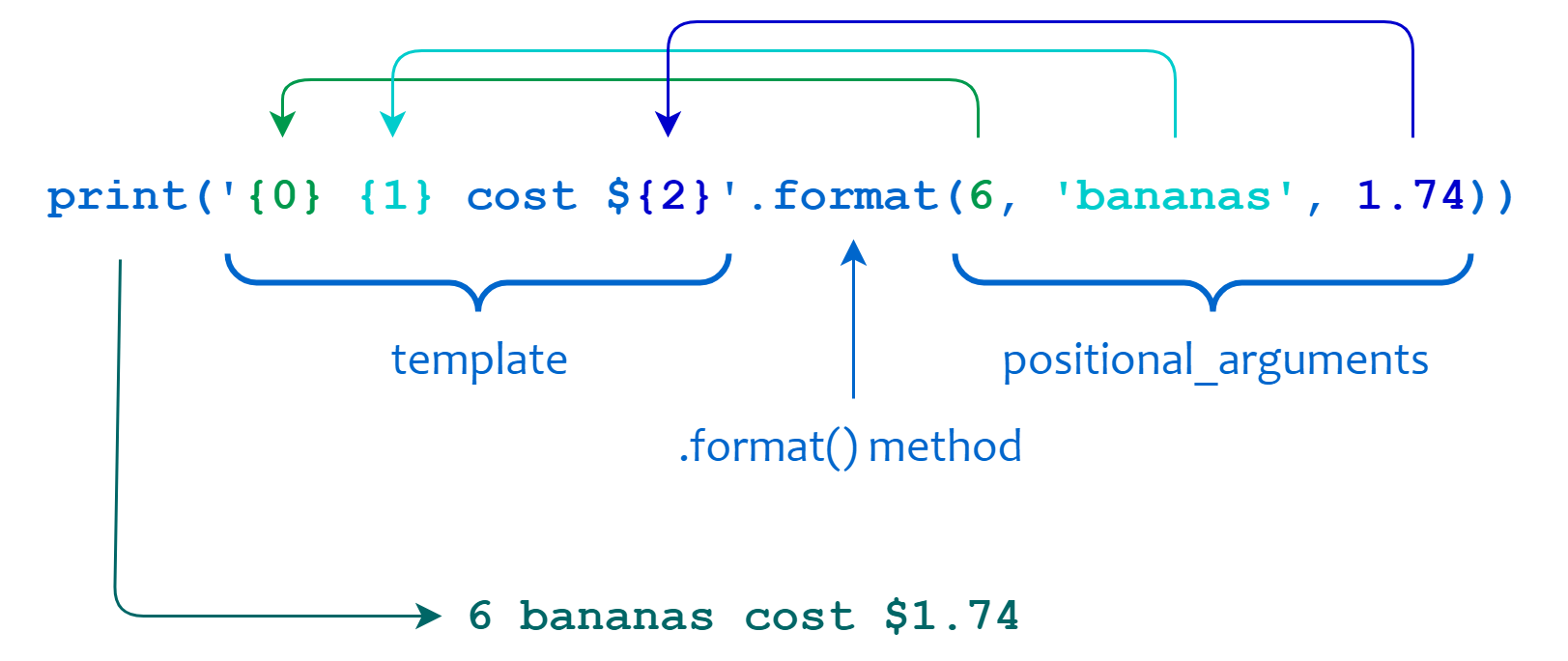
Способы чтения открытого файла в python
Содержание:
- Многопоточность (многозадачность)
- Синтаксис YAML¶
- Открытие и чтение текстового файла
- Добавление изображений
- Стилизация print
- JSON-декодер.
- Функции
- Чтение и запись json-файлов
- File Positions
- Генерация кроссплатформенных путей в Pathlib
- Разделение PDF‑файлов на страницы с помощью PyPDF2
- Ответы на вопросы читателей
- Настройка строк и столбцов
- Запись абзацев
- Использование оператора «with»
- Открытие файла с помощью функции open()
- Функция open() – открытие файла
- Связь с другими языками
- Запись файлов Excel
Многопоточность (многозадачность)
multitasking
multitasking — очень удобная библиотека, которая позволяет только лишь при помощи обертки одним декоратором создавать асинхронные, неблокирующие методы. Эту библиотеку удобно использовать, когда возникает необходимость вызвать в отдельном потоке какой-либо неблокирующий метод, например, при обращении к БД или при ожидании какого-либо ответа от системы, но при этом не очень хочется городить кучу вызовов потоков и т.д..
