Парсинг яндекс вордстат: что это и для чего?
Содержание:
- Метод перемножения
- Работа с операторами Вордстата
- Возможности Парсера и его преимущества
- Кейс №2
- Очистка СЯ от «мусора»
- Для чего нужен Яндекс.Вордстат
- Какой функционал предоставляет Spywords
- Зачем нужен Вордстат?
- Программы и сервисы для парсинга
- Как работают парсеры поисковых запросов
- Обзор парcера Yandex WordStat#
- Возможные настройки#
- Как работать с сервисом?
- Другие возможности сервиса
- Заключение
Метод перемножения
Шаг 1: расширения масок
Добавляем к базовым маскам расширения из одного слова, чтобы уточнить запрос по разным характеристикам в зависимости от специфики продукта:
Какие категории использовать — решаете сами. Откуда брать варианты? Сайты конкурентов, словари синонимов, тематические форумы и блоги — всё, где можно найти идеи о том, что именно в продукте интересует целевую аудиторию. Это могут быть синонимы, жаргоны, специфическая лексика и т.д.
Всё заносим для удобства в Excel. Получаем по каждому базису примерно такое:
Принцип: 1 ячейка = 1 слово.
Шаг 2: перемножение
Перемножаем первый столбец с остальными по очереди в любом сервисе генерирования ключевых слов:
Результаты переносим на отдельный лист, удаляем нецелевые и ультранизкочастотные запросы.
Работа с операторами Вордстата
Можно искать данные, просто вбивая запрос в поиск по сервису, но для конкретизации запросов есть операторы — добавочные символы с уточнениями. Они работают на вкладках поиска по словам и по регионам, на вкладке с историей запросов можно использовать только оператор «+запрос».
Обязательные слова
+запрос — оператор делает обязательным слово, перед которым стоит. Обычно его применяют для важных предлогов. Сервис учитывает разные формы слова, иногда из-за этого меняется смысл, а правило для предлога позволяет отсечь лишнее.
Оператор «+» в Вордстате
Минус-слова
-запрос — позволяет вычеркнуть из результатов запросы со словами, которые не должны в них встречаться. Обычно минусуют слова, размывающие тему, в коммерции убирают запросы с самостоятельным решением проблемы.
Оператор «-» в Вордстате
Точная словоформа
!запрос — оператор фиксирует окончание у слова, перед которым находится. Сервис покажет только запросы, где слово употреблено в заданной вами форме — нужном числе и падеже, с таким же окончанием.
Без дополнений
«»запрос»» — запрос в кавычках значит, что сервис покажет запросы без дополнений — хвостов, четко с указанным количеством слов.
При этом если какое-то слово или предлог в запросе дублируется, сервис добавит в результаты запросы, где на месте дубля другое слово. Запрос с двумя предлогами «в»:
Оператор «!» в Вордстате
Комбинируя операторы с кавычками и восклицательным знаком, можно достать более точные значения по нужной фразе без лишних сочетаний.
К примеру, по запросу «купить компьютер» выходят и запросы про очки, блок питания и другие сопутствующие предметы с частью «для компьютера», а с уточняющим словоформу оператором запросы сужаются.
Операторы «!» и «» в Вордстате
Длинные ключи в Wordstat
С помощью оператора с кавычками и повторения ключа можно достать больше интересных запросов из глубины Wordstat. Вбейте в поиск конструкцию «запрос запрос запрос запрос запрос запрос», то есть одинаковый запрос Х раз в кавычках, тогда сервис выведет запросы длиной в Х слов с употреблением этого ключа.
Способ найти более длинные ключи с помощью оператора «»
Обычный парсинг не даст собрать такие запросы. Количеством употреблений нужного слова можно регулировать длину запросов.
Точный порядок слов
— оператор с квадратными скобками делает строгим порядок слов в запросе
Часто это важно при географических запросах в логистике и туризме
Оператор «» в Вордстате
Группировка операторов
(запрос запрос) — этот оператор делает возможным группировку нескольких операторов. Тогда сервис учитывает их одновременно для указанных в скобках слов.
Группировка операторов в Вордстате
Синонимы
(запрос|запрос) — оператор позволяет указать синонимы для вариативности. Работает вместе со скобками для группировки. С такими операторами сервис будет искать запросы, выбирая слова из предложенных синонимов.
