Python урок 5. немного о строках. срезы
Содержание:
Введение
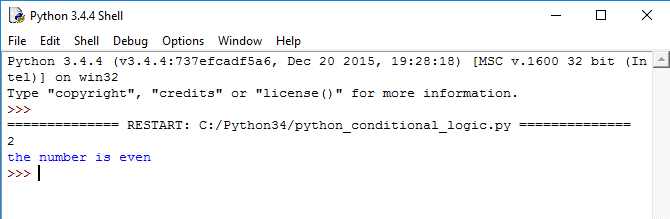
Строки (strings) в Python представляют собой последовательности из одного или более знаков (букв, цифр, символов). И хотя мы можем использовать эту последовательность в каких-то операциях, сама она является неизменной. То есть строку нельзя изменить, не создав при этом другой объект, занимающий иной адрес в памяти.
Благодаря широкому распространению текста в повседневной жизни, строка является важным типом данных, присутствующим в мире программирования.
В этом руководстве мы рассмотрим, как создавать и выводить на экран строки, как их объединять и повторять, а также, как устанавливать в качестве значения для переменных.
String Format
As we learned in the Python Variables chapter, we cannot combine strings and numbers like this:
Example
age = 36txt = «My name is John, I am » + ageprint(txt)
But we can combine strings and numbers by using the method!
The method takes the passed arguments,
formats them, and places them in the string where the placeholders
are:
Example
Use the method to insert numbers
into strings:
age = 36txt = «My name is John, and I am {}»print(txt.format(age))
The format() method takes unlimited number of arguments, and are placed into
the respective placeholders:
Example
quantity = 3itemno = 567price = 49.95myorder = «I want {}
pieces of item {} for {} dollars.»print(myorder.format(quantity,
itemno, price))
You can use index numbers to be sure the arguments are placed
in the correct placeholders:
Example
quantity = 3itemno = 567price = 49.95myorder = «I want to pay {2}
dollars for {0} pieces of item {1}.»print(myorder.format(quantity,
itemno, price))
Learn more about String Formatting in our String Formatting chapter.
❮ Previous
Next ❯
Основные строковые функции
| capitalize() | Преобразует первый символ строки в верхний регистр | str_name.capitalize() |
| casefold() | Он преобразует любую строку в нижний регистр независимо от ее регистра | str_name.casefold() |
| center() | Используется для выравнивания строки по центру | str_name.center (длина, символ) |
| count() | Для подсчета количества раз, когда определенное значение появляется в строке. | str_name.count (значение, начало, конец) |
| endswith() | Проверяет, заканчивается ли строка указанным значением, затем возвращает True | str_name.endswith (значение, начало, конец) |
| find() | Используется для определения наличия указанного значения в строке | str_name.find (значение, начало, конец) |
| index() | Он используется для поиска первого вхождения указанного значения в строке | str_name.index (значение, начало, конец) |
| isalnum() | Проверяет, все ли символы являются буквенно-цифровыми, затем возвращает True | str_name.isalnum() |
| isalpha() | Проверяет, все ли символы являются алфавитными (az), затем возвращает True | str_name.isalpha() |
| isdecimal() | Проверяет, все ли символы являются десятичными (0-9), затем возвращает True | str_name.isdecimal() |
| isdigit() | Проверяет, все ли символы являются цифрами, затем возвращает True | str_name.isdigit() |
| islower() | Проверяет, все ли символы в нижнем регистре, затем возвращает True | str_name.islower() |
| isnumeric() | Проверяет, все ли символы являются числовыми (0-9), затем возвращает True | str_name.isnumeric() |
| isspace() | Проверяет, все ли символы являются пробелами, затем возвращает True | str_name.isspace() |
| isupper() | Проверяет, все ли символы в верхнем регистре, затем возвращает True | str_name.isupper() |
| lower() | Используется для преобразования всех символов в нижний регистр | str_name.lower() |
| partition() | Используется для разделения строки на кортеж из трех элементов. | str_name.partition (значение) |
| replace() | Используется для замены указанного слова или фразы другим словом или фразой в строке. | str_name.replace (старое значение, новое значение, количество) |
| split() | Используется для разделения строки на список | str_name.split (разделитель, maxsplit) |
| splitlines() | Используется для разделения строки и составления ее списка. Разбивается на разрыв строки. | str_name.splitlines (keeplinebreaks) |
| startswith() | Проверяет, начинается ли строка с указанного значения, затем возвращает True | str_name.startswith (значение, начало, конец) |
| strip() | Используется для удаления символов, указанных в аргументе, с обоих концов | str_name.strip (символы) |
| swapcase() | Используется для замены строки верхнего регистра на нижний регистр или наоборот. | str_name.swapcase() |
| title() | Преобразует начальную букву каждого слова в верхний регистр | str_name.title() |
| upper() | Он используется для преобразования всех символов в строке в верхний регистр | str_name.upper() |
Вводная информация о строках
Как и во многих других языках программирования, в Python есть большая коллекция функций, операторов и методов, позволяющих работать со строковым типом.