Достаточно выполнить простую установку: pip install multitasking и далее оборачивать метод декоратором @task
И если удалить @multitasking.task, код выполнится последовательно:
Синтаксис YAML¶
Как и Python, YAML использует отступы для указания структуры документа.
Но в YAML можно использовать только пробелы и нельзя использовать знаки
табуляции.
Еще одна схожесть с Python: комментарии начинаются с символа # и
продолжаются до конца строки.
Список
Список может быть записан в одну строку:
switchport mode access, switchport access vlan, switchport nonegotiate, spanning-tree portfast, spanning-tree bpduguard enable
Или каждый элемент списка в своей строке:
- switchport mode access - switchport access vlan - switchport nonegotiate - spanning-tree portfast - spanning-tree bpduguard enable
Когда список записан таким блоком, каждая строка должна начинаться с
(минуса и пробела), и все строки в списке должны быть на одном
уровне отступа.
Словарь также может быть записан в одну строку:
{ vlan 100, name IT }
Или блоком:
vlan 100 name IT
Строки
Строки в YAML не обязательно брать в кавычки. Это удобно, но иногда всё
же следует использовать кавычки. Например, когда в строке используется
какой-то специальный символ (специальный для YAML).
Такую строку, например, нужно взять в кавычки, чтобы она была корректно
воспринята YAML:
command "sh interface | include Queueing strategy:"
Открытие и чтение текстового файла
Для этого в Питоне имеются следующие конструкции:
- Функция open() – открывает документ в виде файлового объекта;
- Функция close() – закрывает файл и удаляет его из оперативной памяти;
- Контекстный менеджер with (автоматически очищает память после работы с файлом). Его синтаксис показан на рисунке ниже.
Рисунок 1 – Синтаксис контекстного менеджера with
- Метод read() – считывает документ полностью или частично в виде строки;
- Метод readline() – построчно выводит содержимое объекта;
- Метод readlines() – формирует из строк файла список.
В папке проекта создадим текстовый документ «econ.txt» с таким наполнением:
Писать код будем в IDE PyCharm (среду разработки скачиваем с официального сайта).
Пример кода:
Результат выполнения:
Добавление изображений
Чтобы добавить в файлы MS Word изображения, используется метод add_picture(). Путь к изображению передается как параметр метода add_picture(). Также можно указать ширину и высоту изображения с помощью атрибута docx.shared.Inches().
Приведенный ниже скрипт добавляет изображение из локальной файловой системы в файл my_written_file.docx. Ширина и высота изображения будут 5 и 7 дюймов:
mydoc.add_picture("E:/eiffel-tower.jpg", width=docx.shared.Inches(5), height=docx.shared.Inches(7))
mydoc.save("E:/my_written_file.docx")
После выполнения всех скриптов, рассмотренных в этой статье, окончательный файл my_written_file.docx должен выглядеть следующим образом:
Он должен содержать три абзаца, три заголовка и одно изображение.
Стилизация print
icecream
Для форматирования вывода существует одна удобная библиотека под названием icecream. Она помогает упростить написание логов или принтов для отладки. Рассмотрим пример её работы:
Чтобы подключить информацию о том, в каком месте программы происходит вывод, необходимо добавить всего лишь один аргумент в конфигурации модуля:
Это помогает более точно понять в каком месте происходит сбой в работе программы:
Также можно поменять префикс, который добавляется в начале строки, по дефолту он задан “ic|”. Удобно добавить время для вывода, чтобы видеть в какой момент времени и сколько занимал переход от одного принта к другому.
Если у вас уже имеются расставленные принты в коде, то легко можно переприсвоить print на ic:
Рассмотрим пример вывода более сложных структур, например, словарей:
Как видно на скриншоте, то вывод данных в таком формате читать гораздо легче, нежели обычный принт.
Также эта библиотека предоставляет возможность стилизовать вывод в зависимости от предоставляемых данных. Например, если есть необходимость дополнительно оформлять текст ошибки (Exception) или есть желание дополнительно выводить тип данных:
colorama
Еще одна полезная библиотека — colorama, она позволит раскрашивать текст в консоли. Её удобно использовать совместно с библиотекой icecream. Рассмотрим пару примеров:
JSON-декодер.
