Первичные и внешние ключи mysql
Содержание:
Языки манипулирования данными
Основное средство для общения с реляционными базами данных — язык структурированных запросов SQL.
Это декларативный язык. То есть инструкции в нём не идут одна за другой (не как в императивных языках). Каждый оператор SQL описывает только необходимое действие, а СУБД сама принимает решение, как его выполнить.
Например, чтобы выбрать все данные из таблицы Messages за 10.11.2020, делается запрос:
SELECT * FROM messages WHERE date = ‘10.11.2020’
Язык структурированных запросов делится на несколько частей (группы операторов) и позволяет:
- определять данные (DDL),
- манипулировать ими (DML),
- контролировать доступ к данным (DCL)
- и управлять транзакциями (TCL).
В SQL изначально нет средств для создания печатных отчётов, экранных форм и других инструментов для разработки программ. Хотя SQL сам по себе не является полноценным (Тьюринг-полным) языком программирования, но его стандарт позволяет создавать процедурные расширения. Они доводят его функциональность до полноценного языка программирования.
При этом синтаксис SQL в разных СУБД может различаться. Кое-где даже используются его отдельные диалекты, например:
- T-SQL — для работы с Microsoft SQL Server;
- на PL / SQL пишут хранимые процедуры и функции в Oracle;
- на PL / pgSQL — в PostgreSQL.
Виды нереляционных баз данных
Базы NoSQL делятся на четыре основные категории (в зависимости от решаемых с их помощью задач).
Ключ-значение
Такую базу можно представить как огромную таблицу. В каждой её ячейке хранятся данные произвольного типа, а каждому значению присвоен уникальный ключ, по которому это значение можно найти.
Такая СУБД не поддерживает связи между объектами, выполняет лишь операции поиска значений по ключу, добавления и удаления записи.
Например:
| key | value |
|---|---|
| user1 | {Кузнецов В., отдел маркетинга} |
| user2 | {name:Лена, position:секретарь} |
| user3 | {ООО «Вектор»} |
| user4 | {Трофимова Таня, отд.2, дизайнер} |
| user5 | {Галина Николаевна, гл. бух.} |
| user6 | {65,84,236} |
Базы «ключ-значение» часто используют для кэширования данных и организации очередей.
Их достоинства — быстрый поиск и простое масштабирование.
Их недостаток — нельзя производить операции со значениями. Например — сортировать их или анализировать.
Одна из самых популярных — Redis. Её используют Uber, Slack, Stack Overflow, сайты гостиниц и туристические, социальная сеть Twitter.
Документоориентированные СУБД
В таких данные хранятся в виде иерархических структур (документов) с произвольным набором полей и их значений. Документы объединяются в коллекции.
Если провести аналогию с реляционными СУБД, то коллекциям соответствуют таблицы, а документам — строки в них.
Например, фрагмент документа с информацией о фильмах:
Документоориентированные базы используют в системах управления содержимым (CMS) — для хранения каталогов и пользовательских профилей.
Одна из самых популярных — MongoDB (там можно создавать процедуры на JavaScript).
Колоночные
Эти базы отличаются от реляционных лишь способом хранения данных на накопителе.
Если реляционная база создаёт для каждой таблицы по файлу, то в колоночной отдельный файл создаётся для каждого столбца таблицы.
Например, если реляционная таблица выглядит так:
| name | color | property |
|---|---|---|
| волк | серый | зубастый |
| коза | белая | рогатая |
| капуста | зелёная |
То те же записи колоночной базы будут выглядеть примерно так:
| name | волк | коза | капуста |
| color | серый | белая | зелёная |
| property | зубастый | рогатая |
Что это даёт? Представьте, что вам нужны только названия объектов, а их свойства вас не интересуют.
При выполнении запроса в реляционной таблице просматривается каждая запись и из неё выбираются нужные данные. В колоночной базе с диска будет считана только одна колонка с названиями. Это сокращает время выполнения запроса, причём намного.
Колоночные базы применяются в различных каталогах и архивах данных, работа с которыми основана на подобных выборках.
Одна из самых популярных СУБД такого типа — Apache Cassandra.
Графовые
В некоторых предметных областях данные удобно представлять в виде графов. Для их хранения лучше всего подходят графовые базы.
Вершины (или узлы графа) — это объекты (сущности), а рёбра графа — взаимосвязи между ними.