Литералы строк
Литерал – способ создания объектов, в случае строк Питон предлагает несколько основных вариантов:
Если внутри строки необходимо расположить двойные кавычки, и сама строка была создана с помощью двойных кавычек, можно сделать следующее:
Разницы между строками с одинарными и двойными кавычками нет – это одно и то же
Какие кавычки использовать – решать вам, соглашение PEP 8 не дает рекомендаций по использованию кавычек. Просто выберите один тип кавычек и придерживайтесь его. Однако если в стоке используются те же кавычки, что и в литерале строки, используйте разные типы кавычек – обратная косая черта в строке ухудшает читаемость кода.
Кодировка строк
В третьей версии языка программирования Python все строки представляют собой последовательность Unicode-символов.
В Python 3 кодировка по умолчанию исходного кода – UTF-8. Во второй версии по умолчанию использовалась ASCII. Если необходимо использовать другую кодировку, можно разместить специальное объявление на первой строке файла, к примеру:
Максимальная длина строки в Python
Максимальная длина строки зависит от платформы. Обычно это:
- 2**31 — 1 – для 32-битной платформы;
- 2**63 — 1 – для 64-битной платформы;
Константа , определенная в модуле
Конкатенация строк
Одна из самых распространенных операций со строками – их объединение (конкатенация). Для этого используется знак , в результате к концу первой строки будет дописана вторая:
При необходимости объединения строки с числом его предварительно нужно привести тоже к строке, используя функцию
Сравнение строк
При сравнении нескольких строк рассматриваются отдельные символы и их регистр:
- цифра условно меньше, чем любая буква из алфавита;
- алфавитная буква в верхнем регистре меньше, чем буква в нижнем регистре;
- чем раньше буква в алфавите, тем она меньше;
При этом сравниваются по очереди первые символы, затем – 2-е и так далее.
Далеко не всегда желательной является зависимость от регистра, в таком случае можно привести обе строки к одному и тому же регистру. Для этого используются функции – для приведения к нижнему и – к верхнему:
Как удалить строку в Python
Строки, как и некоторые другие типы данных в языке Python, являются неизменяемыми объектами. При задании нового значения строке просто создается новая, с заданным значением. Для удаления строки можно воспользоваться методом , заменив ее на пустую строку:
Или перезаписать переменную пустой строкой:
Обращение по индексу
Для выбора определенного символа из строки можно воспользоваться обращением по индексу, записав его в квадратных скобках:
Индекс начинается с 0
В Python предусмотрена возможность получить доступ и по отрицательному индексу. В таком случае отсчет будет вестись от конца строки:
Как создать строку
Строки всегда создаются одним из трех способов. Вы можете использовать одинарные, двойные и тройные скобки. Давайте посмотрим
Python
my_string = «Добро пожаловать в Python!»
