Руководство по яндекс.вордстат
Содержание:
- Другие сервисы и программы подбора ключей для Яндекс
- Определение LSI-копирайтинга
- Semrush
- Интерфейс и функционал Яндекс Wordstat
- Информационные и коммерческие запросы: выбор очевиден
- Анализ ключевых слов конкурентов
- Высоко- средне- и низкочастотные запросы
- Инструменты для определения частотностей
- Что это такое
- Как не потерять нужные запросы и не выкинуть лишнее?
- Зачем собирать частотности?
- Отличие частотности от конкуренции
- Как автоматизировать подбор ключевых слов в Вордстате
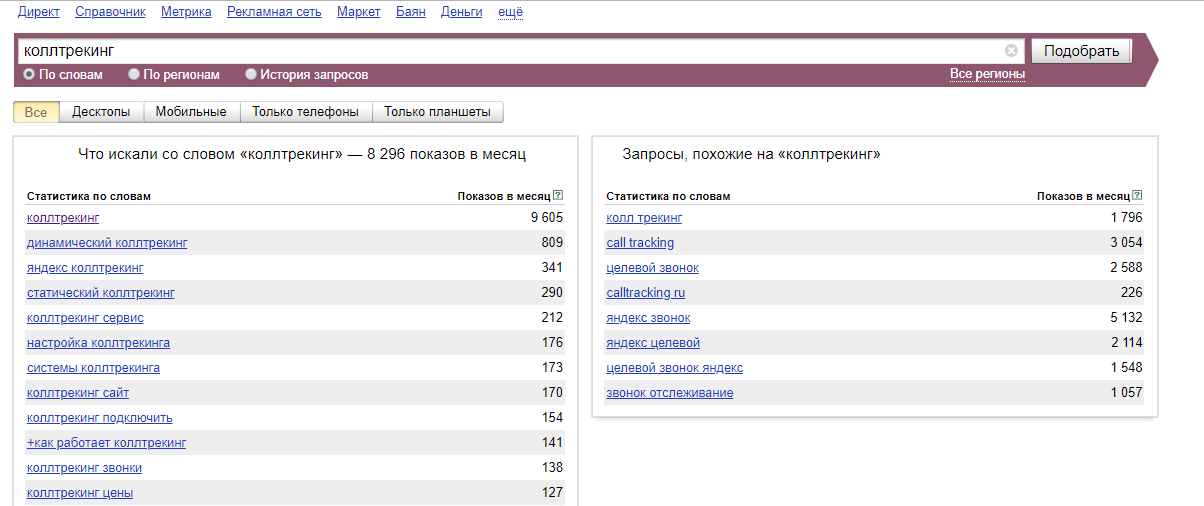
- Частота поисковых запросов что это такое
- Какие есть парсеры для Вордстата?
- Суть продвижения по низкочастотным запросам
- Распределение семантического ядра: внешняя оптимизация сайта
- Кому и зачем следует знать принцип работы Яндекс.Вордстат?
- Выводы
Другие сервисы и программы подбора ключей для Яндекс
- Key Collector. Самый популярный автоматизатор сбора семантического ядра. Собирает фразы, очищает от лишних, фильтрует по эффективности. Добротный инструмент с обилием функций. Платный.
- Slovoeb. Бесплатный аналог Key Collector для парсинга и формирования точного семантического ядра.
- Serpstat. Одна из крупнейших SEO-платформ, располагает широкими возможностями парсинга ключевых слов и анализа конкурентов.
- Semrush. Также мощный SEO-инструмент для всесторонней аналитики запросов.
- Яндекс.Директ. Провести первичный анализ ключевых слов рекламодатель может непосредственно в своём кабинете в Яндексе с помощью инструмента «Прогноз бюджета».
Определение LSI-копирайтинга
LSI, латентное семантическое индексирование, основано на технологии LSA, латентном семантическом анализе. Эта методика используется для автоматической индексации текста и проверки семантической структуры на наличие логических связей.
LSA задействует обновленные алгоритмы обработки данных с целью обнаружить в тексте не просто шквал ключевых слов, соответствующих поисковому запросу пользователя, а уловить общий смысл материала. С помощью LSA Яндекс, Google и другие поисковые машины могут находить для людей релевантный и полезный контент.
Подробнее о LSA
Ключевая задача LSA как метода – выявить логические связи в тексте. Поисковые боты используют эту методику для анализа естественного языка и формирования общей идеи текста, чтобы выдать статью в результатах поиска при вводе соответствующего запроса (в тот же Google или Яндекс).
Механизм LSA представляет собой систему сопоставления запроса с встречающимися в статьях терминами, а также модель анализа часто встречающихся в тексте слов с их определениями (проверка на соответствие фразы конкретной теме). Этот процесс позволяет «понять» тематику материала и оценить его качество без оглядки на плотность используемых ключевых слов.
Кратакая история индексации статей в интернете (появление тематического ядра)
В нулевых поиск работал примерно следующим образом:
-
Вы вводите какой-то поисковой запрос. Например, «купить гитара Москва недорого».
-
Получаете на первой странице десятки статей, которые идеально подогнаны под SEO благодаря огромному количеству ключей в тексте. Но смысла и пользы в этих статьях никакой.