Оператор «|» в Вордстате
Возможности Парсера и его преимущества
Парсер Wordstat позволяет быстро собрать частотность для отдельных фраз или целого семантического ядра. Вот, что можно сделать с помощью инструмента:
- собрать частотность по Wordstat для неограниченного количества фраз;
- загрузить списком или файлом фразы для парсинга частотности;
- собрать частотность по любому региону, поддерживаемому Яндексом;
- собрать частотность только по фразам в определенном виде (с фиксированным порядком слов или словоформами), используя типы соответствия (операторы « », ! и ).
Главные преимущества:
- нет лимитов по количеству запросов: за один раз можно спарсить любое количество запросов (хоть 100, хоть 100 тысяч);
- весь парсинг выполняется на стороне сервиса. Вам не нужно опасаться бана личного аккаунта в Яндексе или создавать фейковые аккаунты под парсинг;
- при использовании Парсера не нужно применять прокси и вводить капчу;
- данные по частотности можно просуммировать по всем регионам или вывести отдельно по каждому региону. В этом случае вы фактически получаете отдельный отчет для каждого региона;
- парсинг работает «в облаке» – нет необходимости загружать ПО и устанавливать на компьютер, не нужно держать вкладку или браузер открытыми. Отчеты также сохраняются «в облаке» и доступны в любое время;
- готовый отчет формируется в формате XLSX-файла. С ним удобно работать, можно импортировать в Google Таблицы, если для вас они более привычны, чем Excel.
Кейс №2
Второй практический пример – нам надо получить маркерные запросы для категории «Стиральные машины Samsung», по которым мы в дальнейшем будем собирать облако запросов и делать теговые страницы. Так как искать данную категорию могут по разным написаниям запросов – стиральная машина, стиральная машинка, Samsung, Самсунг – нам нужно сделать соответствующую регулярку в Вордстате и в 1 клик получить все запросы для данной категории:
стиральные (машины|машинки) (samsung|самсунг) -ремонт -ошибки -отзыв -коды -видео -запчасти –неисправности
Также были добавлены базовые стоп слова, чтобы не получать мусорные запросы.
Очистка СЯ от «мусора»
Покажем, как это делать в Key Collector.
Ключевики, которые содержат ненужные слова
Нажимаем вкладку выбора условий фильтрации:

Задаем условие, как указано на скриншоте, и пишем слова:
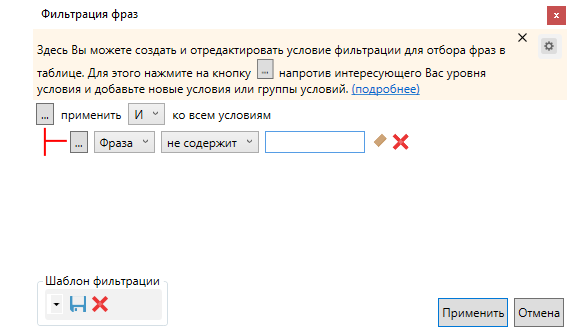
Отмечаем фразы и добавляем в корзину:
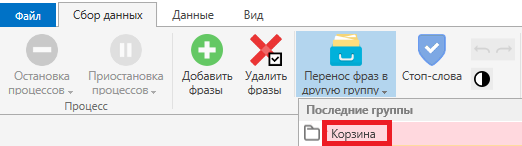
Повторы слов
Аналогично вызываем настройки фильтрации фраз и выбираем такой вариант:
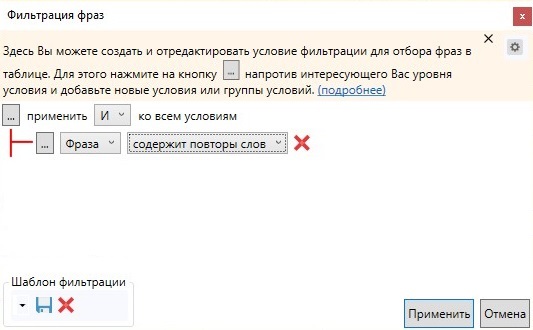
Стоп-слова (информационные запросы, города, в которых не действует предложение, «бесплатно», «дешево», субъективные определения и т.д.)
