Что такое мета теги, как правильно заполнить и проверить: примеры из практики
Содержание:
- HTML Tags
- Синтаксис разметки Open Graph
- Проверка правильности Meta Robots и его содержимого в Netpeak Spider
- Example Meta Tags
- Директивы Meta Robots, которые стоит использовать в SEO
- Неправильная кодировка результатов из базы данных MySQL
- JavaScript
- Setting the Viewport
- Группа значений атрибута NAME
- The Rating Meta Tag
- Usage in Social Media (Open Graph, Twitter Cards, and Schema.org)
- Тег
- Группа значений атрибута NAME
- Adding Meta Tags to Your Documents
- Obsolete Usage
- The Distribution Meta Tag
- The Robots Meta Tag
HTML Tags
<!—><!DOCTYPE><a><abbr><acronym><address><applet><area><article><aside><audio><b><base><basefont><bdi><bdo><big><blockquote><body><br><button><canvas><caption><center><cite><code><col><colgroup><data><datalist><dd><del><details><dfn><dialog><dir><div><dl><dt><em><embed><fieldset><figcaption><figure><font><footer><form><frame><frameset><h1> — <h6><head><header><hr><html><i><iframe><img><input><ins><kbd><label><legend><li><link><main><map><mark><meta><meter><nav><noframes><noscript><object><ol><optgroup><option><output><p><param><picture><pre><progress><q><rp><rt><ruby><s><samp><script><section><select><small><source><span><strike><strong><style><sub><summary><sup><svg><table><tbody><td><template><textarea><tfoot><th><thead><time><title><tr><track><tt><u><ul><var><video>
Синтаксис разметки Open Graph
Полная документация по разметке Open Graph доступна в нескольких источниках:
- ogp.me — англоязычная документация;
- ruogp.me — документация на русском языке.
Более сжато и доступно информацию о микроразметке можно почитать в справке Яндекс.Вебмастера. Здесь изложена основная информация по разметке (кем разработана, где используется), а также документация по основным тегам, с помощью которых вы можете реализовать разметку на своем сайте.
Также есть руководства по применению Open Graph для отдельных соцсетей:
По сути, микроразметка — это набор мета-тегов, которые передают соцсетям нужную информацию и указывают, какой контент использовать при репосте и как его отображать.
Разметка Open Graph основана на синтаксисе RDFa (подробно о синтаксисах микроразметки мы писали). Для разметки прописываются дополнительные теги <meta> в разделе <head>. Внутри тега <meta> указываются атрибуты property и content. Атрибут property имеет обязательные и опциональные свойства. Рассмотрим их.
Обязательные свойства
Пройдемся по обязательным свойствам атрибута property, которые должны присутствовать в разметке:
Как быть с размерами картинок
У каждой соцсети есть свои требования к размеру картинок. По-хорошему, под каждую соцсеть нужно готовить отдельное изображение с подходящими размерами. Например, вы публикуете на сайте статью, которую планируете репостить в три соцсети: Твиттер, Фейсбук и ВКонтакте. Для каждой соцсети готовите отдельную картинку. Чтобы каждая соцсеть загрузила именно «свою» картинку, необходимо указать в разметке Open Graph следующие теги:
При репосте во ВКонтакте соцсеть учтет только тег vk:image, а остальные проигнорирует. Точно так же поступят и остальные соцсети.
Есть еще один вариант — задать один размер картинки для всех соцсетей. Для этого понадобятся теги og:image:width и og:image:height. Укажем с их помощью размер картинки для Фейсбука:
В других соцсетях картинка будет обрезаться в соответствии с параметрами соцсети. И это нужно учитывать — не размещать в «критичных» областях картинки текст или важные части изображения.
На скриншоте ниже в публикации для Фейсбук отобразилась полная картинка:
А при репосте во ВКонтакте картинка обрезалась под параметры соцсети:
Опциональные свойства
Помимо обязательных есть опциональные свойства, которые, тем не менее, рекомендуем заполнять:
Вот так description отображается в публикациях в Фейсбуке:
А так — в Телеграме:
А в Телеграме корректно подтягивается содержимое тега og:site_name:
Больше информации об основных и дополнительных мета-тегах разметки — в официальной документации OpenGraph.