На ранжирование влияли именно ключи. Они вставлялись даже в том случае, если не вписывались в текст логически и визуально. Тексты трудно было читать, они не несли внятной смысловой нагрузки, но все равно были в топ-10 статей по запросу.
С появлением новых алгоритмов (после 2011 года) поисковики научились анализировать содержимое текстов и фильтровать некачественные материалы, содержащие избыток ключей в груде исковерканного текста.
В ход пошли синонимы, ассоциации, гиперонимы, любые связанные текстовые элементы. В общем, некое тематическое ядро, напрямую не зависящее от выбранных ключевых слов. Именно тематическое ядро стало главным критерием при определении релевантности и качества текстов.
Пример тематического ядра
Блогер Koma Live в своей публикации на Medium описал наглядный пример использования тематического ядра и его влияния на результаты поиска.
Представим себе часто используемый поисковой запрос – «гольф». И вы взялись писать текст на эту тему, используя только одно ключевое слово. Основываясь только на нем, поисковик не сможет понять, о чем ваша статья. Об игре? Об автомобиле? Или о длинных носках? Поэтому робот будет пытаться проанализировать контекст (то самое тематическое ядро).
По этой причине копирайтерам в ТЗ часто указывают не только основные ключевые запросы, но и дополнительные слова, которые нужно использовать, чтобы сыграть на LSI-факторе (помимо SEO).
Проблема ключевых слов с длинным хвостом
Любой запрос в интернете, даже самый длинный, является ключом. Даже что-то в духе «обзор на лучшие ноутбуки 2020 года для программистов: HP, Lenovo, MSI, Samsung». Такие фразы не видны при поиске в подсказках Google, но они существуют и могут быть использованы для оптимизации.
Проблема таких ключей заключается в их избыточном количестве. И оптимизировать текст под каждый из них не получится. Отсюда возникает вопрос: оптимизировать текст под длинные ключи или просто упомянуть эти слова в контексте всего материала? На практике, при прочих равных, лучше работает второй метод.
LSI-копирайтинг на том и построен, что автор текста без определенных намерений адаптирует текст под бесконечное множество «хвостатых ключей», создавая тематическое ядро, которое поможет поисковику найти статью и закинуть ее в топ. Главное, чтобы сам материал оставался качественным.
Semrush
Бесплатная версия сервиса предоставляет по 10 фраз в широком и фразовом соответствии, с частотами и под нужный регион.
Также сервис предлагает посмотреть поисковые фразы по заданному ключевому слову в других регионах, это позволяет расширить спектр поисковых фраз.
Недостатки:
- в бесплатной версии нельзя увидеть больше 10 фраз;
- цена платной версии 100$;
- нельзя загружать ключевые фразы списком.
Достоинства:
- охватывает все страны мира, удобно собирать запросы и частотность под западный регион;
- по каждому запросу показывает топ сайтов в выдаче, на которые можно ориентироваться для сбора базовых списков поисковых запросов.
Интерфейс и функционал Яндекс Wordstat
Главная страница сервиса содержит поисковую строку, это основной инструмент работы. Искать с помощью Яндекс Вордстат ключевые слова вы будете именно через неё.
Под строкой располагаются 3 переключателя:
- По словам;
- По регионам;
- История запросов.
Первый вариант возвращает два столбца. Левый показывает список слов в порядке убывания количества показов каждого из них. Верхняя строка отражает частоту показов запроса, введённого в строку. Ниже расположены вариации исходной фразы в изменённой форме и с добавлением вспомогательных слов. Их показатели включены в итоговое число из первой строки. Правый столбец содержит фразы, похожие на искомую. Это могут быть и видоизменённые формы, и сопутствующие запросы, полезные для рекламодателя. Если какой-либо ключ из второй колонки достаточно популярен, он может расширить семантическое ядро и помочь привлечь клиентов по непрямым запросам.
Опция «По регионам» выводит на экран список географических локаций с частотой показов исходного ключа без каких-либо его изменённых форм. Среди регионов присутствуют континенты, страны, сама Россия целиком, её федеральные округа, субъекты и города. Крайний справа показатель «Региональная популярность» — аналог Affinity index, как замечает Яндекс. Это отношение доли показов, которая приходится на данный регион, к доле его показов среди всех прочих внутри региона. Если показатель равен 100% — это значит, что слово на указанной территории ничем не выделено. Значение более 100% говорит о повышенном местном интересе к фразе, а ниже — о недостаточном интересе.
Вкладка «История запросов» — это графическое отображение динамики поиска по заданному ключевому слову за последние 2 года, а также таблица со значением каждого месяца.
С правой стороны от переключателей находится фильтр регионов. С его помощью можно отсеять ненужные локации и произвести поиск информации только по ограниченному кругу территорий.
Уже в процессе поиска под основной строкой появится блок с переключателями устройств:
- Все;
- Десктопы;
- Мобильные;
- Только телефоны;
- Только планшеты.
Фильтрация по устройствам помогает понять, какие их типы наиболее популярны по данному запросу.