Первичный и уникальный ключи
Скрыть рекламу в статье
Первичный и уникальный ключи
Первичные ключи являются одним из основных видов ограничений в базе данных. Они применяются для однозначной идентификации записей в таблице. Допустим, мы храним в базе данных список людей. Вполне вероятно, что могут появиться два (или больше) человека с одинаковыми фамилией, именем и отчеством Как же гарантированно отличить одного человека от другого (конечно. речь идет о том, чтобы отличить одного человека от другого на основании информации, хранящейся в базе данных)?
В данном случае «человек» представлен одной записью в таблице, поэтому можно задаться более общим вопросом — как отличить одну запись в (любой) таблице от другой записи в этой же таблице. Для этого используются ограничения — первичные кпочи. Первичный ключ представляет собой одно или несколько полей в таблице, сочетание которых уникально для каждой записи. Для одной таблицы не существует повторяющихся значений первичного ключа.
Уникальные кчочи несут аналогичную нагрузку — они также служат для однозначной идентификации записей в таблице. Отличие первичных ключей от уникальных состоит в том, что первичный ключ может быть в таблице только один, а уникатьных ключей — несколько. Надо отметить, что и первичный и уникальный ключ могут быть использованы в качестве ссылочной основы для внешних ключей (см. далее).
Синтаксис создания первичного и уникального ключа на основе единственного поля следующий:
<pkukconstraint> = {PRIMARY KEY |
UNIQUE}
Примеры первичных и уникальных ключей:
CREATE TABLE pkuk(
pk NUMERIC(15,0) NOT NULL PRIMARY KEY, /*первичный ключ*/
ukl VARCHAR(SO) NOT NULL UNIQUE,/*уникальный ключ */
uk2 INTEGER NOT NULL UNIQUE /* еще уникальный ключ */);
Синтаксис создания первичного и уникального ключей на основе нескольких полей:
<pkuktconstraint> = {PRIMARY KEY |
UNIQUE) ( col )
Такой синтаксис позволяет создавать ключи на основе комбинации полей. Вот примеры создания первичных и уникальных ключей из нескольких полей:
CREATE TABLE pkuk2(
Number1 INTEGER NOT NULL,
Namel VARCHAR(SO) NOT NULL,
Kol INTEGER NOT NULL,
Stoim NUMERIC(15,4) NOT NULL,
CONSTRAINT pkt PRIMARY KEY (Numberl, Namel), /*первичный ключ pkt на
основе двух полей*/
CONSTRAINT uktl UNIQUE (kol, Stoim) ); /*уникальный ключ uktl на основе
двух полей*/
Обратите внимание, что все поля, входящие в состав первичного и уникального ключей, должны быть объявлены как NOT NULL, так как эти ключи не могутиметь неопределенного значения. Помимо создания ограничения первичных и уникальных ключей в момент создания таблицы имеется возможность добавлять ограничения в уже существующую таблицу
Для этого используется предложение DDL: ALTER TABLE. Синтаксис добавтения ограничений первичного или уникального ключа в существующую таблицу аналогичен описанному выше:
Помимо создания ограничения первичных и уникальных ключей в момент создания таблицы имеется возможность добавлять ограничения в уже существующую таблицу. Для этого используется предложение DDL: ALTER TABLE. Синтаксис добавтения ограничений первичного или уникального ключа в существующую таблицу аналогичен описанному выше:
ALTER TABLE tablename
ADD {PRIMARY KEY | UNIQUE) ( col )
Давайте рассмотрим пример создания первичного и уникального ключа с помощью ALTER TABLE. Сначала создаем таблицу:
CREATE TABLE pkalter(
ID1 INTEGER NOT NULL,
ID2 INTEGER NOT NULL,
UID VARCHAR(24));
Затем добавляем ключи. Сначала первичный:
ALTER TABLE pkalter
ADD CONSTRAINT pkall PRIMARY KEY (idl, id2);
Затем уникальный ключ:
ALTER TABLE pkalter
ADD CONSTRAINT ukal UNIQUE (uid) ;
Важно отметить, что добавление (а также удаление) ограничений первичных и уникальных ключей к таблице может производить только владелец этой таблицы или системный администратор SYSDBA (подробнее о владельцах и пользователе SYSDBA см. главу «Безопасность в InterBase: пользователи, роли и права») (ч
4).