Синтаксис:
import json
class json.JSONDecoder(*, object_hook=None, parse_float=None,
parse_int=None, parse_constant=None,
strict=True, object_pairs_hook=None)
Параметры:
- — пользовательская функция для преобразования каждого литерала словаря,
- — пользовательская функция для преобразования литералов, похожих на ,
- — пользовательская функция для преобразования литералов, похожих на ,
- — пользовательская функция для преобразования литералов , и ,
- — разрешить/запретить использование управляющих символов,
- — пользовательская функция для преобразования литералов, , декодированных упорядоченным списком пар,
Описание:
Класс модуля представляет из себя простой JSON-декодер.
При десериализации выполняет следующие преобразования:
| JSON | Python |
Класс также понимает , , и как соответствующие значения типа, которые находятся за пределами спецификации JSON.
Аргумент представляет собой пользовательскую функцию и если указана, то будет вызываться с результатом декодирования каждого объекта JSON , а ее возвращаемое значение будет использоваться вместо соответствующего словаря . Это поведение можно использовать для обеспечения настраиваемой десериализации.
Аргумент пользовательская функция и если указана, то будет вызываться с результатом каждого объекта JSON, декодированного упорядоченным списком пар. Возвращаемое значение будет использоваться вместо словаря . Эта функция может быть использована для реализации пользовательских декодеров. Если также определен, то имеет приоритет.
Аргумент — функция и если указана, будет вызываться для каждого значения JSON с плавающей точкой. По умолчанию, это эквивалентно . Можно использовать для преобразования к другому типу данных, например .
Аргумент — функция и если указана, будет вызываться для строки JSON с целым значением . По умолчанию, эквивалентно . Можно использовать для преобразования к другому типу данных, например .
Аргумент — функция и если указана, будет вызываться для строк: , , . Можно использовать для вызова исключений при обнаружении недопустимых чисел в JSON.
Если аргумент ( по умолчанию), тогда использование управляющих символов внутри строк будет разрешено. В данном контексте управляющие символы — это символы с кодами в диапазоне 0–31, включая — tab, , и .
Если десериализованные данные не являются допустимым форматом JSON, будет вызвана ошибка .
Методы класса :
Метод возвращает представление строки , содержащий документ JSON. Если документ JSON не валидный или не действительный, то будет вызвано исключение .
Метод декодирует JSON-документ из строки в формате JSON и возвращает двойной кортеж представление данной строки в Python и индекс в строки , где документ закончился.
Метод может быть использован для декодирования документа JSON из строки, которая в конце содержит посторонние данные.
Примеры использования:
import json
class MyDecoder(json.JSONDecoder):
def __init__(self):
json.JSONDecoder.__init__(self, object_hook=self.dict_to_object)
def dict_to_object(self, d):
if '__module__' in d and '__class__' in d
module_name = d.pop('__module__')
print(f'Подключаем модуль: module = __import__({module_name})')
class_name = d.pop('__class__')
print(f'Далее: class = getattr({module_name}, {class_name})')
args = dict((key.encode('ascii'), value) for key, value in d.items())
print(f'Аргументы класса {class_name}:', args)
print(f'Создаем экземпляр: inst = class(**args)')
else
raise 'Error DATA'
return 'inst'
# например в JSON находятся какие-то настройки
data = '
Функции
Очень часто встречается, что один и тот же кусок кода необходимо использовать в разных местах. Дублирование – плохая практика, ведущая к ошибкам и сложностям изменений. В таких ситуациях на помощь приходят функции.
Ничто не мешает создать свои
Важно учесть и то, что функция всегда что-то возвращает (после ключевого слова return), хоть return и не обязателен (тогда вернется None, т.е. «ничто»)
Структура функции следующая:
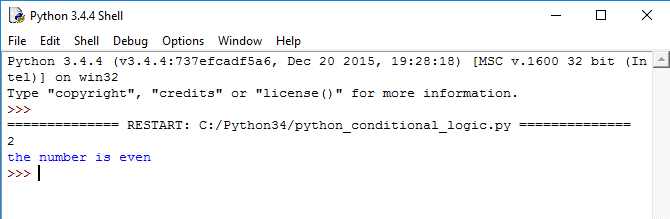
Создадим функцию, которая в зависимости от возраста пользователя будет выводить его статус. Если ему меньше 10 лет – то вернем сообщение «Ребенок», если от 10 до 16 – «Подросток», если от 16 до 20 – «Юноша», если от 20 до 35 – «Молодой человек», если от 35 до 45 – «Мужчина», если от 45 до 55 – «Солидный мужчина», если от 55 до 70 – «Зрелый ум», если от 70 до 120 – «Познавший смыслы». В любом другом случае предупредим пользователя: «Такого возраста не бывает».