Информационные и коммерческие запросы: выбор очевиден
Использование информационных запросов также рентабельно. К примеру, вы продаёте композитную черепицу. Запрос «композитная или битумная черепица» относится к информационному, но он может принести вам продажи. В любом случае наличие статьи о достоинствах композитной черепицы перед битумной станет для вас плюсом, нежели подобного рода контент разместит на своём ресурсе ваш конкурент, продающий битумную черепицу.
Есть такое понятие: информационные запросы, не имеющие коммерческого посыла. К примеру, вы продаёте каменные столешницы. В данном случае, запрос «своими руками» не приведёт на ваш сайт покупателей.
Анализ ключевых слов конкурентов
1. Serpstat
Serpstat — cервис позволяет получить информацию о ключевых словах конкурентов в SEO и контекстной рекламе. Умеет работать с разными регионами мира и поисковыми системами.
Тарифы стартуют от 69$ до 499$.
Есть trial.
2. SpyWords
SpyWords — полезный сервис позволяющий узнать ключевые слова конкурентов, осуществить подбор ключевых слов для сайта, сравнить видимость и другие параметры на уровне доменов.
Возможности сервиса:
- Анализ конкурентов
- Сравнение доменов
- Продвинутое сравнение
- Рейтинг доменов
- Умный подбор запросов
- Сравнение позиций
Тарифы от 1 978 руб. до 4 950 руб.
3. Keys.so
Keys.so — дает возможность анализа сайта по видимости в поисковых системах, в сетях контекстной рекламы. Оценивает стоимость трафика и ключевых слов.
Стоимость от 1 500 руб./мес. до 14 500 руб./мес. в зависимости от выбранного тарифа (есть скидки при оплате сразу за год).
При подписке на “Базовый” или “Корпоративный тариф” открывается возможность использовать функционал “СемЯдро”.
“СемЯдро” — модуль, позволяющий быстро и удобно создать семантическое ядро для сайта или рекламной кампании с помощью древовидных структур и автоматической кластеризации.
4. SimilarWeb
SimilarWeb — всемирный сервис для анализа сайтов, в платной версии позволяет узнать ключевые фразы, источники трафика и так далее.
Есть свободный тариф и тариф для компаний — от 199$.
5. Ahrefs
Ahrefs — глобальный сервис для анализа сайтов, не так давно начал работать с ключевыми фразами. Позволяет оценить ключевые фразы конкурентов, наиболее популярный контент и много других параметров.
Недавно появилась обновленная версия Ahrefs Site Explorer с усовершенствованным функционалом для работы с ключевыми словами.
Стоимость тарифных планов: от 82$ до 832$ в месяц (+возможность получить скидку при оплате за год).
6. Semrush
Semrush — сервис отлично работает с западным сегментом, позволяет проанализировать ключевые слова, оценить конкурентов, увидеть распределение трафика по страницам и т.д. С русскоязычным сегментом работает хуже.
Стоимость подписки стартует от 119$ и до 449$ в месяц.
7. SpyFu
SpyFu — анализ конкурентов в разрезе платного и бесплатного трафика. Отличный удобный интерфейс. Один из лидеров западного рынка по работе с ключевыми словами.
Подписка стоит от 33$ до 299$ в месяц.
|
Название |
Описание |
Тарифы |
Trial |
|
Serpstat |
Cервис позволяет получить информацию о ключевых словах конкурентов в SEO и контекстной рекламе |
от 69$ до 499$ |
Есть |
|
SpyWords |
Сервис позволяющий узнать ключевые слова конкурентов, осуществить подбор ключевых слов для сайта, сравнить видимость и другие параметры на уровне доменов |
от 1 978 руб. до 4 950 руб. |
Нет |
|
Keys.so |
Сервис дает возможность анализа сайта по видимости в поисковых системах, в сетях контекстной рекламы. Оценивает стоимость трафика и ключевых слов |
от 1 500 руб./мес. до 14 500 руб./мес. |
Нет |
|
SimilarWeb |
Сервис для анализа сайтов, в платной версии позволяет узнать ключевые фразы, источники трафика |
от 199$/мес. |
Есть |
|
Ahrefs |
Сервис для анализа сайтов, позволяет оценить ключевые фразы конкурентов, наиболее популярный контент и много других параметров |
от 82$ до 832$ в месяц |
Есть |
|
Semrush |
Сервис отлично работает с западным сегментом, позволяет проанализировать ключевые слова, оценить конкурентов, увидеть распределение трафика по страницам |
от 119$ и до 449$ в месяц |
Есть |
|
SpyFu |
Анализ конкурентов в разрезе платного и бесплатного трафика |
от 33$ до 299$ в месяц |
Нет |
Высоко- средне- и низкочастотные запросы
Существует еще одна важная классификация, на которую точно стоит обратить внимание при составлении семантического ядра. Согласно ей запросы подразделяются на следующие виды:
- высокочастотные или ВЧ (частотность от 5 000)
- среднечастотные или СЧ (частотность от 1 000 до 5 000)
- низкочастотные запросы или НЧ (частотность от 1 до 1 000)
Цифры очень условные и мы – рекомендуем ориентироваться на нишу и географию продвигаемого сайта. Ниже приводим несколько характеристик, которые способны помочь в классификации запросов.