Оглавление книги
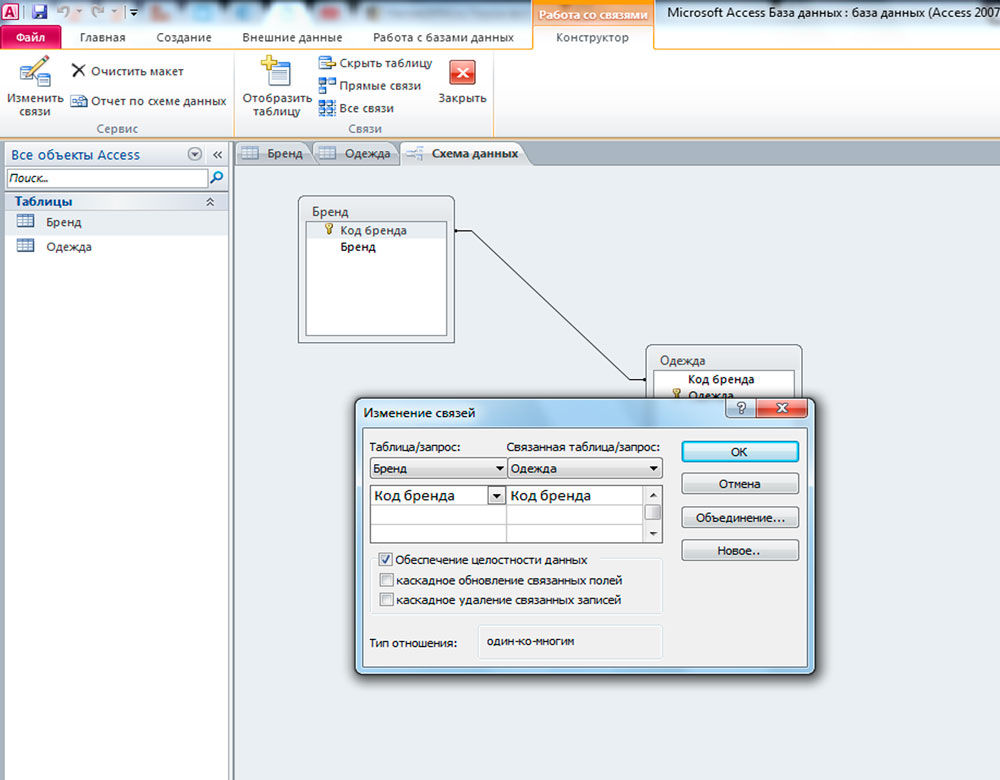
Ключи в Access
Поля, которые формируют связь между таблицами в Access, называют ключами. Как правило, ключ состоит из одного поля, но может включать и несколько. Существуют 2 вида ключей.
1. Первичный. Он может быть в таблице только один. Такой ключ состоит из одного либо нескольких полей, однозначно определяющих каждую запись в таблице. Нередко в качестве первичного ключа применяют уникальный идентификатор, код либо порядковый номер. К примеру, в таблице «Клиенты» можно назначить уникальный код клиента каждому клиенту. Поле кода клиента в таком случае будет являться первичным ключом данной таблицы. Если же первичный ключ состоит из нескольких полей, он обычно включает уже существующие поля, которые формируют уникальные значения в сочетании друг с другом. Допустим, в таблице с информацией о людях в качестве первичного ключа мы можем использовать сочетание фамилии, даты рождения и имени.
2. Внешний ключ. В таблице также могут быть несколько внешних ключей (либо один). Этот ключ содержит значения, которые соответствуют значениям первичного ключа другой таблицы. К примеру, в таблице «Заказы» каждый заказ может включать код клиента, который соответствует конкретной записи в таблице «Клиенты». А поле «Код клиента» будет внешним ключом таблицы «Заказы».
Таким образом, основой связи между таблицами в Access является соответствие значений между полями ключей. Посредством такой связи мы можем комбинировать данные из связанных таблиц. Допустим, существуют таблицы «Заказы» и «Заказчики». При этом каждая запись в таблице «Заказчики» идентифицируется полем первичного ключа, которое называется «Код»
Если мы хотим связать каждый заказ с клиентом, мы можем добавить в таблицу «Заказы» поле внешнего ключа, которое соответствует полю «Код» в нашей таблице «Заказчики», после чего создать связь между данными 2-мя ключами. В случае добавления записи в таблицу «Заказы» мы могли бы использовать значение кода клиента из нашей таблицы «Заказчики». Тогда во время просмотра каких-нибудь данных о клиенте, который сделал заказ, связь позволила бы определить, какие именно данные из нашей таблицы «Заказчики» соответствуют тем либо иным записям в нашей таблице «Заказы»:
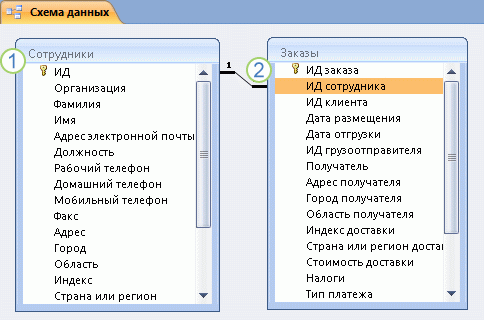
- Первичный ключ, определяемый по знаку ключа рядом с именем поля.