Результат работы скрипта:
Теперь в нашей программе можно использовать данную функцию множество раз с разными аргументами.
Чтение и запись json-файлов
Для работы с json-объектами предусмотрен встроенный модуль json. Его нужно импортировать для начала.
Практически все объекты Питона можно безболезненно преобразовывать в json-сущности.
В библиотеке json имеется 4 основные функции (таблица 2).
| Функция | Характеристика |
| dumps() | Преобразовывает объекты Питона в json |
| dump() | Записывает преобразованные в json-формат данные в файл |
| loads() | Преобразовывает json-данные в словарь |
| load() | Считывает содержимое json-файла и делает из них словарь |
Таблица 2 – Ключевые функции модуля json
Так как мы рассматриваем тему создания и чтения файлов, то будем использовать соответствующие инструменты.
Создадим на ПК документ «my.json» с таким содержимым:
Теперь считаем их и представим в виде словаря Python.
Пример кода:
Результат выполнения:
Как видно, десериализация json-данных осуществляется следующим образом:
- Двойные кавычки преобразованы в одинарные;
- Булево значение false превратилось в False;
- Объект null соответствует значению None в Питоне.
А теперь расширим информацию в документе «my.json», добавив еще одного студента.
Пример кода:
Открываем файл в режиме чтения и возможности записи («r+»). Считываем имеющееся в нем содержимое и преобразуем его в словарь. Добавляем новую запись в словарь с ключом «student2». Полностью переписываем содержимое документа с учетом новой информации: делаем отступы (indent=4) для удобства чтения, а также отключаем режим «только ASCII», чтобы появилась возможность вставлять кириллицу.
File Positions
The tell() method tells you the current position within the file; in other words, the next read or write will occur at that many bytes from the beginning of the file.
The seek(offset) method changes the current file position. The offset argument indicates the number of bytes to be moved. The from argument specifies the reference position from where the bytes are to be moved.
If from is set to 0, it means use the beginning of the file as the reference position and 1 means use the current position as the reference position and if it is set to 2 then the end of the file would be taken as the reference position.
Example
Let us take a file foo.txt, which we created above.
#!/usr/bin/python
# Open a file
fo = open("foo.txt", "r+")
str = fo.read(10)
print "Read String is : ", str
# Check current position
position = fo.tell()
print "Current file position : ", position
# Reposition pointer at the beginning once again
position = fo.seek(0, 0);
str = fo.read(10)
print "Again read String is : ", str
# Close opend file
fo.close()
This produces the following result −
Read String is : Python is Current file position : 10 Again read String is : Python is
Генерация кроссплатформенных путей в Pathlib
Пути используют разные соглашения в разных операционных системах. Windows использует обратный слеш между названиями папок, тогда как все другие популярные операционные системы используют прямой слеш .
Если вы хотите, чтобы ваш код работал, независимо от базовой ОС, вам нужно будет обрабатывать различные соглашения, характерные для базовой платформы. Модуль Pathlib упрощает работу с путями к файлам. В Pathlib можно просто передать путь или название файла объекту , используя слеш, независимо от ОС. Pathlib занимается всем остальным.
Python
pathlib.Path.home() / ‘python’ / ‘samples’ / ‘test_me.py’
| 1 | pathlib.Path.home()’python»samples»test_me.py’ |
Объект конвертирует в слеш соответствующий операционной системе. может представлять путь Windows или Posix. Кроме того, Pathlib решает многие кросс-функциональные баги, легко обрабатывая пути.
Разделение PDF‑файлов на страницы с помощью PyPDF2
Для этого примера, в первую очередь необходимо импортировать классы и . Затем мы открываем файл PDF, создаем объект для чтения и перебираем все страницы, используя метод объекта для чтения .
Внутри цикла мы создаем новый экземпляр , который еще не содержит страниц. Затем мы добавляем текущую страницу к нашему объекту записи, используя метод . Этот метод принимает объект страницы, который мы получаем, используя метод .
Следующим шагом является создание уникального имени файла, что мы делаем, используя исходное имя файла плюс слово «page» плюс номер страницы. Мы добавляем 1 к текущему номеру страницы, потому что PyPDF2 считает номера страниц, начиная с нуля.