Высокочастотные запросы
Данный вид запросов включает в себя максимально общие фразы. Они состоят, как правило, из 1-2 слов. По такому ключевику не всегда очевидно, что хочет пользователь, из-за этого они часто имеют более низкую конверсионность. Но всегда есть исключения, поэтому рекомендуем анализировать именно конкретную ситуацию. Если сайт молодой лучше начинать с НЧ и СЧ запросов, а ВЧ подключать со временем.
Пример ВЧ запроса показан ниже:
Среднечастотные запросы
Эти запросы содержат более точные фразы, обычно состоят из 3-4 слов. Хотя они все еще и охватывают большое количество пользователей, но имеют уже более понятный интент. Пример указан ниже на рисунке.
Низкочастотные запросы
Это наиболее точные запросы, показывающие намерения пользователя. Как правило, содержат 5 и более слов. Мы советуем всегда добавлять в СЯ часть НЧ фраз, которые привлекут целевой трафик на сайт. При этом они помогают более эффективно продвигать страницы за счет текстовой оптимизации.
Пример НЗ запроса показан ниже:
Инструменты для определения частотностей
А теперь к самому интересному – как же определить частотность?
Для этого можно использовать различные сервисы.
В Яндекс WordStat необходимо ввести запрос, выбрать регион, интересующее устройство, нажать «Подобрать», далее сервис покажет результат:

Можно посмотреть статистику по регионам и городам:

Яндекс.Директ – сервис для запуска рекламы в поисковой системе Яндекс. Посмотреть частотность запроса можно при создании рекламной кампании. Доходим до второго шага «Выбор аудитории», задаем регион и нажимаем «Подобрать фразы». При вводе фразы получаем статистику по ним.

Частота запросов в Яндекс.Директ может несколько отличаться от показателей Яндекс.Вордстат. Это происходит, потому что последний не учитывает вложенные запросы с прогнозом меньше пяти. Кроме того, данные берутся за последние 30 дней, но в Директе они обновляются чаще из-за чего могут быть расхождения в пару дней. И наконец, необходимо отслеживать нет ли минус-слов в Яндекс.Директе, которые могут повлиять на статистику.
В случае снятия данных за год, они могут отличаться от данных в сервисе WordStat и быть некорректными.
Google Keyword Planner – инструмент для подбора ключевых слов при создании рекламы в ПС Google. Поможет при сборе статистики по запросам в Google.
Необходимо зайти в инструмент, авторизоваться и выбрать «Найдите новые ключевые слова»:

Далее нужно ввести слова через запятую и нажать «Показать результаты»:

Далее необходимо отметить добавленные слова галочкой (расширить список можно будет дальше), выбрать соответствие (точное, широкое, фразовое) и нажать «Добавить ключевые слова»:

Рядом с каждым запросом появляется зеленый значок «В плане»:

Переходим в пункт меню «Ключевые слова», выбираем корректный регион вверху страницы, раскрываем график по стрелочке, выставляем максимальную цену за клик:

Для анализа нужно использовать столбец «Показы»:

Этот способ покажет точную статистику по Google, насколько это возможно в рамках данной поисковой системы.
SemRush – сервис, который может показать подробную информацию по ключевому слову, в том числе уровень конкурентности, вариации ключевого слова, поисковую выдачу и другие параметры. Часть инструментов в нем платная.

Ahrefs – еще один сервис для просмотра статистики по ключевому слову и подбора аналогов. Также является платным.

Серверы SemRush, Ahrefs и другие подобные инструменты получают данные о количестве запросов методом покупки сlickstream у крупных провайдеров, поэтому их данные будут отличаться от данных в Google Keyword Planner.
Что это такое
Яндекс Вордстат – это сервис, который позволяет посмотреть всю статистику запросов в поисковой системе Яндекс. Вы можете видеть частотность запросов (количество обращений на определенную единицу времени), историю, сезонность и т. д. При этом сервис может показывать различные вариации этих самых запросов.
Прямое вхождение – когда фраза используется только в том виде, в котором вы ее хотите видеть, непрямое – меняется порядок слов, что-то заменяется синонимами и т. д. Также у Вордстата есть так называемая “Правая колонка”. Она показывает похожие запросы.
С помощью всех этих инструментов вы сможете понять, насколько та или иная информация сейчас актуальна.
Yandex Wordstat – отличный сервис. И тем не менее его использование не всегда будет удобным. Если вы хотите просто посмотреть статистику по одному-двум запросам – пожалуйста, все это легко реализуется и не отнимет у вас много времени.
Однако если вы захотите составить семантическое ядро (набор поисковых фраз со статистикой), то использование Вордстата уже станет проблемой.
Для большого объема информации он просто непригоден, вам придется подолгу обрабатывать каждую поисковую фразу, не забывая вносить все нужные данные в таблицу. Не очень-то удобно.
Программы для автоматизации работы с сервисом могут значительно облегчить задачу. Среди них можно выделить СловоЕб, Кей Коллектор и Ассистент – плагин для Вордстат, который помогает легко парсить информацию. О последнем мы также поговорим в сегодняшней статье.
Как не потерять нужные запросы и не выкинуть лишнее?