another_string = ‘Я новый текст тут…’
a_long_string = »’А это у нас
новая строка
в троичных скобках»’
|
1 2 3 4 5 6 |
my_string=»Добро пожаловать в Python!» another_string=’Я новый текст тут…’ a_long_string=»’А это у нас новая строка |
Строка с тремя скобками может быть создана с использованием трех одинарных скобок или трех двойных скобок. Так или иначе, с их помощью программист может писать строки в нескольких линиях. Если вы впишете это, вы увидите, что выдача сохраняет разрыв строк. Если вам нужно использовать одинарные скобки в вашей строке, то впишите двойные скобки. Давайте посмотрим на пример:
Python
my_string = «I’m a Python programmer!»
otherString = ‘Слово «Python» обычно подразумевает змею’
tripleString = «»»В такой «строке» мы можем ‘использовать’ все.»»»
|
1 2 3 |
my_string=»I’m a Python programmer!» otherString=’Слово «Python» обычно подразумевает змею’ tripleString=»»»В такой «строке» мы можем ‘использовать’ все.»»» |
Данный код демонстрирует то, как вы можете вписать одинарные или двойные скобки в строку. Существует еще один способ создания строки, при помощи метода str. Как это работает:
Python
my_number = 123
my_string = str(my_number)
|
1 2 |
my_number=123 my_string=str(my_number) |
Если вы впишете данный код в ваш интерпретатор, вы увидите, что вы изменили значение интегратора на строку и присвоили ее переменной my_string. Это называется кастинг, или конвертирование. Вы можете конвертировать некоторые типы данных в другие, например числа в строки. Но вы также заметите, что вы не всегда можете делать обратное, например, конвертировать строку вроде ‘ABC’ в целое число. Если вы сделаете это, то получите ошибку вроде той, что указана в этом примере:
Python
int(‘ABC’)
Traceback (most recent call last):
File «<string>», line 1, in <fragment>
ValueError: invalid literal for int() with base 10: ‘ABC’
|
1 2 3 4 5 |
int(‘ABC’) Traceback(most recent call last) File»<string>»,line1,in<fragment> ValueErrorinvalid literal forint()withbase10’ABC’ |
Мы рассмотрели обработку исключений в другой статье, но как вы могли догадаться из сообщения, это значит, что вы не можете конвертировать сроки в цифры. Тем не менее, если вы вписали:
Python
x = int(«123»)
| 1 | x=int(«123») |
То все должно работать
Обратите внимание на то, что строка – это один из неизменных типов Python. Это значит, что вы не можете менять содержимое строки после ее создания
Давайте попробуем сделать это и посмотрим, что получится:
Python
my_string = «abc»
my_string = «d»
Traceback (most recent call last):
File «<string>», line 1, in <fragment>
TypeError: ‘str’ object does not support item assignment
|
1 2 3 4 5 6 |
my_string=»abc» my_string=»d» Traceback(most recent call last) File»<string>»,line1,in<fragment> TypeError’str’objectdoes notsupport item assignment |
Здесь мы пытаемся изменить первую букву с «а» на «d«, в итоге это привело к ошибке TypeError, которая не дает нам сделать это. Теперь вы можете подумать, что присвоение новой строке то же значение и есть изменение строки. Давайте взглянем, правда ли это:
Python
my_string = «abc»
a = id(my_string)
print(a) # 19397208
my_string = «def»
b = id(my_string)
print(b) # 25558288
my_string = my_string + «ghi»
c = id(my_string)
print(c) # 31345312
|
1 2 3 4 5 6 7 8 9 10 11 |
my_string=»abc» a=id(my_string) print(a)# 19397208 my_string=»def» b=id(my_string) print(b)# 25558288 my_string=my_string+»ghi» c=id(my_string) print(c)# 31345312 |
Проверив id объекта, мы можем определить, что когда мы присваиваем новое значение переменной, то это меняет тождество
Обратите внимание, что в версии Python, начиная с 2.0, строки могут содержать только символы ASCII. Если вам нужен Unicode, тогда вы должны вписывать u перед вашей строкой
Пример:
Python
# -*- coding: utf-8 -*-
my_unicode_string = u»Это юникод!»
|
1 2 |
# -*- coding: utf-8 -*- my_unicode_string=u»Это юникод!» |
В Python, начиная с версии 3, все строки являются юникодом.