Наконец, мы открываем новое имя файла в режиме (режиме ) записи двоичного файла и используем метод класса для сохранения извлеченной страницы на диск.
Листинг 4: Разделение PDF на отдельные страницы.
from PyPDF2 import PdfFileReader, PdfFileWriter
pdf_document = "source/Computer-Vision-Resources.pdf"
pdf = PdfFileReader(pdf_document)
for page in range(pdf.getNumPages()):
pdf_writer = PdfFileWriter()
current_page = pdf.getPage(page)
pdf_writer.addPage(current_page)
outputFilename = "dist/Computer-Vision-Resources-page-{}.pdf".format(page + 1)
with open(outputFilename, "wb") as out:
pdf_writer.write(out)
print("created", outputFilename)
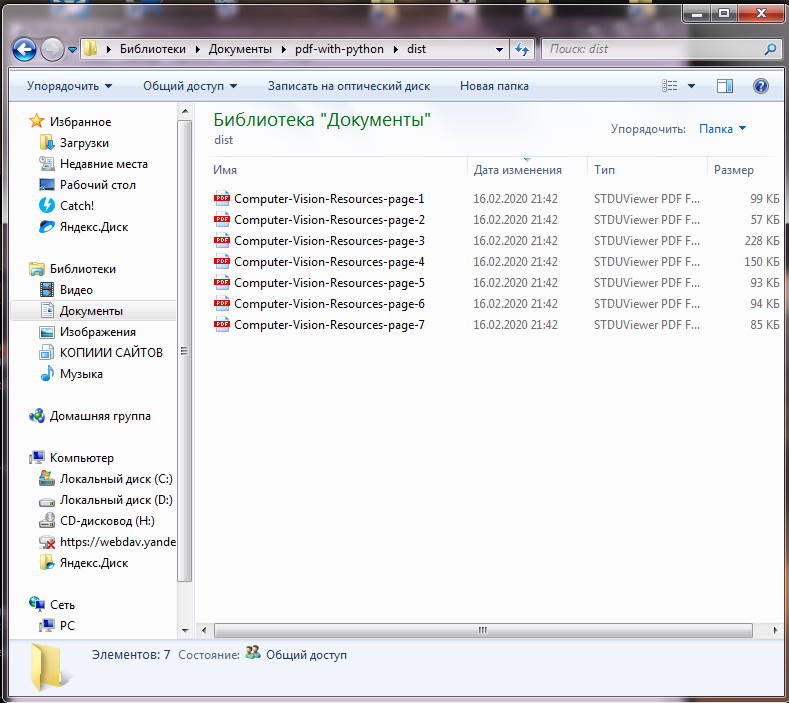 Разделили исходный файл на страницы
Разделили исходный файл на страницы
Ответы на вопросы читателей
Сколько времени потребуется на изучение Питона? При постоянной практике и достаточном ежедневном внимании к языку Python основам синтаксиса и базовым операциям можно научиться за 1-2 месяца. Уверенное владение базовыми библиотеками, популярными сторонними модулями, объектно-ориентированном подходе может потребовать от 3 до 6 месяцев. Нужно осознавать и то, что для каждого обучаемого сроки индивидуальны.
Как работать с текстовыми файлами в Питоне? Взаимодействие с текстовыми файлами связано с функциями open(), close(), read(), readlines(), контекстным менеджером with и рядом других. Эти инструменты позволяют как читать документы, так и осуществлять в них запись.
Как работать с таблицами в языке Python? Универсальный формат табличной информации – csv (Comma Separated Values, разделенные запятой данные). Его хорошо понимают разные сайты, среды разработки, операционные системы. Чтобы взаимодействовать с excel-файлами требуется установить модуль openpyxl. Для работы с Гугл-таблицами нужно получить доступ к программному интерфейсу в качестве разработчика.
Что такое json-формат данных? Информация на Интернет-ресурсах зачастую представлена в виде json-данных. Она очень напоминает словари (dictionaries) в Питоне. Именно поэтому работать с этим форматом очень удобно. Он используется для передачи и получения информации между API сайтов и программ.
Какой модуль используется для взаимодействия с файлами операционной системы? Встроенная библиотека os позволяет работать с каталогами и файлами операционной системы. Возможности не ограничены конкретной «операционкой» и в большинстве случаев универсальны. Набор инструментария следующий: представление списка документов конкретной папки, создание папок, удаление каталогов и документов, переименование файлов и др.