Бывают такие ситуации и тематики, в которых:
- поискового спроса очень мало в принципе
- преобладают многословные запросы в различных словоформах и переформулировках
а) Первый вариант — оставлять запросы с частотностью от «!» = 1, как было сказано выше. Но не везде это возможно, в некоторых тематиках такие запросы или слишком конкретные (не имеют общих URL в SERP с другими запросами и не кластеризуются) и продвигать их нецелесообразно (нет смысла создавать отдельную страницу под такой низкий спрос) или не совсем целевые.
б) Второй вариант — использовать » «, вместо «!». Этот способ работает, когда в вашей семантике преобладают многословные запросы в различных словоформах и переформулировках. Дело в том, что «!» закрепляет конкретную словоформу, а так как многословный запрос может иметь огромное множество переформулировок, а «!» учитывает только одну конкретную, все остальные вы потеряете. Этот метод целесообразно использовать в том случае, если вы видите устойчивый тренд резкого падения частотности от » » к «!» — падение на 70% и более.
Зачем собирать частотности?
Есть три основных причины:
1. Частотность нужна для прогнозирования трафика. Данные о том, сколько раз пользователи ищут определенный запрос, позволяют примерно спрогнозировать количество переходов, которые сайт получит в зависимости от позиции в поиске.
Как это выглядит на практике?
- перед началом продвижения сайта вы собираете список запросов;
- чтобы оценить трафик по одной из фраз, определяете ее частотность («заказать диван в Новосибирске» — 1839);
- узнаете показатель CTR для разных позиций на странице выдачи;
- на основе этих данных прогнозируете объем трафика, который можно получить при ранжировании сайта в ТОП-10.
Формула для расчета объема трафика:
Частотность * CTR/100 = Прогнозируемый объем трафика.
Например, если вторая или третья позиция выдачи имеет CTR 25%, то вы можете рассчитывать примерно на такой объем трафика:
1839*25/100 = 459.
2. Фильтрация «мусорных» запросов — фраз с околонулевой частотностью. Под них нет смысла оптимизировать страницы сайта.
В каких случаях фразы можно считать мусорными?
Нет единого стандарта, нужно смотреть по тематике:
- Для узких тематик с небольшими объемами трафика можно оставлять и фразы с частотностью 1. Каждый пользователь на вес золота, поэтому стоит использовать все доступные запросы.
- Для магазинов, работающих в сегменте масс-маркета, стоит брать в работу запросы с частотностью от 5. Все, что ниже — можно смело удалять из ядра.
- Нижняя планка частотности запросов для информационных сайтов — 10-20.
Не стоит сразу удалять все запросы с небольшой частотностью. Проверьте, нет ли там низкочастотных запросов, по которым приходят «теплые» клиенты.
3. Частотность помогает правильно распределить запросы на странице. ВЧ-запросы размещают в элементы Title и H1. Фразы с меньшей частотностью используют для создания разделов и подразделов.
Отличие частотности от конкуренции
Еще один параметр – это конкуренция поискового запроса. Здесь они делятся на:
- высококонкурентные (ВК)
- среднеконкурентные (СК)
- низкоконкурентные (НК)
Низкочастотный запрос еще не значит, что по нему низкая конкуренция. На показатель конкурентности влияет множество факторов. Например, количество главных страниц в ТОП-10, прямые вхождения ключевой фразы в заголовок страницы, рекламные блоки в выдаче и т.д.
Данная тема будет затронута в другой публикации.
Зачастую, конкуренция высокая, когда запросу подходит большое количество сайтов выдачи, и низкая, если оптимизированных под запрос сайтов немного.
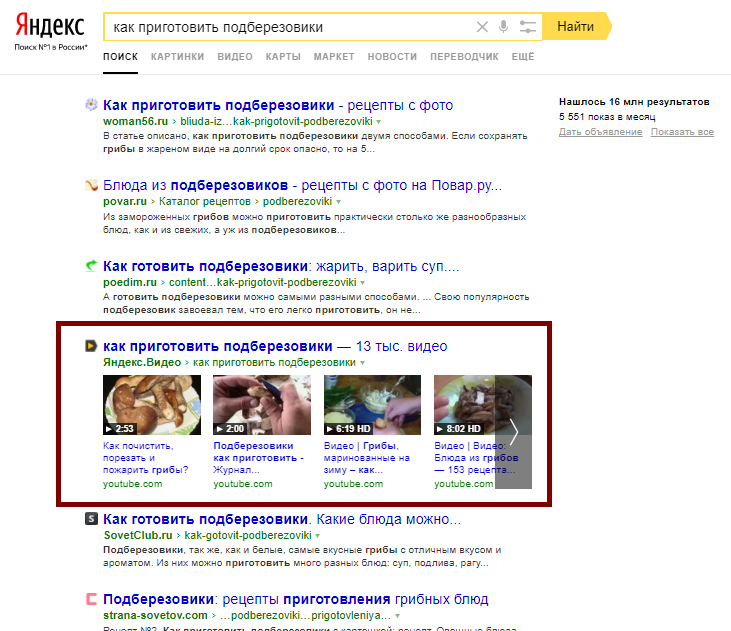
Одна из методик определения конкуренции, посмотреть количество результатов по запросу. Например, “продвижение сайтов спб” — 10 млн. подходящих результатов.