Строки нарезки в Python – примеры
Струны нарезки Python могут быть сделаны по-разному.
Обычно мы получаем доступ к строковым элементам (символам) с помощью простой индексации, которая начинается с до N-1 (n – длина строки). Следовательно, для доступа к 1-й Элемент строки Мы можем просто использовать код ниже.
s1 = String1
Опять же, есть еще один способ получить доступ к этим персонажам, то есть используя Отрицательная индексация Отказ Отрицательная индексация начинается с -1 к -n (n – длина для данной строки). Примечание, отрицательная индексация выполняется с другого конца строки. Следовательно, для доступа к первому символу на этот раз нам нужно следовать указанному ниже коду.
s1 = String1
Теперь давайте рассмотрим некоторые способы, следующие, которые мы можем нарезать строку, используя вышеуказанную концепцию.
1. Строки нарезки в Python с началом и концом
Мы можем легко нарезать данную строку, упомянувая начальные и окончательные индексы для желаемой подковы, которую мы ищем. Посмотрите на приведенный ниже пример, он объясняет нарезку строк, используя начальные и окончательные индексы для обычной, так и для негативного метода индексации.
#string slicing with two parameters
s = "Hello World!"
res1 = s
res2 = s #using negative indexing
print("Result1 = ",res1)
print("Result2 = ",res2)
Выход :
Result1 = llo Wo Result2 = rld
Здесь,
- Мы инициализируем строку, как “Привет мир!” ,
- Сначала мы нарезаем данную строку с начальным индексом 2 и окончание индекса как 8 Отказ Это означает, что результирующая подконта будет содержать символы из S к S ,
- Аналогично, для следующего, результирующая подкора должна содержать символы из S к S Отказ
Следовательно, наш выход оправдан.
2. Струки срез, используя только начало или конец
Как упоминалось ранее, все три параметра для нарезки строки являются необязательными. Следовательно, мы можем легко выполнить наши задачи с использованием одного параметра. Посмотрите на код ниже, чтобы получить четкое понимание.
#string slicing with one parameter
s1= "Charlie"
s2="Jordan"
res1 = s1 #default value of ending position is set to the length of string
res2 = s2 #default value of starting position is set to 0
print("Result1 = ",res1)
print("Result2 = ",res2)
Выход :
Result1 = arlie Result2 = Jord
Здесь,
Сначала инициализируем две строки, S1 и S2 , Для нарезки их обоих мы просто упомяну о start_pos Для S1 и End_Pos только для S2, Следовательно, для RES1 , он содержит подконтную строку S1 из индекса 2 (как упоминалось) до последнего (по умолчанию он устанавливается на N-1)
Принимая во внимание, что для RES2 диапазон индексов лежит от 0 до 4 (упомянутых).
3. Строки нарезки в Python со ступенчатым параметром
Значение решает прыжок операции нарезки займет из одного индекса к другому. Посмотрите на пример ниже.
#string slicing with step parameter
s= "Python"
s1="Kotlin"
res = s
res1 = s1 #using negative parameters
print("Resultant sliced string = ",res)
print("Resultant sliced string(negative parameters) = ",res1)
Выход :
Resultant sliced string = Pto Resultant sliced string(negative parameters) = nl
В коде выше,
- Мы инициализируем две строки S и S1 и попытайтесь нарезать их за данные начальные и окончательные индексы, как мы сделали для нашего первого примера,
- Но на этот раз мы упомянули шаг значение, которое было установлено на 1 по умолчанию для предыдущих примеров,
- Для RES, имеющих размер шага 2 означает, что, в то время как прохождение для получения подстроки от индекса от 0 до 4, каждый раз, когда индекс будет увеличен по значению 2. То есть первый символ S («P») следующие символы в подпологе будут S и S до тех пор, пока индекс не будет меньше 5.
- Для следующего я. RES1 Упомянутый шаг (-2). Следовательно, похоже на предыдущий случай, персонажи в подстроке будут S1 Тогда S1 или S1 до тех пор, пока индекс не будет меньше (-4).