Нажимаем этот значок в верхнем меню:

В окне настроек добавляем фразы (1) и разбиваем по группам (2):
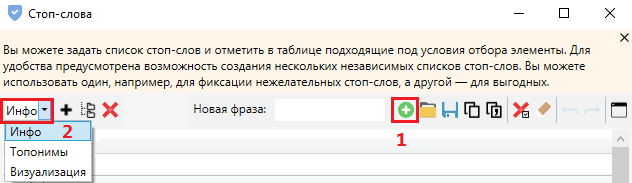
Далее — выделяем слова в таблице галочкой и добавляем в список стоп-слов.
Группы слов
Чтобы разбить запросы на группы, на вкладке «Данные» открываем «Анализ групп». В окне выбираем тип «По отдельным словам»:

Выбранные группы появятся в основном списке запросов, где можно отсеять все ненужные.
Запросы с нулевой частотностью
Выбираем следующее условие фильтрации:

Далее — требования по частоте:
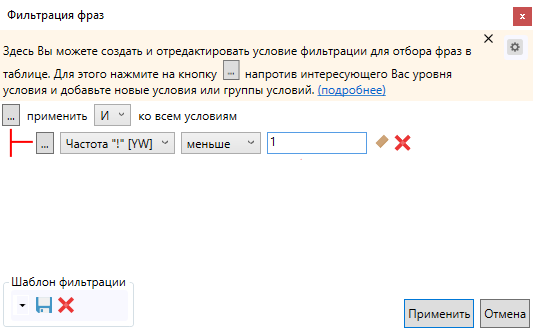
Можно удалить нецелевые запросы и вручную: копируем ключевики в Word. Заменяем пробел на знак абзаца, чтобы представить все слова из словосочетаний в виде колонки. Переносим обратно в Excel на отдельный лист, сортируем и определяем минус-слова. Затем находим с помощью фильтра фразы с ними и удаляем.
На какие вопросы машинный интеллект не дает ответы
Сбор семантики быстрее и проще с помощью различных сервисов, баз, приложений — благо, выбор есть. Однако нельзя слепо полагаться на автоматизацию. Есть два случая, когда без ручного труда не обойтись.
Уже при подборе масок нужно «вытаскивать» синонимы и переформулировки из сайтов заказчика и конкурентов, правой колонки Wordstat, собственных идей и т.д. Мы увидели, что это всё предстоит делать специалисту по контекстной рекламе.
Самый трудозатратный и не автоматизируемый процесс — очистка СЯ от «мусора». Готовых минус-списков и данных об отказах из Яндекс.Метрики недостаточно для 100% точности. Приходится смотреть предварительные списки и выявлять смысловое соответствие результатов бизнесу.
Особенно это касается сложных продуктов. Например, подготовка сжатого воздуха, или осушка воздуха. Больше расширений можно насобирать по слову «осушка».
Но среди результатов в Wordstat в мы можем увидеть и «осушка газа», и «адсорбционная осушка», и «осушка компрессора». Не всегда семантическое соответствие гарантирует смысловое соответствие. Это разные продукты, а значит, разный спрос. Чаще всего выявить и исключить его можно только вручную.
Если вы не проверяете результаты парсинга, вы жертвуете полнотой СЯ и точностью будущих рекламных кампаний. Совет: выбирайте оптимальный баланс «трудозатраты — полнота» и делайте полный список минус-слов.
Для чего нужен Яндекс.Вордстат
Яндекс.Вордстат — бесплатный сервис для получения статистики поисковых запросов в Яндексе. С помощью сервиса можно посмотреть, сколько раз пользователи искали определенный поисковой запрос на протяжении месяца. Но это далеко не всё.
Какие данные выдает Вордстат
1. Статистика по частотности:
- указанного запроса;
- запросов, которые содержат указанную фразу или слово.
2. Похожие запросы для расширения семантики.
3. Данные по частотности с разбивкой по регионам и городам.
4. Данные по показам с разбивкой по типу устройств (десктопы, смартфоны, планшеты).
5. Сезонные колебания спроса по выбранной фразе (динамика популярности фразы за прошедшие два года в разрезе месяца или недели с разбивкой по типу устройств).
Какой функционал предоставляет Spywords
Стоит ли спорить о том, насколько полезным может быть данный сервис для любого блогера или вебмастера?
Ведь его довольно богатый функционал позволяет производить множество манипуляций, направленных на seo-продвижение сайта в поисковых системах и охват большей аудитории.
Список заявленных служб выглядит следующим образом:
- Анализ конкурентов;
- Битва доменов;
- Война доменов;
- Рейтинги доменов;
- Умный подбор запросов.