Показано ниже на рисунке:

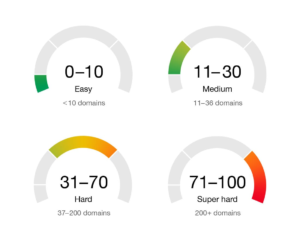
Другая методика – анализировать показатель, рассчитываемый по количеству внешних входящих ссылок/доменов. В разных сервисах он может называться по-разному. Например, в сервисе Ahrefs от компании Google он называется Keyword Difficult.
Пороги значений обозначены ниже:
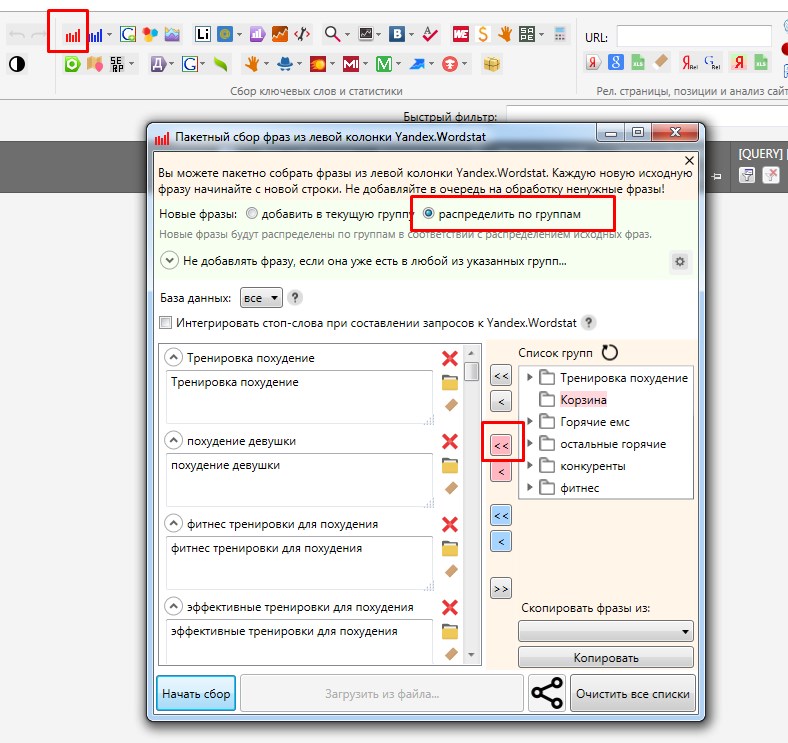
Как автоматизировать подбор ключевых слов в Вордстате
Даже с помощью плагинов вручную работать с Вордстатом достаточно трудоемко. Но процесс можно автоматизировать. Для этого нам пригодится два инструмента Click.ru:
- Подбор слов и медиапланирование.
- Парсер частотностей Вордстат.
Собираем ключевые слова
Зарегистрируйтесь / авторизуйтесь в Click.ru и откройте инструмент «Подбор слов и медиапланирование».
Укажите базовые данные:
- URL сайта, для которого будете собирать слова;
- место размещения рекламы (поиск, контекстно-медийная сеть или оба варианта).
- регионы, в которых планируете показывать рекламу.
По умолчанию система фиксирует стоп-слова (оператор +, который мы рассматривали выше) и проводит кросс-минусацию. Галочки лучше не снимать.
После указания всех необходимых данных нажмите «Начать новый подбор».
Система проанализирует сайт (URL которого указали на этапе базовых настроек). На основе контента сайта система автоматически подберет релевантные ключевые фразы.
Вы можете добавить к этому списку свои слова или воспользоваться дополнительными инструментами автоматического подбора:
- Слова конкурентов. Здесь нужно будет указать URL сайтов-конкурентов. Система проанализирует их и соберет семантику.
- Слова из счетчиков статистики. Откройте доступ к счетчикам Яндекс.Метрики и/или Google Аналитики. На основе их данных система подберет запросы, по которым к вам на сайт приходили посетители.
Автоматический подборщик слов — это хорошо. Но нам нужны данные Вордстата
Обратите внимание на блок «Ручной подбор слов». Это и есть подборщик на основе данных Вордстата
Как работает подборщик:
1. Введите по одному или списком базовые слова:
Система для каждого слова определяет частотность, а также прогнозы по кликам и бюджету в зависимости от желаемой доли трафика (указываете в столбце «Позиция»).
2. Для просмотра вложенных запросов нажмите на значок списка слева от заданной фразы.
Углубляться можно до тех пор, пока не закончатся вложенные запросы.
3. Просмотрите список подобранных слов. Поставьте галочки на тех, которые вам подходят, и нажмите «Добавить в медиаплан». Вы можете отметить одновременно запросы из ручного и автоматического подборщиков, и добавить в общий список.
Система просчитает бюджет по ключевым словам. Отчет со списком выбранных слов можно скачать в XLSX-формате. При желании можете продолжить настройку — в этом случае система сгенерирует объявления под каждое ключевое слово.
Проверяем частотности Вордстат
С помощью парсера Вордстат можно проверить частотность для списка запросов.