4. Реверсируя строку с помощью нарезки в Python
С использованием отрицательной индексной строки нарезки в Python мы также можем поменять строку и хранить ее в другой переменной. Для этого нам просто нужно упомянуть Размер (-1) Отказ
Давайте посмотрим, как это работает в приведенном ниже примере.
#reversing string using string slicing s= "AskPython" rev_s = s #reverse string stored into rev_s print(rev_s)
Выход :
nohtyPksA
Как мы видим, строка S обращается и хранится в Отказ Примечание : Для этого тоже исходная строка остается неповрежденной и нетронутой.
Повторение строк
Однажды у вас могут возникнуть обстоятельства, при которых вы захотите использовать Python для автоматизации некоторых задач. И одной из таких задач может стать многократное повторение строки в тексте. Для того чтобы это осуществить, потребуется воспользоваться оператором , который, как и оператор , отличается от . При использовании с одной строкой и одним числом становится оператором повторения, а не умножения. Он лишь повторяет заданный текст указанное число раз.
Давайте выведем на экран 9 раз с помощью оператора .
print("Sammy" * 9)
SammySammySammySammySammySammySammySammySammy
Таким образом, с помощью оператора повторения мы можем сколь угодно клонировать нужный нам текст.
Unicode
Python поддерживает Unicode так как по дефолту в нём используется UTF-8
Это позволяет использовать юникод символы без заморочек
>>> «Pythonia voi käyttää myös vaativassa ja tieteellisessä»
‘Pythonia voi käyttää myös vaativassa ja tieteellisessä’
Если бы поддержки не было скорее всего пришлось бы заменять специальные символы, такие как умлауты, на из юникод представление
>>> «Pythonia voi k\u00e4ytt\u00e4\u00e4 my\u00f6s vaativassa ja tieteellisess\u00e4»
‘Pythonia voi käyttää myös vaativassa ja tieteellisessä’
Можно получить юникод символы и другими способами
‘\xe4’
‘ä’
Методы строк
Строка является объектом в Python. Фактически, все, что есть в Python – является объектом. Если вы хотите узнать больше об Объектно-ориентированном программирование, мы рассмотрим это в другой статье «Классы в Python«. В данный момент достаточно знать, что строки содержат собственные встроенные методы. Например, допустим, у вас есть следующая строка:
Python
my_string = «This is a string!»
| 1 | my_string=»This is a string!» |
Теперь вам нужно сделать так, чтобы вся эта строка была в верхнем регистре. Чтобы сделать это, все, что вам нужно, это вызвать метод upper(), вот так:
Python
my_string.upper()
| 1 | my_string.upper() |
Если вы открыли ваш интерпретатор, вы также можете сделать то же самое:
Python
«This is a string!».upper()
| 1 | «This is a string!».upper() |
Существует великое множество других методов строк. Например, если вам нужно, что бы все было в нижнем регистре, вам нужно использовать метод lower(). Если вы хотите удалить все начальные и конечные пробелы, вам понадобится метод strip(). Для получения списка всех методов строк, впишите следующую команду в ваш интерпретатор:
Python
dir(my_string)
| 1 | dir(my_string) |
Вы увидите что-то на подобие этого:
Python
|
1 2 3 4 5 6 7 8 9 10 |
‘__add__’,‘__class__’,‘__contains__’,‘__delattr__’,‘__doc__’,‘__eq__’,‘__format__’, ‘__ge__’,‘__getattribute__’,‘__getitem__’,‘__getnewargs__’,‘__getslice__’,‘__gt__’, ‘__hash__’,‘__init__’,‘__le__’,‘__len__’,‘__lt__’,‘__mod__’,‘__mul__’,‘__ne__’, ‘__new__’,‘__reduce__’,‘__reduce_ex__’,‘__repr__’,‘__rmod__’,‘__rmul__’,‘__- setattr__’,‘__sizeof__’,‘__str__’,‘__subclasshook__’,‘_formatter_field_name_split’, ‘_formatter_parser’,‘capitalize’,‘center’,‘count’,‘decode’,‘encode’,‘endswith’,‘expandtabs’, ‘find’,‘format’,‘index’,‘isalnum’,‘isalpha’,‘isdigit’,‘islower’,‘isspace’, ‘istitle’,‘isupper’,‘join’,‘ljust’,‘lower’,‘lstrip’,‘partition’,‘replace’,‘rfind’,‘rindex’, ‘rjust’,‘rpartition’,‘rsplit’,‘rstrip’,‘split’,‘splitlines’,‘startswith’,‘strip’,‘swapcase’, ‘title’,‘translate’,‘upper’,‘zfill’ |