- Внешний ключ, определяемый по отсутствию знака ключа.
вступление
В теории реляционных баз данных для каждой сущности требуется один или несколько ключевых кандидатов, которые по определению должны быть уникальными. Один из этих ключевых кандидатов выбирается в качестве первичного ключа и реализуется как таковой при преобразовании объекта в таблицу базы данных. Несмотря на это соглашение, существуют также системы баз данных, которые позволяют определять таблицы без определения первичного ключа. Поэтому такие таблицы также допускают дублирование записей данных и, следовательно, не являются реляционными объектами по определению.
Супер ключ ⊇ ключевые кандидаты, из них выбирается первичный ключ
Различают ключевые термины
в реляционных базах данных.
- Супер ключ (иногда также называемый верхним ключом)
- Набор из (полей) в соотношении (таблице) , которые однозначно идентифицируют те кортежи (строки) в этом отношении, т.е. всегда содержат различные значения для кортежей , выбранных в парах (один также говорит «являются уникальными»). Например, тривиальный суперключ — это набор всех общих атрибутов отношения . (Тривиально, потому что отношение — это набор кортежей. Элементы наборов должны быть уникальными, поэтому в отношении не может быть двух одинаковых кортежей.)
- Ключевой кандидат (также называемый кандидатным ключом или альтернативным ключом )
- Минимальное подмножество атрибутов суперключа, которое позволяет идентифицировать кортеж (ключевые кандидаты ⊆ суперключ).
- Первичный ключ
- Выбранный ключевой кандидат, который впоследствии используется для сопоставления отношений. Значения этого ключа используются как внешние ключи при обращении к таблицам .
Формальное определение
Пусть дана некоторая реляционная схема R (каркас таблицы, т.е. все столбцы). Подмножество S атрибутов (столбцов) схемы R называется ключом, если:
- Уникальность
- R не может содержать два разных кортежа, в которых значения S одинаковы. Цель состоит в том, чтобы гарантировать, что никакое (возможное) выражение R не может содержать два разных кортежа, для которых значения S одинаковы: технически не законное, возможное заполнение таблицы может привести к появлению двух (технически разных) строк, ведущих к то же ключевое значение.
- Определение
- Некоторые системы баз данных допускают нулевые значения при условии, что это не нарушает уникальность. Цель должна состоять в том, чтобы все записи в таблице фактически определяли атрибуты из S; ни одна из записей не должна быть .
- Минимализм
- Так что ключ также является ключевым кандидатом, ни одно реальное подмножество S не должно уже удовлетворять условию уникальности.
Примеры
| ISBN | автор | Заголовок книги | … |
|---|---|---|---|
| 0001 | Ганс | В. | … |
| 0002 | Лутц | W. | … |
| 0003 | Питер | W. | … |
| 0004 | Питер | Икс | … |
| 0005 | Ральф | Y | … |
| … | … | … | … |
| Фамилия | день рождения | место жительства | … |
|---|---|---|---|
| Хайнц Хоффманн | 01.08.1966 | Север, BBS | … |
| Альф Аппель | 08.11.1957 | Mömlingen | … |
| Себастьян Саншайн | 04.08.1979 | Гамбург | … |
| Клаус Клебер | 15.04.1970 | Франкфурт | … |
| Барбара Бахманн | 17.10.1940 | Кирхгайм | … |
| … | … | … | … |
| прямой руководитель (ID) | Сотрудник (ID) |
|---|---|
| 002 | 104 |
| 030 | 512 |
| 115 | 519 |
| 234 | 993 |
| 234 | 670 |
| … | … |
- а
- Здесь ключ — это единственный атрибут. ISBN очень подходит для этого, потому что нет двух книг с одинаковым ISBN. Книги вполне могут иметь одно и то же название или принадлежать одному автору. Примечание: ISBN ( международный стандартный номер книги ) показан здесь только символически как серийный номер, ISBN на самом деле более сложен.