Пройдемся более детально по каждой из них.
Анализ конкурентов
Это очень мощный инструмент, который позволяет узнать на каких позициях и по каким ключевым словам сайт находится в выдаче Яндекса и Google (для примера возьмем сайт самой компании Spywords).
Для чего нам эта информация нужна?
Все очень просто: именно под эти запросы можно написать свои статьи и перехватить немного трафика и себе. А может даже и не немного
Здесь стоит отметить, что в работу лучше брать не все запросы, а только с хорошей частотностью и невысокой конкуренцией. Как проверить эти показатели и какой сервис для этого нужно использовать я расскажу в следующей статье.
Статья уже готова и ждет вас вот здесь.
Так что, кто еще не подписался — подписывайтесь, а то есть вероятность пропустить реально полезную информацию.
Помимо этого, анализ транслирует изменения в позициях за определенное время и показывает основных конкурентов. Также анализ позволяет видеть текст объявлений в кампаниях контекстной рекламы и стоимость клика по каждой из поисковых фраз.
Я пока особо в подробности данной информации не вдавалась, поскольку мы не монетизируем блог. Но на будущее, конечно, эта информация будет необходима. Поэтому нужно знать, где её можно получить. Вот мы с вами теперь знаем где — сервис SpyWords.
Итак, какую информацию мы можем получить, проведя анализ своих конкурентов:
- запросы в поиске;
- позиции в поиске;
- сниппеты и урлы страниц;
- динамика позиций;
- запросы и позиции в контексте;
- оценка трафика.
Также анализировать конкурентов можно и в этом сервисе. Подробнее про него можно прочитать здесь.
Битва доменов
Это уникальный инструмент, который позволяет производить сравнение одновременно двух или трех доменов. Сравнение проводиться по таким основным параметрам, как запросы и трафик из контекста, запросы в топ 10 и 50 и, соответственно, трафик из поиска.
Благодаря этой услуге, можно посмотреть по каким пунктам ваш сайт не дотягивает до основных конкурентов, и направить все силы на восполнение и исправление этого недочета.
Сравним сайты Spywords и его конкурента xtool:
Также сервис предоставляет сравнительные диаграммы, на которых можно визуально наблюдать источники наибольшего количества трафика для каждого из доменов.
Война доменов
В отличие от Pro тарифа, функция «Война доменов» доступна только в тарифном плане Unlim. Он практически дублирует возможности «Битвы доменов», но главной его особенностью является то, что для сравнения можно добавлять до 20 разных доменов.
Такое дополнение превращает этот инструмент в настоящий исследовательский центр. Если в вашей нише много конкурентов, анализ каждого из них в отдельности может отнять достаточно времени.
Благодаря функции «Война доменов» можно не только ускорить этот процесс, но и значительно его автоматизировать, так как одна сводка дает детальную информацию по каждому из конкурирующих сайтов.
Рейтинг доменов
Это самый новый инструмент на сайте, который позволяет отслеживать позиции сайтов в поисковой выдаче, однако он доступен лишь в продвинутом тарифном плане.
Там можно просматривать текущую ситуацию в топе выдачи систем Яндекс и Google, следить за взлетами и падениями в выбранный период времени. Это значительно облегчает работу, потому что больше нет необходимости ежедневно отслеживать изменения в выдаче, перебирая вручную тысячи разнообразных запросов.
Умный подбор запросов
Еще один незаменимый помощник в работе вебмастера или блогера, который позволяет в считанные секунды составить полное семантическое ядро.
Вводим в строку необходимый запрос и нажимаем на кнопку «Найти все лучшие слова!»
И выбираем те запросы, которые считаем нужными.
Отличительной чертой этой функции на Spywords является ее большая практичность, так как ядро составляется из тех фраз, которые рекламодатели используют в своих контекстных кампаниях. В то время как большинство похожих сервисов по подбору ключевых фраз не делают детальную выборку по всем доступным фразам, перемешивая качественные слова с откровенно мусорными, Spywords отсеивает нерелевантные и некачественные варианты.
Для любого блогера такой инструмент станет отличной находкой и помощником в генерации новых идей и составлении семантические ядра.
Зачем нужен Вордстат?