Вы можете спокойно игнорировать методы, которые начинаются и заканчиваются двойным подчеркиванием, например __add__. Они не используются в ежедневном программировании в Python
Лучше обратите внимание на другие. Если вы хотите узнать, что делает тот или иной метод, просто обратитесь к справке
Например, если вы хотите узнать, зачем вам capitalize, впишите следующее, чтобы узнать:
Python
help(my_string.capitalize)
| 1 | help(my_string.capitalize) |
Вы получите следующую информацию:
Python
Help on built-in function capitalize:
capitalize(…)
S.capitalize() -> string
Выдача копии строки S только с заглавной буквой.
|
1 2 3 4 5 6 |
Help on built-in function capitalize: capitalize(…) S.capitalize() -> string Выдача копии строки S только с заглавной буквой. |
Вы только что узнали кое-что о разделе, под названием интроспекция. Python может исследовать все свои объекты, что делает его очень легким в использовании. В основном, интроспекция позволяет вам спрашивать Python о нём. Вам моет быть интересно, как сказать о том, какой тип переменной был использован (другими словами int или string). Вы можете спросить об этом у Python!
Python
type(my_string) # <type ‘str’>
| 1 | type(my_string)# <type ‘str’> |
Как вы видите, тип переменной my_string является str!
Поиск подстроки в строке
Чтобы в Python выполнить поиск в строке, используют метод find(). Он имеет три формы и возвращает индекс 1-го вхождения подстроки в строку:
• find(str): поиск подстроки str производится с начала строки и до её конца;
• find(str, start): с помощью параметра start задаётся начальный индекс, и именно с него и выполняется поиск;
• find(str, start, end): посредством параметра end задаётся конечный индекс, поиск выполняется до него.
Когда подстрока не найдена, метод возвращает -1:
welcome = "Hello world! Goodbye world!"
index = welcome.find("wor")
print(index) # 6
# ищем с десятого индекса
index = welcome.find("wor",10)
print(index) # 21
# ищем с 10-го по 15-й индекс
index = welcome.find("wor",10,15)
print(index) # -1
Unicode in Python
If we want to create Unicode strings, we add a or character at
the beginning of the text.
unicode.py
#!/usr/bin/env python # unicode.py text = u'\u041b\u0435\u0432 \u041d\u0438\u043a\u043e\u043b\u0430\ \u0435\u0432\u0438\u0447 \u0422\u043e\u043b\u0441\u0442\u043e\u0439: \n\ \u0410\u043d\u043d\u0430 \u041a\u0430\u0440\u0435\u043d\u0438\u043d\u0430' print(text)
In our example, we print Leo Tolstoy: Anna Karenina in azbuka.
$ ./unicode.py Лев Николаевич Толстой: Анна Каренина
We can use the Russian letters directly if we use the encoding
comment.
unicode2.py
#!/usr/bin/python # -*- coding: utf-8 -*- # unicode2.py text = 'Лев Николаевич Толстой: Анна Каренина' print(text)
In this example, we use non-latin characters directly in
the source code. We have defined UTF-8 encoding with a
encoding comment.
#3 Интерполяция строк / f-Строки (Python 3.6+)
Python 3.6 Добавил новый подход форматирования строк под названием форматированные строчные литералы, или “f-строки”. Этот новый способ форматирования строк позволяет вам использовать встроенные выражения Python внутрь строковых констант. Вот простой, наглядный пример:
Python
name = ‘Bob’
print(f’Hello, {name}!’)