- б
- Здесь в качестве ключа используется комбинация двух атрибутов. Разработчик базы данных предполагает, что в один и тот же день нет клиентов с одинаковыми именами и днями рождения. Если в этом примере есть клиенты с одинаковым именем и день рождения в один и тот же день, то часть выбранных здесь атрибутов не может использоваться в качестве ключа.
- c
- Здесь только все атрибуты отношения рассматриваются как ключи. Персональный номер показывает, какой сотрудник компании является начальником какого другого сотрудника. Примечание. Записи данных этого отношения содержат только однозначные слева кортежи (1: n), потому что по техническим причинам и причинам, связанным с содержанием, у сотрудников обычно есть только один непосредственный руководитель. В принципе, конечно, кортежи отношений, которые являются типами отношений, могут содержать все возможные n: m назначений.
Проектирование базы данных
Основой любой реляционной БД являются
таблицы. Разработка таблиц является одним из наиболее сложных этапов в
проектировании БД. Грамотно спроектированные таблицы являются основой для
создания работоспособной и эффективной БД.
Понятие таблицы в Access полностью соответствует аналогичному
понятию реляционной модели данных. Любая таблица реляционной БД состоит из строк
(называемых также записями) и столбцов (называемых
также полями).
Строки таблицы содержат сведения об
однотипных объектах — документах, людях, предметах. На пересечении столбца и
строки находится конкретное значение, характеризующее объект.
Можно сформулировать ряд основных
требований, которым должны удовлетворять таблицы.
1. Информация в таблице не должна
дублироваться, т.е. в таблице не должно существовать двух записей с полностью
совпадающим набором значений ее полей.
2. На пересечении любого столбца и
любой строки должно находиться одно
значение.
3. Не рекомендуется включать в
таблицу данные, которые являются результатом вычислений.
4. Значения данных в одном и том же
столбце должны принадлежать к одному и тому же типу, доступному для
использования в данной СУБД.
5. Каждое поле должно иметь уникальное
имя.
6. Каждая таблица должна иметь
первичный ключ.
7. Таблицы БД должны быть связаны
через внешние ключи.
Каждая таблица должна содержать поле
(или набор из нескольких полей), значения в котором однозначно идентифицируют
каждую запись в таблице. Такое поле (или набор полей) называется ключевым полем
таблицы или первичным ключом. Первичный ключ любой таблицы обязан
содержать уникальные непустые значения для каждой записи. Если
для таблицы обозначены ключевые поля, то Access предотвращает дублирование или ввод пустых значений в ключевое поле.
В Access можно выделить три типа ключевых полей: простой ключ, составной
ключ и поле счетчика.
Если поле содержит уникальные значения,
такие как коды или инвентарные номера, то это поле можно определить как простой
первичный ключ. Если в этом поле появятся повторяющиеся или пустые
значения, Access выведет сообщение об ошибке.
В случаях, когда невозможно
гарантировать уникальность значений ни одного из полей, можно создать ключ,
состоящий из нескольких полей — составной первичный ключ. Для
составного ключа существенным может оказаться порядок образующих ключ полей. Не
рекомендуется определять ключ по полям Имена и Фамилии, поскольку нельзя исключить
повторения этой пары значений для разных людей.
Составной ключ необходим для таблицы,
используемой для связывания двух таблиц в отношении «многие — ко — многим»
Обычно такой ключ состоит из ключевых полей связываемых таблиц.
Если для какой-либо таблицы не удалось
определить простой первичный ключ или найти подходящий набор полей для
составного ключа, можно добавить в таблицу поле счетчика и
сделать его ключевым. При создании каждой новой записи Access генерирует уникальный номер записи,
называемый счетчиком. Указание такого поля в качестве ключевого
является наиболее простым способом создания ключевых полей.
Если до сохранения созданной таблицы
ключевые поля не были определены, то при сохранении будет выдано предложение о
создании системой ключевого поля. При ответе Да будет создано ключевое
поле счетчика.
Сила реляционных баз данных, таких как
БД Microsoft Access, заключается в том, что они могут быстро найти и связать данные
из разных таблиц при помощи запросов, форм и отчетов. Таблицы реляционных БД
связываются через одинаковые значения одноименных полей, содержащихся в
связываемых таблицах. Такие поля называются внешним ключом для
этих таблиц. Все таблицы БД Access должны
быть связаны с помощью внешних ключей.