Инструмент незаменим в таких случаях:
предстоит писать SEO-оптимизированные тексты, для которых важно определить состав ключевых фраз и частотность употребления;
необходимо составить структуру для новой страницы или для всего сайта;
нужно уточнить, какие слова в Вордстат вводят представители целевой аудитории, обращаясь к поисковой системе для решения проблемы, и как именно они формулируют мысли;
требуется выяснить, какие дополнительные интересы имеются у представителей целевой аудитории, чтобы грамотно составить ассортимент товаров и выкладывать максимально полезный контент.
Программы и сервисы для парсинга
Для начала нужно подобрать около 20 базовых фраз. Для этого используем свой мозг (подумайте, какие словосочетания ассоциируются с вашим родом деятельности), поисковую выдачу по схожим запросам и данные из Яндекс.Метрики и Google Search Console (смотрим, по каким ключам больше переходов на ваш сайт).
Далее для создания хорошего семантического ядра используем специальные программы.
Бесплатные
Часть работы можно проделать, не заплатив ни копейки. Здесь на помощь приходят определенные сервисы.
Wordstat Yandex
- показывает количество и частоту запросов в Яндексе;
- фразы изменяются в падежах;
- можно задать регион;
- позволяет сделать выборку по типу устройства (ПК, планшет, смартфон);
- позволяет исключить лишние фразы.
Планировщик ключевых слов Google
- подходит для узкой тематики;
- позволяет собрать широкую базу ключей;
- показывает статистику по словам;
- прогнозирует эффективность фраз.
Букварикс
- содержит большую базу запросов;
- функции фильтрации минимальны.
При использовании бесплатных ресурсов семантическое ядро получается «грязным» — словосочетания дублируются, выдаются нерелеватные запросы, слова с нулевой частотностью, которые приходится чистить с помощью фильтров или вручную.
Платные
Для расширения ядра советуем воспользоваться платными сервисами.
Rush Analytics
- автоматизирует сбор и группировку значимых словосочетаний;
- парсит запросы через Wordstat;
- регулируемая глубина поиска;
- классифицирует запросы по типам (коммерческие и информационные).
База Пастухова
- большая база ключевых слов (на русском и английском языке);
- фильтрует запросы по числовым данным;
- есть онлайн-версия;
- из-за дороговизны больше подходит крупным компаниям.
Serpstat
- комплексный сервис для продвижения ресурса;
- выделяет запросы, по которым проект попадает в ТОП-100 выдачи;
- возможность анализировать сайты конкурентов.
Для наибольшей эффективности советуем комбинировать бесплатные и платные сервисы.
Как работают парсеры поисковых запросов
После того как вы собрали базу ключей и расширили ее с помощью Вордстат, можно воспользоваться платным сервисом, чтобы очистить значимые фразы и составить семантическое ядро. Рассмотрим, как это сделать, на примере Кей Коллектора
- Открываем «Файл» -> «Новый проект» и устанавливаем регион.
- Нажимаем «Пакетный сбор слов из левой колонки Yandex.Wordstat», копируем уже имеющийся список и нажимаем «Начать сбор».
Запросы с базовой частотностью (БЧ) ниже 5 являются мало запрашиваемыми и принесут мало трафика, поэтому их лучше удалить.
Чтобы автоматизировать этот процесс, перед началом сбора слов устанавливаем в настройках нижнюю границу БЧ, которая будет включена в конечный результат.
С помощью удобных программ и нехитрых действий вы сможете собрать базу ключей, даже если вы новичок.
Используете функцию парсинга ключевых запросов? Делитесь опытом в комментариях!
Обзор парcера Yandex WordStat#

Wordstat — это сервис Яндекса, предназначенный для оценки пользовательского интереса к различным тематикам и подбора ключевых слов для SEO-оптимизации и контекстной рекламы. Кроме того, с помощью Wordstat Yandex можно оценить сезонность и географическую зависимость поисковых запросов.
Парсер ключевых слов Yandex WordStat поддерживает автоматические размножение запросов, вы можете быть уверены что получите максимальное число результатов из выдачи. Также A-Parser может автоматически переходить по связанным запросам на указанную глубину.
Функционал A-Parser позволяет сохранять настройки парсинга для дальнейшего использования (пресеты), задавать расписание парсинга и многое другое. Вы можете использовать автоматическое размножение запросов, подстановку подзапросов из файлов, перебор цифро-буквенных комбинаций и списков для получения максимально возможного количества результатов.