Как представить текстовый файл в виде строки? После создания файлового объекта его можно прочитать полностью и вывести на печать. Пример кода: — with open(‘myfile.txt’, ‘r’, encoding=’utf-8′) as doc: print(doc.read()) — Файл «myfile.txt» открыт в режиме чтения и будет выведен в консоль со всем своим содержимым.
Как создать pdf-файл в Питоне? В зависимости от исходных данных pdf-документы могут создаваться при помощи разных инструментов: Pillow (когда входная информация в основной своей массе графическая), PyPDF2 (объединение файлов, кодирование-декодирование), fpdf (преобразование текста в pdf-формат) и пр.
Как обрабатывать изображения при помощи языка Python? Один из самых часто применяемых инструментов – библиотека Pillow. Позволяет решать задачи: извлекать сведения о картинке; менять размеры, обрезать, поворачивать; накладывать фильтры на рисунки (размытие, повышение контраста и др.); добавлять текстовые надписи; создавать изображения.
Настройка строк и столбцов
С помощью модуля OpenPyXL можно задавать высоту строк и ширину столбцов таблицы, закреплять их на месте (чтобы они всегда были видны на экране), полностью скрывать из виду, объединять ячейки.
Настройка высоты строк и ширины столбцов
Объекты имеют атрибуты и , которые управляют высотой строк и шириной столбцов.
sheet'A1' = 'Высокая строка' sheet'B2' = 'Широкий столбец' sheet.row_dimensions1.height = 70 sheet.column_dimensions'B'.width = 30
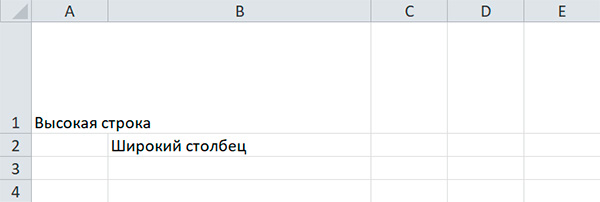
Атрибуты s и представляют собой значения, подобные словарю. Атрибут содержит объекты , а атрибут содержит объекты . Доступ к объектам в осуществляется с использованием номера строки, а доступ к объектам в — с использованием буквы столбца.
Для указания высоты строки разрешено использовать целые или вещественные числа в диапазоне от 0 до 409. Для указания ширины столбца можно использовать целые или вещественные числа в диапазоне от 0 до 255. Столбцы с нулевой шириной и строки с нулевой высотой невидимы для пользователя.
Объединение ячеек
Ячейки, занимающие прямоугольную область, могут быть объединены в одну ячейку с помощью метода рабочего листа:
sheet.merge_cells('A1:D3')
sheet'A1' = 'Объединены двенадцать ячеек'
sheet.merge_cells('C5:E5')
sheet'C5' = 'Объединены три ячейки'

Чтобы отменить слияние ячеек, надо вызвать метод :
sheet.unmerge_cells('A1:D3')
sheet.unmerge_cells('C5:E5')
Закрепление областей
Если размер таблицы настолько велик, что ее нельзя увидеть целиком, можно заблокировать несколько верхних строк или крайних слева столбцов в их позициях на экране. В этом случае пользователь всегда будет видеть заблокированные заголовки столбцов или строк, даже если он прокручивает таблицу на экране.
У объекта имеется атрибут , значением которого может служить объект или строка с координатами ячеек. Все строки и столбцы, расположенные выше и левее, будут заблокированы.
| Значение атрибута freeze_panes | Заблокированные строки и столбцы |
|---|---|
| Строка 1 | |
| Столбец A | |
| Столбцы A и B | |
| Строка 1 и столбцы A и B | |
| Закрепленные области отсутствуют |
Запись абзацев
Для записи абзацев используйте метод add_paragraph() объекта класса Document. После добавления абзаца нужно вызвать метод save(). Путь к файлу, в который нужно записать абзац, передается в качестве параметра методу save(). Если файл не существует, то будет создан новый файл. Иначе абзац будет добавлен в конец существующего файла MS Word.
Приведенный ниже скрипт записывает простой абзац во вновь созданный файл my_written_file.docx.
mydoc.add_paragraph("This is first paragraph of a MS Word file.")
mydoc.save("E:/my_written_file.docx")
После выполнения этого скрипта вы должны увидеть новый файл my_written_file.docx в каталоге, который указали в методе save(). Внутри файла должен быть один абзац, который гласит: «This is first paragraph of a MS Word file.».
