные изменения и настройки производятся во вкладке Макет
Линия регрессии построена в MS Excel. Теперь её можно добавить в текст работы.
Регрессионный анализ — это статистический метод исследования, позволяющий показать зависимость того или иного параметра от одной либо нескольких независимых переменных. В докомпьютерную эру его применение было достаточно затруднительно, особенно если речь шла о больших объемах данных. Сегодня, узнав как построить регрессию в Excel, можно решать сложные статистические задачи буквально за пару минут. Ниже представлены конкретные примеры из области экономики.
Примеры решений онлайн: линейная регрессия
Простая выборка
Пример 1. Имеются данные средней выработки на одного рабочего Y (тыс. руб.) и товарооборота X (тыс. руб.) в 20 магазинах за квартал. На основе указанных данных требуется:
1) определить зависимость (коэффициент корреляции) средней выработки на одного рабочего от товарооборота,
2) составить уравнение прямой регрессии этой зависимости.
Пример 2. С целью анализа взаимного влияния зарплаты и текучести рабочей силы на пяти однотипных фирмах с одинаковым числом работников проведены измерения уровня месячной зарплаты Х и числа уволившихся за год рабочих Y:
X 100 150 200 250 300
Y 60 35 20 20 15
Найти линейную регрессию Y на X, выборочный коэффициент корреляции.
Пример 3. Найти выборочные числовые характеристики и выборочное уравнение линейной регрессии $y_x=ax+b$. Построить прямую регрессии и изобразить на плоскости точки $(x,y)$ из таблицы. Вычислить остаточную дисперсию. Проверить адекватность линейной регрессионной модели по коэффициенту детерминации.
Пример 4. Вычислить коэффициенты уравнения регрессии. Определить выборочный коэффициент корреляции между плотностью древесины маньчжурского ясеня и его прочностью. Решая задачу необходимо построить поле корреляции, по виду поля определить вид зависимости, написать общий вид уравнения регрессии Y на Х, определить коэффициенты уравнения регрессии и вычислить коэффициенты корреляции между двумя заданными величинами.
Пример 5. Компанию по прокату автомобилей интересует зависимость между пробегом автомобилей X и стоимостью ежемесячного технического обслуживания Y. Для выяснения характера этой связи было отобрано 15 автомобилей. Постройте график исходных данных и определите по нему характер зависимости. Рассчитайте выборочный коэффициент линейной корреляции Пирсона, проверьте его значимость при 0,05. Постройте уравнение регрессии и дайте интерпретацию полученных результатов.
Корреляционная таблица
Пример 6. Найти выборочное уравнение прямой регрессии Y на X по заданной корреляционной таблице
Пример 7. В таблице 2 приведены данные зависимости потребления Y (усл. ед.) от дохода X (усл. ед.) для некоторых домашних хозяйств.
1. В предположении, что между X и Y существует линейная зависимость, найдите точечные оценки коэффициентов линейной регрессии.
2. Найдите стандартное отклонение $s$ и коэффициент детерминации $R^2$.
3. В предположении нормальности случайной составляющей регрессионной модели проверьте гипотезу об отсутствии линейной зависимости между Y и X.
4. Каково ожидаемое потребление домашнего хозяйства с доходом $x_n=7$ усл. ед.? Найдите доверительный интервал для прогноза.
Дайте интерпретацию полученных результатов. Уровень значимости во всех случаях считать равным 0,05.
Решение об исследовании зависимости (4 страницы)
Пример 8. Распределение 100 новых видов тарифов на сотовую связь всех известных мобильных систем X (ден. ед.) и выручка от них Y (ден.ед.) приводится в таблице:
Необходимо:
1) Вычислить групповые средние и построить эмпирические линии регрессии;
2) Предполагая, что между переменными X и Y существует линейная корреляционная зависимость:
А) найти уравнения прямых регрессии, построить их графики на одном чертеже с эмпирическими линиями регрессии и дать экономическую интерпретацию полученных уравнений;
Б) вычислить коэффициент корреляции, на уровне значимости 0,05 оценить его значимость и сделать вывод о тесноте и направлении связи между переменными X и Y;
В) используя соответствующее уравнение регрессии, оценить среднюю выручку от мобильных систем с 20 новыми видами тарифов.
Коэффициент корреляции
Пример 9. На основании 18 наблюдений установлено, что на 64% вес X кондитерских изделий зависит от их объема Y. Можно ли на уровне значимости 0,05 утверждать, что между X и Y существует зависимость?
Пример 10. Исследование 27 семей по среднедушевому доходу (Х) и сбережениям (Y) дало результаты: $\overline{X}=82$ у.е., $S_x=31$ у.е., $\overline{Y}=39$ у.е., $S_y=29$ у.е., $\overline{XY} =3709$ (у.е.)2. При $\alpha=0,05$ проверить наличие линейной связи между Х и Y. Определить размер сбережений семей, имеющих среднедушевой доход $Х=130$ у.е.
Нужно решить задачи по на тему регрессия и корреляция?
Оставьте заявку сегодня
Парные (линейные) и частные коэффициенты корреляции
ii1,nxyxy
Парный коэффициент корреляции изменяется в пределах от –1 до +1. Чем ближе он по абсолютной величине к единице, тем ближе статистическая зависимость между x и y к линейной функциональной. Положительное значение коэффициента свидетельствует о том, что связь между признаками прямая (с ростом x увеличивается значение y), отрицательное значение – связь обратная (с ростом x значение y уменьшается).