# Вывод: ‘Hello, Bob!’
|
1 2 3 4 |
name=’Bob’ print(f’Hello, {name}!’) |
Как вы видите, это добавляет префикс к константе строки с буквой “f” — следовательно, названием становится “f-strings”. Этот новый синтаксис форматирования — очень мощный. Так как вы можете вставлять произвольные выражения Python, вы можете даже проводить встроенную арифметику. Посмотрим на пример:
Python
a = 5
b = 10
print(f’Five plus ten is {a + b} and not {2 * (a + b)}.’)
# Вывод: ‘Five plus ten is 15 and not 30.’
|
1 2 3 4 5 |
a=5 b=10 print(f’Five plus ten is {a + b} and not {2 * (a + b)}.’) |
Форматированные строчные литералы — это особенность парсера Python, которая конвертирует в серию строчных констант и выражений. Затем, они соединяются и составляют итоговую строку.
Представьте, что у вас есть следующая функция greet(), которая содержит :
Python
def greet(name, question):
return f»Hello, {name}! How’s it {question}?»
print(greet(‘Bob’, ‘going’))
# Вывод: «Hello, Bob! How’s it going?»
|
1 2 3 4 5 6 7 |
defgreet(name,question) returnf»Hello, {name}! How’s it {question}?» print(greet(‘Bob’,’going’)) |
Когда вы разбираете функцию, и смотрите, что происходит за кулисами, вы увидите, что f-строка в функции трансформируется в нечто, похожее на следующее:
Python
def greet(name, question):
return «Hello, » + name + «! How’s it » + question + «?»
|
1 2 |
defgreet(name,question) return»Hello, «+name+»! How’s it «+question+»?» |
Python
>>> import dis
>>> dis.dis(greet)
2 0 LOAD_CONST 1 (‘Hello, ‘)
2 LOAD_FAST 0 (name)
4 FORMAT_VALUE 0
6 LOAD_CONST 2 («! How’s it «)
8 LOAD_FAST 1 (question)
10 FORMAT_VALUE 0
12 LOAD_CONST 3 (‘?’)
14 BUILD_STRING 5
16 RETURN_VALUE
|
1 2 3 4 5 6 7 8 9 10 11 |
>>>importdis >>>dis.dis(greet) 2LOAD_CONST1(‘Hello, ‘) 2LOAD_FAST(name) 4FORMAT_VALUE 6LOAD_CONST2(«! How’s it «) 8LOAD_FAST1(question) 10FORMAT_VALUE 12LOAD_CONST3(‘?’) 14BUILD_STRING5 16RETURN_VALUE |
Строчные литералы также поддерживают существующий синтаксис формата строк метода str.format(). Это позволяет вам решать те же проблемы с форматированием, которые мы рассматривали в двух предыдущих разделах:
Python
print(f»Hey {name}, there’s a {errno:#x} error!»)
# Вывод: «Hey Bob, there’s a 0xbadc0ffee error!»
|
1 2 3 |
print(f»Hey {name}, there’s a {errno:#x} error!») |
Новые форматированные строчные литералы аналогичны шаблонным литералам (Template Literals) в JavaScript, которые были добавлены в ES2015. Я думаю это достаточно хорошее нововведение в Python, и я бы с радостью пользовался ими на каждодневной основе (в Python 3). Вы можете узнать больше о форматированных строчных литералах в интернете.
Python comparing strings
Comparing strings is a common job in programming. We can compare two strings
with the operator. We can check the opposite with the
non-equality operator. The operators return a boolean
or .
comparing.py
#!/usr/bin/env python
# comparing.py
print("12" == "12")
print("17" == "9")
print("aa" == "ab")
print("abc" != "bce")
print("efg" != "efg")
In this code example, we compare some strings.
print("12" == "12")
These two strings are equal, so the line returns .
print("aa" == "ab")
The first two characters of both strings are equal. Next the following characters
are compared. They are different so the line returns .
print("abc" != "bce")
Since the two strings are different, the line returns .
$ ./comparing.py True False False True False
This is the output.