Так выглядит фрагмент кода страницы с внедренной разметкой Open Graph:
Проверка правильности Meta Robots и его содержимого в Netpeak Spider
Перед проверкой атрибутов Meta Robots важно узнать, какие страницы индексируются на сайте, иначе не будет смысла внедрять вышеописанные атрибуты. Программа доступна для операционных систем Microsoft Windows и Mac OS, поддержка платформы Linux в данный момент не доступна, но находится в разработке
Вы можете пользоваться бесплатной версией в течение 14 дней без каких либо ограничений
Программа доступна для операционных систем Microsoft Windows и Mac OS, поддержка платформы Linux в данный момент не доступна, но находится в разработке. Вы можете пользоваться бесплатной версией в течение 14 дней без каких либо ограничений.
Воспользуйтесь промокодом при оформлении заказа и получите специальную скидку 10% на покупку Netpeak Spider и Netpeak Checker!
С помощью Netpeak Spider вы можете найти запрещённые к индексации страницы. На таких страницах программа делает особый акцент, отмечая ошибками:
- Заблокировано в Meta Robots. Показывает страницы, запрещённые к индексации с помощью инструкции в блоке .
- Nofollow в Meta Robots. Показывает страницы, содержащие инструкции в блоке .
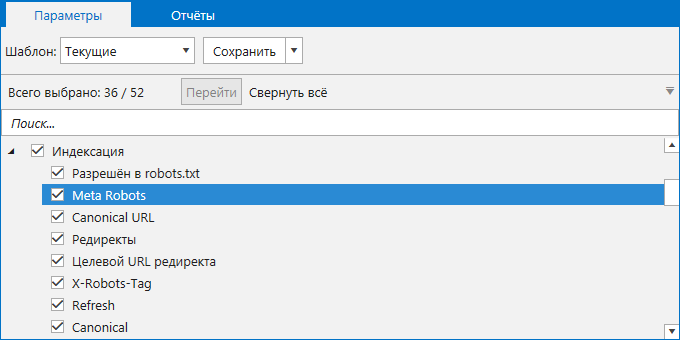
Для проверки сайта откройте программу и перейдите на вкладку «Параметры» на боковой панели. Найдите раздел «Индексация» и проверьте, отмечен ли галочкой пункт «Meta Robots». Если пункт не будет отмечен, программа не проанализирует метатег, и вы в финальном отчёте не увидите данных о нём.
Для сканирования всего сайта введите его начальный URL в адресную строку и нажмите кнопку «Старт». Если вам необходимо просканировать список страниц, зайдите в меню «Список URL» и выберите удобный вам способ добавления URL (ввести вручную, загрузить из файла или Sitemap, вставить из буфера обмена), после чего запустите сканирование.

По завершению сканирования получить информацию о Meta Robots вы можете несколькими путями:
1. В основной таблице на вкладке «Все результаты». В столбце Meta Robots просмотрите директивы, которые содержатся в соответствующем теге каждой из просканированных страниц.
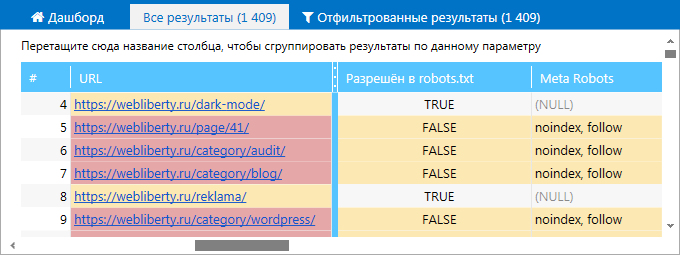
2. На вкладке «Ошибки» боковой панели. Найдите ошибки, связанные с Meta Robots, и кликните по их названию. В таблице отфильтрованных результатов вы увидите полный список страниц, на которых были найдены эти ошибки.