Сохранение результатов возможно в том виде и структуре которая вам необходима, благодаря встроенному мощному шаблонизатору Template Toolkit который позволяет применять дополнительную логику к результатам и выводить данные в различных форматах, включая JSON, SQL и CSV.
Возможные настройки#
important
| Параметр | Значение по умолчанию | Описание |
|---|---|---|
| Pages count | 10 | Количество страниц для парсинга |
| Region | All | Регион поиска |
| Remove + from keywords | ☐ | Удалять символ плюса (+) из найденных запросов |
| Use AntiGate | ☐ | Определяет использовать ли AntiGate для обхода каптч |
| AntiGate preset | default | Необходимо предварительно настроить парсер Util::AntiGate — указать свой ключ доступа и другие параметры, после чего выбрать созданный пресет здесь |
| AntiGate preset for Login | default | Пресет AntiGate для логина. Необходимо предварительно настроить парсер Util::AntiGate с параметрами, после чего выбрать созданный пресет здесь |
| Use Accounts | Использовать существующие аккаунты из файла files/SE-Yandex/accounts.txt | |
| First sleep | 50 | Задержка после первого запроса при использовании AntiGate для экономии каптч |
| Use session | Сохраняет хорошие сессии для дальнейшего использования | |
| Mobile only | ☐ | Получать статистику только для мобильного трафика |
| Remove bad accounts | Автоматическое удаление аккаунтов с неверным логин/паролем или требующих подтверждения по телефону |
Как работать с сервисом?
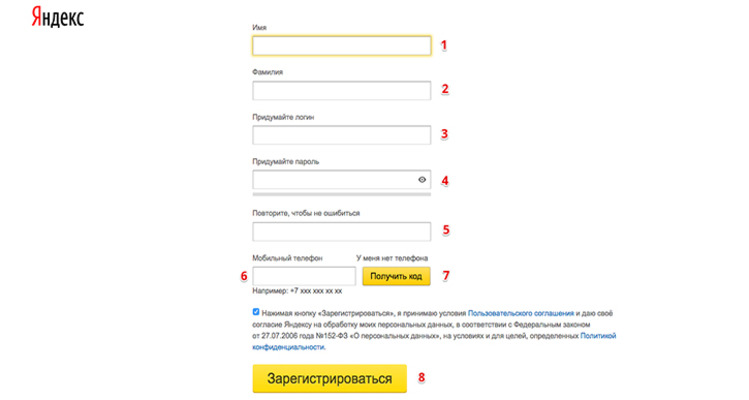
Войти (правый верхний угол) > Регистрация
Инструмент «По словам»
При входе в систему, у вас по умолчанию отображается инструмент «По словам».
- Поле ввода запроса — в эту строчку мы вводим слово или фразу по которой хотим увидеть данные.
- Инструменты сервиса — отображение слов по регионам и истории(тренд) запроса.
- Все регионы — выбор региона по которому будет отображаться статистика.
- Платформа — выбор платформы по которой будет отображаться статистика.
- Последнее обновление — дата последнего обновления данных в сервисе.
- Левая колонка Wordstat — показывается список запросов в которой содержится введенное в пункте(1) слово или фраза.
- Правая колонка Wordstat — показывается список фраз, которые еще могли искать люди вводившие наше слово или фразу.
Разберем подробнее, как работает левая и правая колонка Яндекс Вордстат.
Левая колонка
В левой колонке отображаются все фразы, которые содержат наш введенный запрос.
Например, мы вводим запрос яндекс вордстат. Нам покажутся все фразы, которые содержат наш запрос, при этом порядок слов не будет иметь значения.
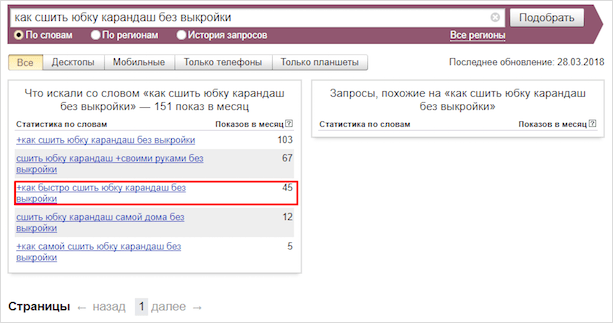
Это надо запомнить! Цифра напротив запроса — количество показов этой фразы в месяц, а не количество переходов по этой фразе! Например, если мы зайдем в поисковую систему https://www.yandex.ru/, наберем фразу яндекс вордстат и нажмем найти — это и будет 1 показ по этой фразе.