Добавим в файл my_written_file.docx еще один абзац:
mydoc.add_paragraph("This is the second paragraph of a MS Word file.")
mydoc.save("E:/my_written_file.docx")
Этот абзац будет добавлен в конец файла my_written_file.docx.
Использование оператора «with»
В Python имеется аккуратно встроенный инструмент, применяя который вы можете заметно упростить чтение и редактирование файлов. Оператор with создает диспетчер контекста в Пайтоне, который автоматически закрывает файл для вас, по окончанию работы в нем. Посмотрим, как это работает:
Python
with open(«test.txt») as file_handler:
for line in file_handler:
print(line)
|
1 2 3 |
withopen(«test.txt»)asfile_handler forline infile_handler print(line) |
Синтаксис для оператора with, на первый взгляд, кажется слегка необычным, однако это вопрос недолгой практики. Фактически, все, что мы делаем в данном примере, это:
Python
handle = open(«test.txt»)
| 1 | handle=open(«test.txt») |
Меняем на это:
Python
with open(«test.txt») as file_handler:
| 1 | withopen(«test.txt»)asfile_handler |
Вы можете выполнять все стандартные операции ввода\вывода, в привычном порядке, пока находитесь в пределах блока кода. После того, как вы покинете блок кода, файловый дескриптор закроет его, и его уже нельзя будет использовать. И да, вы все прочли правильно. Вам не нужно лично закрывать дескриптор файла, так как оператор делает это автоматически. Попробуйте внести изменения в примеры, указанные выше, используя оператор with.
Открытие файла с помощью функции open()
Первый шаг к работе с файлами в Python – научиться открывать файл. Вы можете открывать файлы с помощью метода open().
Функция open() в Python принимает два аргумента. Первый – это имя файла с полным путем, а второй – режим открытия файла.
Ниже перечислены некоторые из распространенных режимов чтения файлов:
- ‘r’ – этот режим указывает, что файл будет открыт только для чтения;
- ‘w’ – этот режим указывает, что файл будет открыт только для записи. Если файл, содержащий это имя, не существует, он создаст новый;
- ‘a’ – этот режим указывает, что вывод этой программы будет добавлен к предыдущему выводу этого файла;
- ‘r +’ – этот режим указывает, что файл будет открыт как для чтения, так и для записи.
Кроме того, для операционной системы Windows вы можете добавить «b» для доступа к файлу в двоичном формате. Это связано с тем, что Windows различает двоичный текстовый файл и обычный текстовый файл.
Предположим, мы помещаем текстовый файл с именем file.txt в тот же каталог, где находится наш код. Теперь мы хотим открыть этот файл.
Однако функция open (filename, mode) возвращает файловый объект. С этим файловым объектом вы можете продолжить свою дальнейшую работу.
#directory: /home/imtiaz/code.py
text_file = open('file.txt','r')
#Another method using full location
text_file2 = open('/home/imtiaz/file.txt','r')
print('First Method')
print(text_file)
print('Second Method')
print(text_file2)
Результатом следующего кода будет:
================== RESTART: /home/imtiaz/code.py ================== First Method Second Method >>>
Функция open() – открытие файла
Открытие файла выполняется с помощью встроенной в Python функции . Обычно ей передают один или два аргумента. Первый – имя файла или имя с адресом, если файл находится не в том каталоге, где находится скрипт. Второй аргумент – режим, в котором открывается файл.
Обычно используются режимы чтения () и записи (). Если файл открыт в режиме чтения, то запись в него невозможна. Можно только считывать данные из него. Если файл открыт в режиме записи, то в него можно только записывать данные, считывать нельзя.
Если файл открывается в режиме , то все данные, которые в нем были до этого, стираются. Файл становится пустым. Если не надо удалять существующие в файле данные, тогда следует использовать вместо режима записи, режим дозаписи ().
Если файл отсутствует, то открытие его в режиме создаст новый файл. Бывают ситуации, когда надо гарантировано создать новый файл, избежав случайной перезаписи данных существующего. В этом случае вместо режима используется режим . В нем всегда создается новый файл для записи. Если указано имя существующего файла, то будет выброшено исключение. Потери данных в уже имеющемся файле не произойдет.