SQL Учебник
SQL ГлавнаяSQL ВведениеSQL СинтаксисSQL SELECTSQL SELECT DISTINCTSQL WHERESQL AND, OR, NOTSQL ORDER BYSQL INSERT INTOSQL Значение NullSQL Инструкция UPDATESQL Инструкция DELETESQL SELECT TOPSQL MIN() и MAX()SQL COUNT(), AVG() и …SQL Оператор LIKESQL ПодстановочныйSQL Оператор INSQL Оператор BETWEENSQL ПсевдонимыSQL JOINSQL JOIN ВнутриSQL JOIN СлеваSQL JOIN СправаSQL JOIN ПолноеSQL JOIN СамSQL Оператор UNIONSQL GROUP BYSQL HAVINGSQL Оператор ExistsSQL Операторы Any, AllSQL SELECT INTOSQL INSERT INTO SELECTSQL Инструкция CASESQL Функции NULLSQL ХранимаяSQL Комментарии
SQL Справочник
SQL Ключевые слова
ADD
ADD CONSTRAINT
ALTER
ALTER COLUMN
ALTER TABLE
ALL
AND
ANY
AS
ASC
BACKUP DATABASE
BETWEEN
CASE
CHECK
COLUMN
CONSTRAINT
CREATE
CREATE DATABASE
CREATE INDEX
CREATE OR REPLACE VIEW
CREATE TABLE
CREATE PROCEDURE
CREATE UNIQUE INDEX
CREATE VIEW
DATABASE
DEFAULT
DELETE
DESC
DISTINCT
DROP
DROP COLUMN
DROP CONSTRAINT
DROP DATABASE
DROP DEFAULT
DROP INDEX
DROP TABLE
DROP VIEW
EXEC
EXISTS
FOREIGN KEY
FROM
FULL OUTER JOIN
GROUP BY
HAVING
IN
INDEX
INNER JOIN
INSERT INTO
INSERT INTO SELECT
IS NULL
IS NOT NULL
JOIN
LEFT JOIN
LIKE
LIMIT
NOT
NOT NULL
OR
ORDER BY
OUTER JOIN
PRIMARY KEY
PROCEDURE
RIGHT JOIN
ROWNUM
SELECT
SELECT DISTINCT
SELECT INTO
SELECT TOP
SET
TABLE
TOP
TRUNCATE TABLE
UNION
UNION ALL
UNIQUE
UPDATE
VALUES
VIEW
WHERE
MySQL Функции
Функции строк
ASCII
CHAR_LENGTH
CHARACTER_LENGTH
CONCAT
CONCAT_WS
FIELD
FIND_IN_SET
FORMAT
INSERT
INSTR
LCASE
LEFT
LENGTH
LOCATE
LOWER
LPAD
LTRIM
MID
POSITION
REPEAT
REPLACE
REVERSE
RIGHT
RPAD
RTRIM
SPACE
STRCMP
SUBSTR
SUBSTRING
SUBSTRING_INDEX
TRIM
UCASE
UPPER
Функции чисел
ABS
ACOS
ASIN
ATAN
ATAN2
AVG
CEIL
CEILING
COS
COT
COUNT
DEGREES
DIV
EXP
FLOOR
GREATEST
LEAST
LN
LOG
LOG10
LOG2
MAX
MIN
MOD
PI
POW
POWER
RADIANS
RAND
ROUND
SIGN
SIN
SQRT
SUM
TAN
TRUNCATE
Функции дат
ADDDATE
ADDTIME
CURDATE
CURRENT_DATE
CURRENT_TIME
CURRENT_TIMESTAMP
CURTIME
DATE
DATEDIFF
DATE_ADD
DATE_FORMAT
DATE_SUB
DAY
DAYNAME
DAYOFMONTH
DAYOFWEEK
DAYOFYEAR
EXTRACT
FROM_DAYS
HOUR
LAST_DAY
LOCALTIME
LOCALTIMESTAMP
MAKEDATE
MAKETIME
MICROSECOND
MINUTE
MONTH
MONTHNAME
NOW
PERIOD_ADD
PERIOD_DIFF
QUARTER
SECOND
SEC_TO_TIME
STR_TO_DATE
SUBDATE
SUBTIME
SYSDATE
TIME
TIME_FORMAT
TIME_TO_SEC
TIMEDIFF
TIMESTAMP
TO_DAYS
WEEK
WEEKDAY
WEEKOFYEAR
YEAR
YEARWEEK
Функции расширений
BIN
BINARY
CASE
CAST
COALESCE
CONNECTION_ID
CONV
CONVERT
CURRENT_USER
DATABASE
IF
IFNULL
ISNULL
LAST_INSERT_ID
NULLIF
SESSION_USER
SYSTEM_USER
USER
VERSION
SQL Server функции
Функции строк
ASCII
CHAR
CHARINDEX
CONCAT
Concat with +
CONCAT_WS
DATALENGTH
DIFFERENCE
FORMAT
LEFT
LEN
LOWER
LTRIM
NCHAR
PATINDEX
QUOTENAME
REPLACE
REPLICATE
REVERSE
RIGHT
RTRIM
SOUNDEX
SPACE
STR
STUFF
SUBSTRING
TRANSLATE
TRIM
UNICODE
UPPER
Функции чисел
ABS
ACOS
ASIN
ATAN
ATN2
AVG
CEILING
COUNT
COS
COT
DEGREES
EXP
FLOOR
LOG
LOG10
MAX
MIN
PI
POWER
RADIANS
RAND
ROUND
SIGN
SIN
SQRT
SQUARE
SUM
TAN
Функции дат