Откройте страницу парсера. Укажите список запросов в поле «Список фраз для проверки»
Также фразы можно загрузить с помощью XLSX-файла (обратите внимание, все запросы должны находиться на первом листе файла, 1 ячейка — 1 запрос)
Далее задайте настройки парсера:
- широкое соответствие;
- оператор «» (фиксирует количество слов в фразе);
- оператор «кавычки» с восклицательным знаком. Фиксирует количество слов в фразе и словоформу каждого слова;
- оператор [] (квадратные скобки). Используется для фиксации порядка слов в фразе.
Поставьте галочки на нужных параметрах (можете проставить галочки на всех четырех). Затем жмите «Запустить проверку». В течение нескольких минут отчет будет готов, и его можно будет скачать в разделе «Список задач».
Отчет скачивается в формате XLSX-файла. Для каждого запроса в таблице указана частотность. Данные по частотности с учетом операторов поиска указаны в отдельных столбцах. Отфильтруйте список и удалите фразы с околонулевой частотностью.
Вот подробный гайд по работе с парсером Вордстат.
Частота поисковых запросов что это такое
Поисковая система очень тщательно подсчитывает, сколько раз пользователи вбивают определенный запрос в строку поиска. Количество раз, когда определенные фразы или слова, которые были вбиты в поисковую строчку за определённый период времени, и называется частотой запроса по этим ключевикам. Если запросов много, то такие запросы относятся к высокочастотным.
Виды частотностей Wordstat
- Высокочастотные
- Среднечастотные
- Низкочастотные
Эту информацию обязательно нужно учитывать при оптимизации сайта под поисковые системы. Такое разделение дает возможность максимально правильно определить то, какие нужны затраты и ресурсы чтобы продвинуть тот или иной запрос в поисковой выдаче. Часто эту статистику предоставляет поисковая система в открытом доступе.
Частота запроса – это параметр, который важно учитывать при составлении и использования семантического ядра продвигаемого сайта. Если знать полную информацию о том, сколько раз вводились ключевые слова, у владельцев сайтов появляется возможность сделать выборку популярных запросов
Так как эти ключевые фразы часто вводятся, то на основании этих запросов можно и нужно создавать SEO контент на сайте.
Если говорить на языке, которым очень часто выражаются SEO-оптимизаторы сайтов, то высокочастотные запросы часто называются «жирные». Если правильно и успешно продвигать сайт по этим запросам, то во много раз может увеличиться посещаемость сайта из органического поиска. Но здесь есть ложка дёгтя. Все владельцы сайтов априори хотят продвигать свои сайты по этим высокочастотным запросам и делают это. Такие действия приводят к высокому уровню конкуренции.
Именно поэтому продвигаться по высокочастотным (жирным) запросам достаточно тяжело. Это требует очень больших финансовых и временных затрат.
Поисковые машины намеренно притормаживают раскрутку сайтов с такими запросами. Это сделано для того, чтобы сайт смог на деле показать серьезность своих намерений. Ресурс должен себя зарекомендовать в сети, показать, что пришёл в интернет не на один день. Только когда поисковые роботы убедятся в этом, можно будет подвинуть в выдаче своих конкурентов.
Оптимизация сайтов под средне и низкочастотные запросы
Чтобы уменьшить конкуренцию и увеличить шансы вывода сайта в ТОП 10 Яндекс и Google, необходимо начинать продвижение по низкочастотным запросам. В дальнейшем, после успешного продвижения низкочастотниками, можно переходить на средне и высокочастотные ключи. Даже если не смотреть на меньшие показатели низкочастотных запросов, все же они смогут не только создать прирост трафика без больших вложений денежных средств и времени, но и охватить большую часть целевой аудитории сайта.
Важно помнить, что частота поисковых запросов может быть разной для разных поисковиков. Это не удивительно, так как каждая поисковая система имеет свою аудиторию, что и определяет частотность ввода запроса
Как определить частотность ключевых слов
Google AdWords – ресурс, который показывает статистику поисковой системы Google.
С помощью этого инструмента можно отслеживать полную статистику запросов, которые ищут пользователи. Инструмент достаточно тонкий, при получении информации в настройках можно указывать язык и регион.
А также система показывает похожие запросы, которые пользователь вводил при поиске информации.
Rambler Adstat – это инструмент поисковой системы Рамблер. С помощью него также можно найти статистику запросов, указать регион запросов и даже время. На сегодняшний день он является одним из самых точных сервисов ключевых слов в русском интернете.
Яндекс Вордстат – показывает частоту поисковых запросов, которые вводят люди в поисковой системе Яндекс. Он тоже имеет гибкие настройки и может отслеживать запросы пользователей по регионам и отдельным городам.
На этом сегодня всё, всем удачи и до новых встреч!
Какие есть парсеры для Вордстата?
Обработка запросов в ВордСтат возможна только в ручном режиме. Это увеличивает время формирования семантического ядра (СЯ) даже для небольшого проекта. Для автоматизации разрабатывают программы и онлайн-сервисы – парсеры. Они собирают данные статистики Яндекс, используя технологию API и другие программные комплексы. В итоге пользователь может обрабатывать большой объем информации.