Если при вызове второй аргумент не указан, то файл открывается в режиме чтения как текстовый файл. Чтобы открыть файл как байтовый, дополнительно к букве режима чтения/записи добавляется символ . Буква обозначает текстовый файл. Поскольку это тип файла по умолчанию, то обычно ее не указывают.
Нельзя указывать только тип файла, то есть есть ошибка, даже если файл открывается на чтение. Правильно – . Только текстовые файлы мы можем открыть командой , потому что и и подразумеваются по-умолчанию.
Функция возвращает объект файлового типа. Его надо либо сразу связать с переменной, чтобы не потерять, либо сразу прочитать.
Связь с другими языками
pythonnet
Иногда возникает потребность запустить код, написанный на другом языке, через Python, например, в целях проверки работы какого-либо стороннего модуля или для оптимизации кода. Существует несколько библиотек, позволяющих сделать это, например, pythonnet позволяет запустить некоторую часть кода, написанную на C# в Python (pythonnet позволяет рассматривать множество элементов clr, как модули в python).
Создаем проект библиотеки классов C# в visual studio, создаем в неё нужный класс или методы (в случае примера класс, содержащий метод вычисления дискриминанта), создаем .dll и запускаем через pythonnet (более подробно тут):
Обращаемся к C# через Python
JPype
Для этих же целей существует библиотека, которая позволяет запустить Java код в Python. Эта библиотека называется — JPype. Рассмотрим пример работы библиотеки.
Для начала установим её pip install jpype1, далее создадим Java проект, который в будущем скомпилируем в .jar архив, в проекте необходимо создать пакет, в нём класс и прописать следующий код (код вычисляет объем цилиндра):
Теперь можно создать .jar решение проекта.
В python коде импортируем библиотеку jpype, запустим JVM и пропишем путь к созданному .jar архиву. Далее по аналогии с pythonnet импортируем необходимые пакеты и классы:
Таким образом, pythonnet и jpype — отличные решения для интеграции кода C# и Java в Python проект.
Запись файлов Excel
>>> import openpyxl
>>> wb = openpyxl.Workbook()
>>> wb.sheetnames
>>> wb.create_sheet(title = 'Первый лист', index = 0)
<Worksheet "Первый лист">
>>> wb.sheetnames
>>> wb.remove(wb)
>>> wb.sheetnames
>>> wb.save('example.xlsx')
Метод возвращает новый объект , который по умолчанию становится последним листом книги. С помощью именованных аргументов и можно задать имя и индекс нового листа.
Метод принимает в качестве аргумента не строку с именем листа, а объект . Если известно только имя листа, который надо удалить, используйте . Еще один способ удалить лист — использовать инструкцию .
Не забудьте вызвать метод , чтобы сохранить изменения после добавления или удаления листа рабочей книги.
Запись значений в ячейки напоминает запись значений в ключи словаря:
>>> import openpyxl >>> wb = openpyxl.Workbook() >>> wb.create_sheet(title = 'Первый лист', index = 0) >>> sheet = wb >>> sheet = 'Здравствуй, мир!' >>> sheet.value 'Здравствуй, мир!'
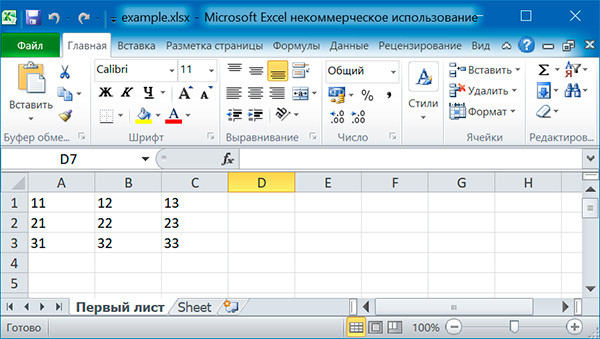
Заполняем таблицу 3×3:
import openpyxl
# создаем новый excel-файл
wb = openpyxl.Workbook()
# добавляем новый лист
wb.create_sheet(title = 'Первый лист', index = )
# получаем лист, с которым будем работать
sheet = wb'Первый лист'
for row in range(1, 4)
for col in range(1, 4)
value = str(row) + str(col)
cell = sheet.cell(row = row, column = col)
cell.value = value
wb.save('example.xlsx')
Можно добавлять строки целиком:
sheet.append('Первый', 'Второй', 'Третий')
sheet.append('Четвертый', 'Пятый', 'Шестой')
sheet.append('Седьмой', 'Восьмой', 'Девятый')