CURRENT_TIMESTAMP
DATEADD
DATEDIFF
DATEFROMPARTS
DATENAME
DATEPART
DAY
GETDATE
GETUTCDATE
ISDATE
MONTH
SYSDATETIME
YEAR
Функции расширений
CAST
COALESCE
CONVERT
CURRENT_USER
IIF
ISNULL
ISNUMERIC
NULLIF
SESSION_USER
SESSIONPROPERTY
SYSTEM_USER
USER_NAME
MS Access функции
Функции строк
Asc
Chr
Concat with &
CurDir
Format
InStr
InstrRev
LCase
Left
Len
LTrim
Mid
Replace
Right
RTrim
Space
Split
Str
StrComp
StrConv
StrReverse
Trim
UCase
Функции чисел
Abs
Atn
Avg
Cos
Count
Exp
Fix
Format
Int
Max
Min
Randomize
Rnd
Round
Sgn
Sqr
Sum
Val
Функции дат
Date
DateAdd
DateDiff
DatePart
DateSerial
DateValue
Day
Format
Hour
Minute
Month
MonthName
Now
Second
Time
TimeSerial
TimeValue
Weekday
WeekdayName
Year
Другие функции
CurrentUser
Environ
IsDate
IsNull
IsNumeric
SQL ОператорыSQL Типы данныхSQL Краткий справочник
Что представляет собой БД?
Как известно, база данных представляет собой инструмент сбора и структурирования информации. В БД можно хранить данные о людях, заказах, товарах и т. п. Многие БД изначально выглядят как небольшой список в текстовом редакторе либо электронной таблице. Но в связи с увеличением объёма данных, список наполняется лишней информацией, появляются несоответствия, не всё становится понятным… Кроме того, способы поиска и отображения подмножеств данных при использовании обычной электронной таблицы крайне ограничены. Таким образом, лучше заранее подумать о переносе информации в базу данных, созданную в рамках системы управления БД, например, в такую, как Access.
База данных Access — это хранилище объектов. В одной такой базе данных может содержаться более одной таблицы. Представьте систему отслеживания складских запасов с тремя таблицами — это будет одна база данных, а не 3.
Что касается БД Access, то в ней все таблицы сохраняются в одном файле совместно с другими объектами (формами, отчётами, модулями, макросами).
Для файлов БД, созданных в формате Access 2007 (он совместим с Access 2010, Access 2013 и Access 2016), применяется расширение ACCDB, а для БД, которые созданы в более ранних версиях, — MDB. При этом посредством Access 2007, Access 2013, Access 2010 и Access 2016 вы сможете, при необходимости, создавать файлы и в форматах более ранних версий (Access 2000, Access 2002–2003).
Применение БД Access позволяет:
• добавлять новые данные в БД (допустим, новый артикул складских запасов);
• менять информацию, находящуюся в базе (перемещать артикул);
• удалять данные (например, когда артикул продан либо утилизирован);
• упорядочивать и просматривать данные разными методами;
• обмениваться информацией с другими людьми посредством отчётов, сообщений, эл. почты, глобальной или внутренней сети.
Иностранный ключ
Первичный ключ одного отношения может стать внешним ключом другого
Внешний ключ является атрибутом или комбинацией атрибут связи , который относится к первичному ключу (или кандидата ключа) другого отношения или одного и того же отношения.