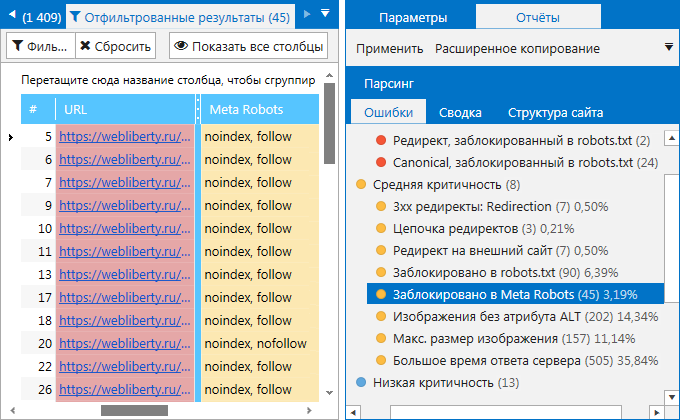
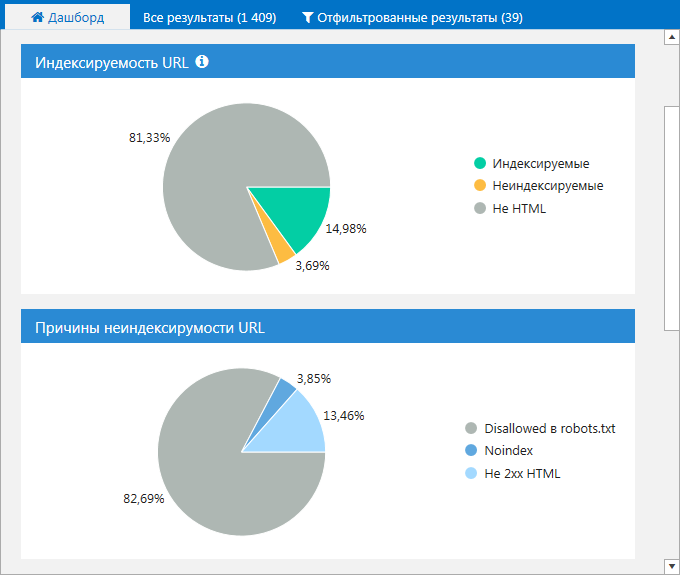
3. На вкладке «Дашборд». Вы можете просмотреть данные в виде диаграмм об индексируемых страницах на сайте, а также узнать причины их неиндексируемости. Кликните на интересующую вас область, чтобы получить список страниц, соответствующих тому или иному значению.
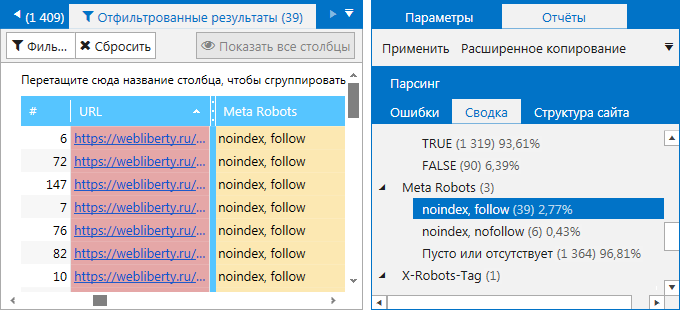
4. На вкладке «Сводка» на боковой панели. Здесь вы можете ознакомиться как закрытыми от индексации страницами, так и посмотреть, какие ещё значения помимо noindex, nofollow заданы в метатеге Robots. Найдите пункт «Meta Robots» со списком всех имеющихся на сайте директив. Кликните на любую из них, чтобы ознакомиться со страницами, на которых они были найдены.
При необходимости вы можете воспользоваться функцией «Экспорт», чтобы выгрузить отфильтрованные результаты в отдельный файл формата на свой компьютер. Нажмите на кнопку «Экспорт» в левом верхнем углу над результатами сканирования или выберите в соответствующем меню команду «Результаты в текущей таблице».
Example Meta Tags
A Meta Tag usually takes the form of:
Meta Tag Format:
<meta name=»MetaTagName» content=»Data specific to the name» />
The tag type of ‘meta’ designates it as a meta tag, of course. The name attribute offers a unique field that designates what the data represents and categorizes it. The content field represents the meta data presented on that particular page for, or as a function of, that name. Other optional attributes of the meta tag that may show-up include http-equiv.
Many webmasters often try to optimize the img tag by putting the alt text string before the actual img src path. As an example, they will optimize the following img tag code:
Standard IMG Tag Format:
<img src=»/path/to/img.jpg» alt=»keyword rich description of image» />
Optimizing it by rewriting it with the textual content that a spider would crawl in front, allowing them more immediate access to it…
Optimized IMG Tag Format:
<img alt=»keyword rich description of image» src=»/path/to/img.jpg» />
However, this optimization technique is questionable and simply does not work as expected with meta tags. This is because most Meta Search Engines and Meta Aware Directories will choke when they see the code rewritten differently, as in the example below…
Broken Meta Tag:
<meta content=»Data specific to the name» name=»MetaTagName» />
-Do NOT use this form to write a meta tag, it’s very bad and breaks the meta tag (all of them that are written in this manner) for many meta search engines.