Цифра отображает все входящие в него запросы.
Например: В число показов 60 897 по запросу вордстат яндекс входят все числа запросов ниже, которые содержат фразу яндекс вордстат или вордстат яндекс порядок слов не имеет значения.
А в число показов 2295 по фразе яндекс вордстат ключевые входит число показов по фразе яндекс вордстат ключевые слова.
Если мы нажмем на фразу яндекс вордстат ключевые, то мы в этом убедимся. Нам отобразятся все фразы, которые входят в этот запрос.
Это основной принцип и логика работы инструмента «По словам» и левой колонки Wordstat. Для более расширенного отображения статистики, существуют операторы подбора слов.
Еще показы называют частотностью (частоткой). Прям так и говорят, частотность фразы яндекс вордстат равна 60 897.
Другие возможности сервиса
На всех вкладках Yandex Wordstat есть возможность выполнить сортировку по устройствам: «Десктопы», «Мобильные», «Только телефоны», «Только планшеты». Данный функционал будет полезен, например, при настройке рекламы мобильного приложения в Директе.
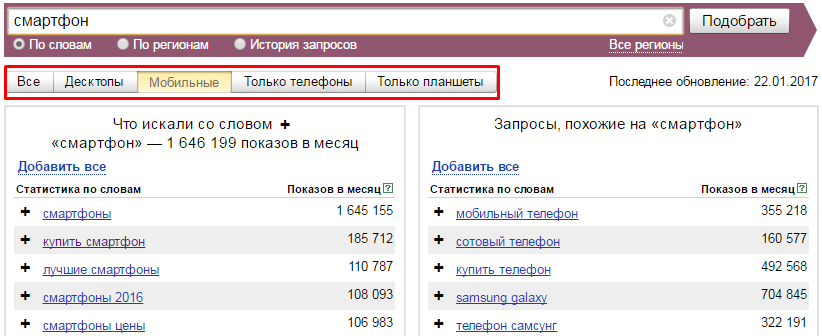
Возможность указания региона, в котором вы хотите посмотреть статистику:

С помощью Wordstat также можно посмотреть динамику изменения интереса к запросу на вкладке «История запросов» и количество запросов по регионам на вкладке «По регионам».
История запросов
Как уже говорилось, статистика на вкладке «По словам» отображается за последние 30 дней, поэтому для получения данных за более длительный период необходимо переключиться на вкладку «История запросов», где выводится количество показов по запросу за последние 2 года.

Данную вкладку можно использоваться для первичного анализа сезонности, определения «симптомов» накрутки и оценки динамики интереса к поисковым запросам.
По регионам
На вкладке «По регионам» можно оценить популярность запроса в регионе или городе относительно других, а также получить региональную популярность — долю, которую занимает регион по количеству показов результатов выдачи по данному слову. Другими словами, если популярность более 100%, это означает повышенный интерес к запросу. Чем интерес выше, тем больше процент. И наоборот.

Больше всего купить слона хотят в городе Калуга. Этому факту есть объяснение, попробуйте найти его и вы.

Информация с вкладки может быть использована при планировании контекстной рекламы для принятия решения о необходимости отдельных кампаний под определенный регион.
К сожалению, на этих вкладках не работают операторы Wordstat, поэтому посмотреть данные можно только по широкому типу соответствия.
Заключение
Знания, как пользоваться Яндекс Вордстатом, необходимы для анализа интересов целевой аудитории сайта или коммерческой компании. Тщательный отбор нужных поисковых запросов и внимательное изучение поможет выстроить работу, найти возможности для более эффективного развития.
Эффективный маркетинг с Calltouch
- Анализируйте воронку продаж от показов рекламы до ROI от 990 рублей в месяц
- Отслеживайте звонки с сайте с точностью определения источника рекламы выше 96%
- Повышайте конверсию сайта на 30% с помощью умного обратного звонка
- Оптимизируйте свой маркетинг с помощью подробных отчетов: дашборды, графики, диаграммы
- Добавьте интеграцию c CRM и другими сервисами: более 50 готовых решений
- Контролируйте расходы на маркетинг до копейки
Узнать подробнее