Он служит ссылкой между двумя отношениями, т.е. То есть он указывает, какие кортежи отношений связаны друг с другом с точки зрения содержания. Примерами внешних ключей являются два атрибута «старший» и «подчиненный» из примера отношения c) введения: Здесь указывается «табельный номер» сотрудника. Но мало что можно сделать с таким числом в повседневной жизни; гораздо более важными являются имя, отдел, занятость и подобная информация. Следовательно, скорее всего, будет существовать другое отношение, которое содержит такие атрибуты, как {табельный номер, имя, отдел, занятость, …}. Это отношение также, скорее всего, будет иметь первичный ключ {табельный номер}; поэтому рекомендуется использовать табельный номер в качестве внешнего ключа.
определение
Пусть R, S — отношения, а набор атрибутов α — первичный ключ R. Если совместимый набор атрибутов β из S должен быть внешним ключом по отношению к α, то значения β должны быть подмножеством значений Первичного ключа α в R. (см. ссылочную целостность )
Набор атрибутов совместим с другим, если диапазоны значений задействованных атрибутов совпадают, то есть dom (α) = dom (β) .
Внешние ключи и типы отношений
В мире баз данных различают разные типы отношений между двумя отношениями R и S. Термин «отношение» должен быть отождествлен с таблицей для лучшего понимания. В случае реляционных баз данных различают следующие типы отношений:
- Соотношение 1: 1 , каждой записи данных из R назначается максимум 1 запись данных из S; максимум 1 запись данных из R назначается каждой записи данных из S
- Отношение 1: n , отсутствие записи данных, одна запись данных или несколько записей данных из S назначаются каждой записи данных из R; максимум 1 запись данных из R назначается каждой записи данных из S
- отношения n: m , каждой записи данных из R может быть назначена одна запись данных или несколько записей данных из S; Каждой записи данных из S.
Случаи 1 и 2 реализуются с S, содержащим первичный ключ из R в качестве внешнего ключа. В случае отношения 1: 1 это также становится первичным ключом. Для отношения n: m, как в примере c) выше, вам потребуется отдельная связь, которая содержит первичные ключи обоих отношений в качестве внешних ключей. Оба набора атрибутов вместе являются первичным ключом этого «отношения связи».
Примечание. Фактические так называемые мощности этих трех типов отношений равны 1: 1 ⇒ : , 1: n ⇒ : и n: m ⇒ : . Знак «*» означает «любое число».
Что такое нормализация
Чтобы уменьшить размер реляционной базы (не хранить избыточные данные) и избежать противоречивости (аномалий) при работе с ними, отношения в базе нормализуют. Проще говоря — разбивают их на взаимосвязанные таблицы. Это называется декомпозицией.
Избыточность данных — это когда одни и те же данные хранятся в базе сразу в нескольких местах.
Проверим наш пример на избыточность
Каждая строка таблицы Messages содержит имя клиента и никнейм оператора, а также их телефоны. Причём в 1-й и 3-й строках мы видим звонки от одного и того же клиента, а в 1-й и во 2-й — ответы одного и того же менеджера. То есть в 1-й и 3-й строках дублируются имя и телефон клиента — Васи, а в 1-й и 2-й — никнейм менеджера «Оператор1».
Чтобы избавиться от дублирования информации, выделим сущности Клиент и Оператор. И вынесем специфичные для каждой атрибуты в отдельные таблицы.
В первой (Clients) будут храниться имена и телефоны клиентов, а во второй (Operators) — операторов. Кроме того, каждой записи в этих таблицах мы присвоим атрибут id — так называемый первичный ключ (его значение уникально, то есть не может повторяться в пределах таблицы). С его помощью мы установим связь с записями таблицы Messages.
Для этого к каждой записи в Messages (напомним, она всё ещё представляет сущность «звонок») добавим два новых атрибута (внешних ключа): id_client и id_oper. Они будут ссылаться на первичные ключи из таблиц Clients и Operators соответственно. Столбцы с именами и телефонами из таблицы Messages уберём.
И вот что получим:
В такой базе, чтобы поменять телефон клиента сразу для всех записей, достаточно изменить всего одно поле в таблице Clients.
Всего существует шесть форм нормализации реляционных баз данных — в порядке уменьшения избыточности отношений. Все они описаны формальными правилами. Наше отношение мы привели ко второй нормальной форме.