Цель работы парсеров – актуальная статистика ключевых фраз с возможностью углубленного анализа по параметрам. Это реализуется следующими способами:
- Программы. Сбор актуальной статистики WordStat, анализ по критериям пользователя. Условия использования – условно-бесплатное или платное.
- Онлайн-сервисы. По сравнению с программами обладают меньшим функционалом. Преимущества – экономия времени, не нужно устанавливать ПО.
- Специализированные программы. Разрабатываются для решения узконаправленных задач.
Выбор зависит от объема запросов и точности результатов. Онлайн-сервисы скачивают данные из Яндекса, чтобы уменьшить время формирования отчета. Поэтому информация не объективная. На это влияет частота обновления баз конкретного парсера.
Суть продвижения по низкочастотным запросам
Обратить внимание на низкочастотные запросы стоит хотя бы потому, что они позволяют получать все же небольшой, но трафик.
В качестве примера — два гипотетических молодых сайта:
Один сайт решили продвигать по ВЧ, другой – по НЧ. Проходит время, и у второго проекта появляется трафик из поиска. Скорее всего, он будет небольшим, в районе 10-100 человек ежедневно, но он будет. Первый сайт же может даже не занять позиции в первой десятке, не говоря уже о первых трех местах, из-за высокой конкуренции. Скорее всего, придется потратить много денег на продвижение.
Ключевое различие в том, что в случае продвижения под ВЧ всегда есть риск не получить трафика вообще, либо он будет минимальным, потому что немногие кликают дальше пятой позиции в выдаче.
Если же вы оптимизируете контент под НЧ, то практически ничем не рискуете. Со временем, если нет никаких серьезных ошибок на сайте, его страницы будут появляться в топе. И пусть это принесет гораздо меньше трафика, он будет стабильным.
Распределение семантического ядра: внешняя оптимизация сайта
Теперь кластеры нужно проанализировать и распределить по посадочным (целевым) страницам вашего сайта. Если есть похожие по смыслу кластеры — не нужно создавать под них отдельные страницы и тем самым плодить дублированный контент. Отбираем из них самый частотный кластер и его используем. Не пытайтесь также распределить на одной странице сразу несколько кластеров — это не приведет к успеху, придерживайтесь структуры и правила: каждый кластер = отдельному URL на сайте.
Когда вы уже определились с URL-страниц для своих кластеров, нужно подготовить техническое задание, чтобы распределить ключевые слова с точки зрения SEO-оптимизации. Переходим в инструмент Текстовый Анализатор SEO и создаем в нем под каждый кластер отдельный проект. Добавляем ключевые слова и запускаем проект. Текстовый Анализатор проанализирует тексты сайтов-конкурентов из выдачи ТОПа и сгенерирует ТЗ, которые дальше вы можете отправить копирайтеру.
Отдельно про функционал Текстовый Анализатор мы рассказывали в предыдущих материалах:
- Базовое руководство по Текстовому Анализатору
- Статья «Работаем с Текстовым Анализатором»
- Видеоруководство по Текстовому Анализатору
- Вебинар по Текстовому Анализатору
Кому и зачем следует знать принцип работы Яндекс.Вордстат?
Онлайн-сервис Вордстат – незаменимый помощник для SEO-оптимизаторов и специалистов по контекстной рекламе, продвигающих товары и услуги в Яндекс.Директ.
Работая с Яндекс.Вордстат, вы получите:
- список популярных ключевых запросов для создания рекламной кампании и продвижения веб-ресурса в поисковой выдаче;
- прогноз трафика, анализ частотности показов ключевых слов, соответственно, уровень спроса на тот или иной товар/услугу;
- тренды – запросы пользователей, которые только набирают популярность;
- полезные идеи и помощь при создании новых страниц веб-сайта.
Нужно ли изучать Яндекс.Вордстат владельцам бизнеса, нанимающим вышеперечисленных специалистов? Однозначно – да! Хотя бы поверхностное знание работы сервиса даёт возможность понимать, как и с помощью чего привлекаются новые клиенты. Таким образом, удаётся контролировать работу исполнителей.
Особенно важно тесное сотрудничество между заказчиком и исполнителем при продвижении бизнеса, предлагающего узкоспециализированные товары или услуги. В этом случае, знание и использование отраслевых терминов – верный путь к привлечению постоянных и крупных клиентов
Выводы
Сервисы по сбору семантики предоставляют разные ключевые слова: у всех разные базы данных и источники информации. Чем больше инструментов задействуется, тем полнее картина.
Но если вы выбираете качественный сервис для расширения семантического ядра, обращайте внимание на такие характеристики:
- размер базы поисковых запросов и частота ее обновления;
- выбор источника поисковых запросов (Google, Yandex, Bing);
- показ актуальных частотностей ключевых слов;
- возможность подбора синонимов для ключевых фраз в отдельном отчете;
- присутствие загрузки поисковых фраз для расширения списком, а не по одному слову;
- доступность баз поисковых фраз на всех языках и для всех стран мира;
- возможность искать поисковые подсказки для ключевых фраз;
- возможность добавлять список минус-слов в конкретной тематике.
После первого сбора ключевых фраз стоит еще раз пересмотреть высокочастотные, среднечастотные запросы, собрать список из частотных запросов, которых не было в базовом списке, и повторно выгрузить по ним семантику повторно.