So, always put the name of the meta tag first, as they are traditionally written. Otherwise, you will find yourself rewriting them to this format later when your submissions are rejected by certain (and important) Meta Search Engines, such as ScrubTheWeb.
Now that we understand how not to optimize these meta tags, let’s take a look at how they function by exploring a list of example meta tags that are often found on web pages.
Example Meta Tag Set:
Директивы Meta Robots, которые стоит использовать в SEO
Как мы видим из предыдущей таблицы, не все атрибуты метатега Robots поддерживаются поисковой системой Google, под которую оптимизируют сайты большинство разработчиков и SEO-специалистов. Поэтому рассмотрим те атрибуты метатега Robots, которые поддерживаются Google:
- nosnippet,
- noimageindex,
- noarchive,
- unavailable_after.
Все они прописываются в блоке страницы, к которой вы хотите применить те или иные инструкции по индексации.
Nosnippet
Для решения проблемы вам следует использовать инструкцию следующего вида:
Также важно учитывать, что атрибут nosnippet отключает и отображение расширенных сниппетов в результатах поиска. К тому же, исследование HubSpot показало, что сниппеты с расширенной информацией получают в два раза больше кликов
Соответственно, отключение сниппета может стать причиной снижения CTR вашего сайта или отдельных его страниц
К тому же, исследование HubSpot показало, что сниппеты с расширенной информацией получают в два раза больше кликов. Соответственно, отключение сниппета может стать причиной снижения CTR вашего сайта или отдельных его страниц.
Noimageindex
Директива noimageindex позволит скрыть графический контент на вашем сайте из результатов поиска по картинкам. Это может быть полезно, если вы, к примеру, хотите разместить на своём блоге уникальные изображения и при этом минимизировать риск воровства.
Чтобы запретить поисковым системам индексировать изображения, задайте в блоке html-документа следующую директиву:
Действие необходимо повторить с каждой страницей, которая содержит изображения, которые вы хотите скрыть от поисковиков. Учитывайте, что если другие сайты уже ссылались на ваши изображения, поисковики могут продолжать индексировать их.
Запрещая индексацию изображений, не забывайте о том, что поиск по картинкам может приносить хороший дополнительный трафик вашему сайту.
Noarchive
Вопреки распространённому мнению, директива noarchive никак не влияет на ранжирование — эту информацию подтвердил в своем Твиттере ведущий аналитик компании Google, специалист отдела качества поиска по работе с вебмастерами Джон Мюллер (John Mueller).
Директива unavailable_after наиболее актуальна для страниц с акционными предложениями. Так как по истечению времени действия акции они теряют свою актуальность, вы можете указать поисковикам дату крайнего срока индексации контента. Дату и время нужно указывать в формате RFC 850.
К примеру, если вам нужно исключить возможность индексации страницы после 25 марта 2019 года, используйте метатег следующего вида:
Отдельно отметим, что для правильного функционирования тега необходимо, чтобы он был прописан до первого обхода роботом. В таком случае запрос на удаление из поисковой выдачи займёт примерно сутки после указанной даты.
Неправильная кодировка результатов из базы данных MySQL
Если ваш сайт состоит из статической части (шаблон) и динамической, которая формируется из данных, получаемых из базы данных, то может возникнуть ситуация, когда часть сайта имеет правильную кодировку, а другая часть сайта имеет неправильную. В этом случае бесполезно менять настройки веб-сервера – поскольку всё равно часть страницы будет иметь неправильную кодировку.
Нужно начать с определения кодировки ваших таблиц. Можно посмотреть в phpMyAdmin:
Обратите внимание на столбец «Сравнение», запись «utf8_unicode_ci» означает, что используется кодировка UTF-8.
Можно подключиться к СУБД MySQL и проверить кодировку таблиц без phpMyAdmin. Для этого:
mysql -u root -p
Если вы забыли имя базы данных, то выполните команду:
SHOW DATABASES;
Предположим, я хочу посмотреть кодировку для таблиц в базе данных information_schema
USE information_schema;
Если вы забыли имя таблиц, выполните:
SHOW TABLES;
Далее выполните команду, в которой имя_таблицы замените на настоящее имя таблицы:
SHOW FULL COLUMNS FROM имя_таблицы;
Например:
SHOW FULL COLUMNS FROM GLOBAL_STATUS;
Вы увидите примерно следующее:
Смотрите столбец Collation. В моём случае там utf8_general_ci, это, как и utf8_unicode_ci, кодировка UTF-8. Кстати, если вы не знаете в чём разница между кодировками utf8_general_ci, utf8_unicode_ci, utf8mb4_general_ci, utf8mb4_unicode_ci, а также какую кодировку выбрать для базы данных MySQL, то посмотрите эту статью.
Теперь, когда мы узнали кодировку (в моём случае это UTF-8), то при каждом подключении к СУБД MySQL нужно выполнять последовательно запросы:
SET NAMES UTF8 SET CHARACTER SET UTF8 SET character_set_client = UTF8 SET character_set_connection = UTF8 SET character_set_results = UTF8
В PHP это можно сделать примерно так:
$this->mysqli = new mysqli($server, $username, $password, $basename);
if ($this->mysqli->connect_error) {
$this->errorHandler_c->logError(1, 'Connect Error (' . $this->mysqli->connect_errno . ') ' . $this->mysqli->connect_error, $_SERVER );
}
$this->mysqli->query("SET NAMES UTF8");
$this->mysqli->query("SET CHARACTER SET UTF8");
$this->mysqli->query("SET character_set_client = UTF8");
$this->mysqli->query("SET character_set_connection = UTF8");
$this->mysqli->query("SET character_set_results = UTF8");
Обратите внимание, что UTF8 вам нужно заменить на ту кодировку, которая используется для ваших таблиц.
JavaScript
JS Array
concat()
constructor
copyWithin()
entries()
every()
fill()
filter()
find()
findIndex()
forEach()
from()
includes()
indexOf()
isArray()
join()
keys()
length
lastIndexOf()
map()
pop()
prototype
push()
reduce()
reduceRight()
reverse()
shift()
slice()
some()
sort()
splice()
toString()
unshift()
valueOf()
JS Boolean
constructor
prototype
toString()
valueOf()
JS Classes
constructor()
extends
static
super
JS Date
constructor
getDate()
getDay()
getFullYear()
getHours()
getMilliseconds()
getMinutes()
getMonth()
getSeconds()
getTime()
getTimezoneOffset()
getUTCDate()
getUTCDay()
getUTCFullYear()
getUTCHours()
getUTCMilliseconds()
getUTCMinutes()
getUTCMonth()
getUTCSeconds()
now()
parse()
prototype
setDate()
setFullYear()
setHours()
setMilliseconds()
setMinutes()
setMonth()
setSeconds()
setTime()
setUTCDate()
setUTCFullYear()
setUTCHours()
setUTCMilliseconds()
setUTCMinutes()
setUTCMonth()
setUTCSeconds()
toDateString()
toISOString()
toJSON()
toLocaleDateString()
toLocaleTimeString()
toLocaleString()
toString()
toTimeString()
toUTCString()
UTC()
valueOf()
JS Error
name
message
JS Global
decodeURI()
decodeURIComponent()
encodeURI()
encodeURIComponent()
escape()
eval()
Infinity
isFinite()
isNaN()
NaN
Number()
parseFloat()
parseInt()
String()
undefined
unescape()
JS JSON
parse()
stringify()
JS Math
abs()
acos()
acosh()
asin()
asinh()
atan()
atan2()
atanh()
cbrt()
ceil()
clz32()
cos()
cosh()
E
exp()
expm1()
floor()
fround()
LN2
LN10
log()
log10()
log1p()
log2()
LOG2E
LOG10E
max()
min()
PI
pow()
random()
round()
sign()
sin()
sqrt()
SQRT1_2
SQRT2
tan()
tanh()
trunc()
JS Number
constructor
isFinite()
isInteger()
isNaN()
isSafeInteger()
MAX_VALUE
MIN_VALUE
NEGATIVE_INFINITY
NaN
POSITIVE_INFINITY
prototype
toExponential()
toFixed()
toLocaleString()
toPrecision()
toString()
valueOf()
JS OperatorsJS RegExp
constructor
compile()
exec()
g
global
i
ignoreCase
lastIndex
m
multiline
n+
n*
n?
n{X}
n{X,Y}
n{X,}
n$
^n
?=n
?!n
source
test()
toString()
(x|y)
.
\w
\W
\d
\D
\s
\S
\b
\B
\0
\n
\f
\r
\t
\v
\xxx
\xdd
\uxxxx
JS Statements
break
class
continue
debugger
do…while
for
for…in
for…of
function
if…else
return
switch
throw
try…catch
var
while
JS String
charAt()
charCodeAt()
concat()
constructor
endsWith()
fromCharCode()
includes()
indexOf()
lastIndexOf()
length
localeCompare()
match()
prototype
repeat()
replace()
search()
slice()
split()
startsWith()
substr()
substring()
toLocaleLowerCase()
toLocaleUpperCase()
toLowerCase()
toString()
toUpperCase()
trim()
valueOf()
Setting the Viewport
The viewport is the user’s visible area of a web page. It varies with the device
— it will be smaller on a mobile phone than on a computer screen.
You should include the following element in all your web pages:
<meta name=»viewport» content=»width=device-width, initial-scale=1.0″>
This gives the browser instructions on how
to control the page’s dimensions and scaling.
The part sets the width of the page to follow the screen-width of the device (which will vary depending on the device).
The part sets the initial zoom level when the page is first loaded by the browser.
Here is an example of a web page without the viewport meta tag, and the same web page with the viewport meta tag:
Tip: If you are browsing this page with a phone or a tablet, you can click on the two links below to see the difference.
Without the
viewport meta tag
With the
viewport meta tag
You can read more about the viewport in our Responsive Web Design — The Viewport Tutorial.
Группа значений атрибута NAME
«keywords» (ключевые слова)
Keywords поисковые системы используют для того, чтобы определить релевантность страницы тому или иному запросу. При формировании данного значения необходимо использовать только те слова, которые обязательно встречаются в самом документе. Использование тех слов, которых нет на странице, не рекомендуется. Ключевые слова нужно добавлять по одному, через запятую, в единственном числе. Рекомендованное количество слов в «keywords» — не более десяти. Кроме того, выявлено, что разбивка этого значения на несколько строк влияет на оценку ссылки поисковыми машинами. Некоторые поисковые системы не индексируют сайты, в которых в значении «keywords» повторяется одно и то же слово для увеличения позиции в списке результатов.
Если раньше «keywords» имел определённую роль в ранжировании сайта, то в последнее время поисковые системы относятся к нему нейтрально.
HTML-код с «keywords»:
«description» (описание страницы)
Description используется при создании краткого описания конкретной страницы Вашего сайта. Практически все поисковые системы учитывают его при индексации, а также при создании аннотации в выдаче по запросу. При отсутствии «description» поисковые системы выдают в аннотации первую строку документа или отрывок, содержащий ключевые слова. Отображается после ссылки при поиске страниц в поисковике, поэтому желательно не просто указывать краткое описание документа, но сделать его содержание привлекательным рекламным сообщением.
Таким образом, правильный description обязательно должен содержать ключевое слово, коротко и точно описывать то, о чём данная веб-страница. «Description» вместе с «title» образуют очень важную пару значений, от которых зависит то, перейдёт пользователь из поисковой выдачи на веб-страницу или нет! Поэтому «description» и «title» нужно прописывать для каждой веб-страницы!
HTML-код с «description»:
«Author» и «Copyright»
Эти значения, как правило, не используются одновременно. Функция author и copyright — идентификация автора или принадлежности контента на странице. «Author» содержит имя автора веб-страницы, но в случае, если веб-сайт принадлежит какой-либо организации, целесообразнее использовать значение «Copyright».
HTML-код с «author»:
«Robots»
Robots — формирует информацию о гипертекстовых документах, которая поступает к роботам поисковых систем.
У «robots» могут быть следующие значения:
- index — страница должна быть проиндексирована;
- noindex — страница не индексируется;
- follow — гиперссылки на странице учитываются;
- nofollow — гиперссылки на странице не учитываются
- all — включает значения index и follow, включен по умолчанию;
- none — включает значения noindex и nofollow.
HTML-код с «robots»:
The Rating Meta Tag
The rating meta tag alerts search engines that your content is intended for general audiences, or if it should bear a restricted nature of some kind.
Example Rating Meta Tag:
<meta name=»rating» content=»General» />
Since I only design family friendly websites that are intended for viewing by everyone, I specify that it is appropriate for general audiences. If however, you are marketing your information, products and/or services to kids, you should get one of the kid-safe rating tags. You should also get one if you are creating adult sites in an effort to keep the young and innocent away from adult materials.
Usage in Social Media (Open Graph, Twitter Cards, and Schema.org)
With the ever-increasing relevancy of social networks, meta tags have evolved. Facebook’s Open Graph allows you to specify how your content is displayed on a user’s timeline. These tags can enable you to check how your data was shared on Facebook using Insights.
For further reading, I suggest you go through Facebook’s Open Graph documentation.
Similar to Open Graph, Twitter has Twitter cards (using or ) and Google+ uses Schema.org (using and ).
Open Graph has become very popular, so most social networks default to Open Graph if no other meta tags are present. If Open Graph meta tags are absent as well, they assume default values for the absent meta tags.
Тег
Noindex – тег, с помощью которого можно управлять функцией индексации поискового робота. Если выделить отдельный фрагмент текста и закрыть его тегом noindex, он не будет проиндексирован поисковой системой и, соответственно, не попадет в ее кэш. Впервые данный инструмент был предложен специалистами Яндекса, чтобы у веб-мастеров появился простой способ отделения части текстового контента, которая не несет смысловой нагрузки и не должна учитываться при оценке страницы.
<noindex>Здесь находится закрытый для индексации контент</noindex>
Тег noindex учитывает только Яндекс. Google игнорирует его присутствие и проводит полную индексацию текстового содержания страницы. Для задействования блокировки индексации, актуальной для всех поисковиков, следует прописывать соответствующий метатег для отдельных страниц или всего сайта в файле robots.txt. Недостаток данного способа очевиден: запрет на индексацию возможен только по отношению ко всей странице, но не отдельному текстовому фрагменту.
Преимущества тега noindex
- Сокрытие второстепенной информации позволяет повысить релевантность индексируемой страницы за счет возрастания относительной плотности ключевых фраз.
- С помощью noindex можно спрятать содержимое сквозных блоков, информация в которых будет дублироваться на нескольких страницах, что отразится на пессимизации сайта в поисковой выдаче Yandex.
- В некоторых случаях в сниппет может попасть нежелательная или служебная информация, которую проще всего скрыть тегом noindex.
Принцип действия noindex
Noindex может находиться в любом месте HTML-кода вне зависимости от уровня вложенности.
Несмотря на тот факт, что noindex был изначально предложен разработчиками Yandex, использование данного инструмента может быть расценено в качестве серого метода оптимизации. Это связано с тем, что некоторые веб-мастера применяют его не по прямому назначению. В частности, от робота прячется неуникальный контент или качественный текст, не содержащий ключевых слов, рассчитанный на прочтение посетителем сайта. Одновременно поисковику предлагается насыщенный ключевыми фразами текст, тяжелый для восприятия человека.
Для борьбы с подобными методами оптимизации Yandex анализирует текст, закрытый тегом noindex, проводя его индексацию, но впоследствии отфильтровывая скрытое содержимое. В результате изучения контента страницы поисковик может принять решение о наложении санкций на сайт, если сочтет, что его владелец использует неправомерные способы влияния на результаты поисковой выдачи.
Группа значений атрибута NAME
«keywords» (ключевые слова)
Keywords поисковые системы используют для того, чтобы определить релевантность страницы тому или иному запросу. При формировании данного значения необходимо использовать только те слова, которые обязательно встречаются в самом документе. Использование тех слов, которых нет на странице, не рекомендуется. Ключевые слова нужно добавлять по одному, через запятую, в единственном числе. Рекомендованное количество слов в «keywords» — не более десяти. Кроме того, выявлено, что разбивка этого значения на несколько строк влияет на оценку ссылки поисковыми машинами. Некоторые поисковые системы не индексируют сайты, в которых в значении «keywords» повторяется одно и то же слово для увеличения позиции в списке результатов.
Если раньше «keywords» имел определённую роль в ранжировании сайта, то в последнее время поисковые системы относятся к нему нейтрально.
HTML-код с «keywords»:
«description» (описание страницы)
Description используется при создании краткого описания конкретной страницы Вашего сайта. Практически все поисковые системы учитывают его при индексации, а также при создании аннотации в выдаче по запросу. При отсутствии «description» поисковые системы выдают в аннотации первую строку документа или отрывок, содержащий ключевые слова. Отображается после ссылки при поиске страниц в поисковике, поэтому желательно не просто указывать краткое описание документа, но сделать его содержание привлекательным рекламным сообщением.
Таким образом, правильный description обязательно должен содержать ключевое слово, коротко и точно описывать то, о чём данная веб-страница. «Description» вместе с «title» образуют очень важную пару значений, от которых зависит то, перейдёт пользователь из поисковой выдачи на веб-страницу или нет! Поэтому «description» и «title» нужно прописывать для каждой веб-страницы!
HTML-код с «description»:
«Author» и «Copyright»
Эти значения, как правило, не используются одновременно. Функция author и copyright — идентификация автора или принадлежности контента на странице. «Author» содержит имя автора веб-страницы, но в случае, если веб-сайт принадлежит какой-либо организации, целесообразнее использовать значение «Copyright».
HTML-код с «author»:
«Robots»
Robots — формирует информацию о гипертекстовых документах, которая поступает к роботам поисковых систем.
У «robots» могут быть следующие значения:
- index — страница должна быть проиндексирована;
- noindex — страница не индексируется;
- follow — гиперссылки на странице учитываются;
- nofollow — гиперссылки на странице не учитываются
- all — включает значения index и follow, включен по умолчанию;
- none — включает значения noindex и nofollow.
HTML-код с «robots»:
Adding Meta Tags to Your Documents
You can add metadata to your web pages by placing <meta> tags inside the header of the document which is represented by <head> and </head> tags. A meta tag can have following attributes in addition to core attributes −
| Sr.No | Attribute & Description |
|---|---|
| 1 |
Name Name for the property. Can be anything. Examples include, keywords, description, author, revised, generator etc. |
| 2 |
content Specifies the property’s value. |
| 3 |
scheme Specifies a scheme to interpret the property’s value (as declared in the content attribute). |
| 4 |
http-equiv Used for http response message headers. For example, http-equiv can be used to refresh the page or to set a cookie. Values include content-type, expires, refresh and set-cookie. |
Obsolete Usage
The tag usage has evolved over the years and there are certain popular practices from years ago that should not be followed today. For instance:
That’s the longer version of the character encoding that was common in XHTML. Shortening it to what we discussed above is sufficient.
Meta tags have also been used to indicate copyrights.
This can be improved by instead providing a link tag pointing to a copyright page (or an anchor on the same page).
Finally, although many websites still use the value of the attribute, Google will not consider this in its search ranking algorithm or when displaying search results. In fact, Google has never considered keywords in its search algorithm.
Google has said that it is extremely unlikely that this will change in the future, so you shouldn’t bother with the keywords meta tags.
But an important factor, as pointed out earlier, is the fact that Baidu’s Chinese-language search engine considers the keywords meta tag a major factor in its search algorithm. So if you expect that a significant part of your traffic is coming from Chinese-language users, then you should include the keywords meta tag — but always be careful not to use unnecessary and unethical keyword stuffing.
Having said all of this, it won’t hurt your ranking to use any of these obsolete methods, but they will often add unnecessary code to your page, so it’s best to just avoid them and use alternative methods.
The Distribution Meta Tag
The distribution meta tag is not necessary unless you are seeking an international audience and want to make sure you reach it, or you only want to be listed for local searches (perhaps because you are a mom & pop store that doesn’t ship).
Example Global Distribution Meta Tag:
<meta name=»distribution» content=»Global» />
The above example tells the visiting bot to make this page available on a global scale to all users, worldwide, searching with the web page’s active language.
Example Regional Distribution Meta Tag:
<meta name=»distribution» content=»Sioux Falls,SD,South Dakota» />
The above regional distribution meta specifies a local, the largest town in South Dakota, and the state itself both by abbreviation and name (to cover variances in search engine preferences). This example tells the search engine only to offer your web page’s listing in results for users in a specific state or a specific town. You can list multiple regions (separated by commas), or just specify a country, as well.
The Robots Meta Tag
One thing that search engines look for is a ‘robots.txt’ file that can list the pages that they are allowed to index. An easy alternative to creating a robots indexing instruction file is to include your instruction in a robots meta tag for each page.
Example Robots Meta Tag:
<meta name=»robots» content=»index, follow» />
The above example tells all search engine bots that they can index this page and follow the links on the page to any other page listed on the page, as well.
To instruct robots to not index and don’t follow any of the links on the page, you would replace the robots meta tag content with the text string «noindex, nofollow».
Something to note is that by default, search engines will assume that they can «index, follow» the page and the links on it.