Можно дать следующую качественную интерпретацию возможных значений коэффициента корреляции: если |r|<0.3 – связь практически отсутствует; 0.3≤ |r| < 0.7 — связь средняя; 0.7≤ |r| < 0.9 – связь сильная; 0.9≤ |r| < 0.99 – связь весьма сильная.
Для оценки мультиколлинеарности факторов используют матрицу парных коэффициентов корреляции зависимого (результативного) признака y с факторными признаками x1, x2,…,xm, которая позволяет оценить степень влияния каждого показателя-фактора xj на зависимую переменную y, а также тесноту взаимосвязей факторов между собой. Корреляционная матрица в общем случае имеет вид
.
Матрица симметрична, на ее диагонали стоят единицы. Если в матрице есть межфакторный коэффициент корреляции rxjxi>0.7, то в данной модели множественной регрессии существует мультиколлинеарность.
Поскольку исходные данные, по которым устанавливается взаимосвязь признаков, являются выборкой из некой генеральной совокупности, вычисленные по этим данным коэффициенты корреляции будут выборочными, т. е. они лишь оценивают связь. Необходима проверка значимости, которая отвечает на вопрос: случайны или нет полученные результаты расчетов.
Значимость парных коэффициентов корреляции проверяют по t-критерию Стьюдента. Выдвигается гипотеза о равенстве нулю генерального коэффициента корреляции: H: ρ = 0. Затем задаются параметры: уровень значимости α и число степеней свободы v = n-2. Используя эти параметры, по таблице критических точек распределения Стьюдента находят tкр, а по имеющимся данным вычисляют наблюдаемое значение критерия:
, (2)
где r – парный коэффициент корреляции, рассчитанный по отобранным для исследования данным. Парный коэффициент корреляции считается значимым (гипотеза о равенстве коэффициента нулю отвергается) с доверительной вероятностью γ = 1- α, если tНабл по модулю будет больше, чем tкрит.
Если переменные коррелируют друг с другом, то на значении коэффициента корреляции частично сказывается влияние других переменных.
Частный коэффициент корреляции характеризует тесноту линейной зависимости между результатом и соответствующим фактором при устранении влияния других факторов. Частный коэффициент корреляции оценивает тесноту связи между двумя переменными при фиксированном значении остальных факторов. Если вычисляется, например, ryx1|x2 (частный коэффициент корреляции между y и x1 при фиксированном влиянии x2), это означает, что определяется количественная мера линейной зависимости между y и x1, которая будет иметь место, если устранить влияние x2 на эти признаки. Если исключают влияние только одного фактора, получают частный коэффициент корреляции первого порядка.
Сравнение значений парного и частного коэффициентов корреляции показывает направление воздействия фиксируемого фактора. Если частный коэффициент корреляции ryx1|x2 получится меньше, чем соответствующий парный коэффициент ryx1, значит, взаимосвязь признаков y и x1 в некоторой степени обусловлена воздействием на них фиксируемой переменной x2. И наоборот, большее значение частного коэффициента по сравнению с парным свидетельствует о том, что фиксируемая переменная x2 ослабляет своим воздействием связь y и x1.
Частный коэффициент корреляции между двумя переменными (y и x2) при исключении влияния одного фактора (x1) можно вычислить по следующей формуле:
. (3)
Для других переменных формулы строятся аналогичным образом. При фиксированном x2; при фиксированном x3.
Значимость частных коэффициентов корреляции проверяется аналогично случаю парных коэффициентов корреляции. Единственным отличием является число степеней свободы, которое следует брать равным v = n – l -2, где l – число фиксируемых факторов.
На основании частных коэффициентов можно сделать вывод об обоснованности включения переменных в регрессионную модель. Если значение коэффициента мало или он незначим, то это означает, что связь между данным фактором и результативной переменной либо очень слаба, либо вовсе отсутствует, поэтому фактор можно исключить из модели.
Корреляционный анализ в Excel
Корреляционный анализ помогает установить, есть ли между показателями в одной или двух выборках связь. Например, между временем работы станка и стоимостью ремонта, ценой техники и продолжительностью эксплуатации, ростом и весом детей и т.д.
Если связь имеется, то влечет ли увеличение одного параметра повышение (положительная корреляция) либо уменьшение (отрицательная) другого. Корреляционный анализ помогает аналитику определиться, можно ли по величине одного показателя предсказать возможное значение другого.
Коэффициент корреляции обозначается r. Варьируется в пределах от +1 до -1. Классификация корреляционных связей для разных сфер будет отличаться. При значении коэффициента 0 линейной зависимости между выборками не существует.
Рассмотрим, как с помощью средств Excel найти коэффициент корреляции.
Для нахождения парных коэффициентов применяется функция КОРРЕЛ.
Задача:
Определить, есть ли взаимосвязь между временем работы токарного станка и стоимостью его обслуживания.
Ставим курсор в любую ячейку и нажимаем кнопку fx.
- В категории «Статистические» выбираем функцию КОРРЕЛ.
- Аргумент «Массив 1» — первый диапазон значений – время работы станка: А2:А14.
- Аргумент «Массив 2» — второй диапазон значений – стоимость ремонта: В2:В14. Жмем ОК.
Чтобы определить тип связи, нужно посмотреть абсолютное число коэффициента (для каждой сферы деятельности есть своя шкала).
Для корреляционного анализа нескольких параметров (более 2) удобнее применять «Анализ данных» (надстройка «Пакет анализа»). В списке нужно выбрать корреляцию и обозначить массив. Все.
Полученные коэффициенты отобразятся в корреляционной матрице. Наподобие такой: