Мета теги страниц сайта: title, description, keywords, robots и другие
Содержание:
- How to Set Up Robots Meta Tags and X‑Robots-Tag
- Что такое файл Robots.txt?
- Мета-тег
- X-robots-tag
- Robots.txt & Meta Robots Tags Work Together
- Viewport мета тег
- What Is Robots.txt?
- What Are Robots Meta Tags?
- Meta Robots Tag Code Examples
- Мета тег description
- Что изменилось с вводом поддержки rel=nofollow?
- Why Is Robots.txt Important?
- NOFOLLOW в ссылках
- Влияние внутренних ссылок на индексацию сайта
- Как с помощью расширения обнаружить статьи с мета-тегом?
- На мой странице (не) обнаружен мета-тег, а страница (не) видна в поиске
- Что такое мета тег Robots
- Лучшие примеры использования
- Мета тег title
- Выводы
- Итоги — или что сделать, чтобы стало все круто?
How to Set Up Robots Meta Tags and X‑Robots-Tag
Setting up robots meta tags is, generally, easier than the x-robots-tag, but the implementation of both methods of controlling how search engines crawl and index your site can differ depending on your CMS and/or server type.
Here’s how yo use meta robots tags and the x-robots-tag on common setups:
Using Robots Meta Tags in HTML Code
If you can edit your page’s HTML code, simply add your robots meta tags straight into the <head> section of the page.
If you want search engines not to index the page but want links to be followed, as an example, use:
Using Robots Meta Tags on WordPress
If you’re using Yoast SEO, open up the ‘advanced’ tab in the block below the page editor.
You can set the «noindex» directive by setting the «Allow search engines to show this page in search results?» dropdown to no or prevent links from being followed by setting the «Should search engines follow links on this page?» to no.
For any other directives, you will need to implement these in the «Meta robots advanced» field.
If you’re using RankMath, you can select the robots directives that you wish apply straight from the Advanced tag of the meta box:
Image courtesy of RankMath
Using Robots Meta Tags on Shopify
If you need to implement robots meta tags on Shopify, you’ll need to do this by editing the <head> section of your theme.liquid layout file.
To set the directives for a specific page, add the below code to this file:
This code will instruct search engines, not to index /page-name/ but to follow all of the links on the page.
You will need to make separate entries to set the directives across different pages.
Using X-Robots-Tag on an Apache Server
To use the x-robots-tag on an Apache web server, add the following to your site’s .htaccess file or httpd.config file.
The example above sets the file type of .pdf and instructs search engines not to index the file but to follow any links on it.
Using X-Robots-Tag on an Nginx Server
If you’re running an Nginx server, add the below to your site’s .conf file:
This will apply a noindex attribute and follow any links on a .pdf file.
Что такое файл Robots.txt?
Robots.txt – это файл, который указывает поисковым роботам (например, Googlebot и Bingbot), какие страницы сайта не должны сканироваться.
Чем полезен файл Robots.txt?
Файл robots.txt сообщает роботам системам, какие страницы могут быть просканированы. Но не может контролировать их поведение и скорость сканирования сайта. Этот файл, по сути, представляет собой набор инструкций для поисковых роботов о том, к каким частям сайта доступ ограничен.
Но не все поисковые системы выполняют директивы файла robots.txt. Если у вас остались вопросы насчет robots.txt, ознакомьтесь с часто задаваемыми вопросами о роботах.
Как создать файл Robots.txt?
По умолчанию файл robots.txt выглядит следующим образом:
Можно создать свой собственный файл robots.txt в любом редакторе, который поддерживает формат .txt. С его помощью можно заблокировать второстепенные веб-страницы сайта. Файл robots.txt – это способ сэкономить лимиты, которые могут пойти на сканирование других разделов сайта.
Директивы для сканирования поисковыми системами
User-Agent: определяет поискового робота, для которого будут применяться ограничения в сканировании URL-адресов. Например, Googlebot, Bingbot, Ask, Yahoo.
Disallow: определяет адреса страниц, которые запрещены для сканирования.
Allow: только Googlebot придерживается этой директивы. Она разрешает анализировать страницу, несмотря на то, что сканирование родительской веб-страницы запрещено.
Sitemap: указывает путь к файлу sitemap сайта.
Правильное использование универсальных символов
В файле robots.txt символ (*) используется для обозначения любой последовательности символов.
Директива для всех типов поисковых роботов:
User-agent:*
Также символ * можно использовать, чтобы запретить все URL-адреса кроме родительской страницы.
User-agent:*
Disallow: /authors/*
Disallow: /categories/*
Это означает, что все URL-адреса дочерних страниц авторов и страниц категорий заблокированы за исключением главных страниц этих разделов.
Ниже приведен пример правильного файла robots.txt:
User-agent:* Disallow: /testing-page/ Disallow: /account/ Disallow: /checkout/ Disallow: /cart/ Disallow: /products/page/* Disallow: /wp/wp-admin/ Allow: /wp/wp-admin/admin-ajax.php Sitemap: yourdomainhere.com/sitemap.xml
После того, как отредактируете файл robots.txt, разместите его в корневой директории сайта. Благодаря этому поисковый робот увидит файл robots.txt сразу после захода на сайт.
Мета-тег
Начнем с базовых пониманий. Мета-тег — это служебная информация для страницы, которая указывается в документе в верхнем блоке <head></head> с HTML разметкой.
Что такое мета-тег robots?
В нашем случае, мета-тег с атрибутом name=“robots” дает указание роботам всех поисковых систем, без исключения. Так же, есть name=“googlebot”, виден только Google, и name=“yandex”, соответственно только для Yandex поисковика.
В коде это выглядит так:
<!DOCTYPE html> <html><head> <meta name="robots" content="noindex" /> (…) </head> <body>(…)</body> </html>
Атрибут content может принимать такие параметры как:
- “noindex” — ставит запрет на индексацию контента, но ссылки в документе все еще видны для поисковых роботов и открыты для просмотров и переходов на них
- “nofollow” — закрывает все ссылки на данной странице от индексации. Это касается как внешних, так и внутренних.
Варианты использования meta тега robots с noindex и nofollow
Возможны такие варианты использования:
<meta name="robots" content="index, follow"/> <!-- — включена индексация страницы и ссылок. Стоит по умолчанию для каждого сайта. --> <meta name="robots" content="noindex, follow"/> <!-- — запрет на индексацию контента страницы, но разрешен переход и просмотр ссылок. --> <meta name="robots" content="index, nofollow"/> <!-- — включена индексация, но запрещен переход и просмотр ссылок. --> <meta name="robots" content="noindex, nofollow"/> <!-- — запрет на индексацию и переход по ссылкам страницы. -->
Перечисленные варианты также можно использовать для скрытия от определенных поисковых систем, таких как Yandex и Google. Возможные варианты атрибута name видно выше, а в коде это может выглядеть так:
<meta name="googlebot" content="noindex, follow" />.
Стоит подбирать комбинацию атрибутов четко под свои цели и задачи. Давайте рассмотрим некоторые из них.
Когда нам нужен мета-тег “robots” со значением “noindex” или “nofollow”?
Мета-тег следует использовать на следующих страницах:
- со служебной информацией(админ. панель, логи сервера);
- дублирующийся контент(пагинация, архивы, теги).
А также в случаях:
- когда следует закрыть страницу от индексирования, но оставить возможность просматривать ссылки;
- когда хотите удалить документ из index и не допустить просмотра ссылок поисковыми роботами;
- когда нужно закрыть переход по ссылкам уже индексированного документа.
Рекомендуем
Операторы поиска Google
Подробнее
X-robots-tag
While the meta robots tag allows you to control indexing behavior at the page level, the x-robots-tag can be included as part of the HTTP header to control indexing of a page as a whole, as well as very specific elements of a page.
While you can use the x-robots-tag to execute all of the same indexation directives as meta robots, the x-robots-tag directive offers significantly more flexibility and functionality that the meta robots tag does not. Specifically, the x-robots permits the use of regular expressions, executing crawl directives on non-HTML files, and applying parameters at a global level.

To use the x-robots-tag, you’ll need to have access to either your website’s header .php, .htaccess, or server access file. From there, add your specific server configuration’s x-robots-tag markup, including any parameters. This article provides some great examples of what x-robots-tag markup looks like if you’re using any of these three configurations.
Here are a few use cases for why you might employ the x-robots-tag:
-
Controlling the indexation of content not written in HTML (like flash or video)
-
Blocking indexation of a particular element of a page (like an image or video), but not of the entire page itself
-
Controlling indexation if you don’t have access to a page’s HTML (specifically, to the <head> section) or if your site uses a global header that cannot be changed
-
Adding rules to whether or not a page should be indexed (ex. If a user has commented over 20 times, index their profile page)
Robots.txt & Meta Robots Tags Work Together
One of the biggest mistakes I see when working on my client’s websites is when the robots.txt file doesn’t match what you’ve stated in the meta robots tags.
For example, the robots.txt file hides the page from indexing, but the meta robots tags do the opposite.
Remember the example from Leadfeeder I showed above?
So, you’ll notice that this thank you page is disallowed in the robots.txt file and using the meta robots tags of noindex, nofollow.
In my experience, Google has given priority to what is prohibited by the robots.txt file.
But, you can eliminate non-compliance between meta robots tags and robots.txt by clearly telling search engines which pages should be indexed, and which should not.
Viewport мета тег
Метатег Viewport позволяет вам настроить, как страница будет масштабироваться и отображаться на любом устройстве. Обычно этот тег и его значение выглядят следующим образом:
Где «width=device-width» заставляет страницу соответствовать ширине экрана в пикселях, независимо от устройства, а «initial-scale=1» устанавливает соотношение 1:1 между пикселями CSS и пикселями устройства, с учётом ориентации экрана.
Этот тег легко добавить, и одного скриншота из Google достаточно, чтобы показать разницу:
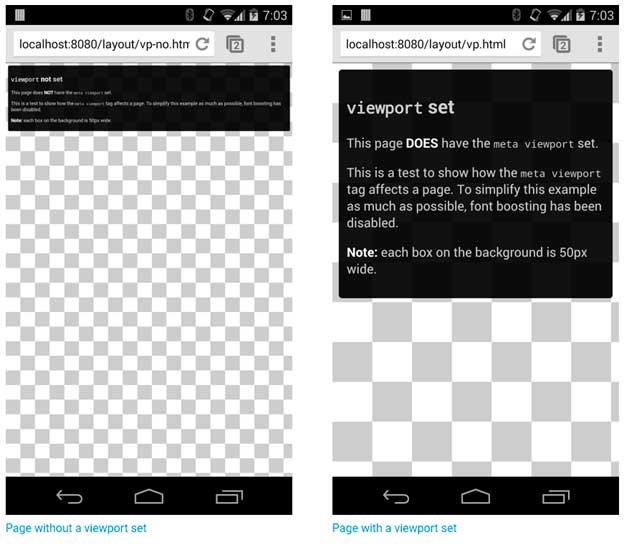
Мета тег Viewport не имеет ничего общего с ранжированием, но напрямую влияет на пользовательский опыт
Это особенно важно, учитывая разнообразие устройств, которыми люди пользуются в настоящее время, и знаменитый переход Google на индексирование с приоритетом мобильного контента
Как и в случае со многими тегами и настройками, которые мы с вами обсуждали в этой статье, заботу о метатеге области просмотра ваши пользователи по достоинству оценят. В противном случае ждите ухудшения показателя отказов и негативных отзывов.
What Is Robots.txt?
A robots.txt file tells crawlers what should be crawled.
It’s part of the robots exclusion protocol (REP).
Googlebot is an example of a crawler.
Google deploys Googlebot to crawl websites and record information on that site to understand how to rank the site in Google’s search results.
You can find any site’s robots.txt file by add /robots.txt after the web address like this:
www.mywebsite.com/robots.txt
Here is what a basic, fresh, robots.txt file looks like:
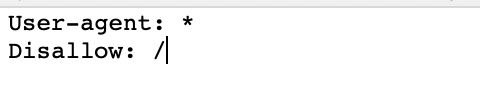
The asterisk * after user-agent tells the crawlers that the robots.txt file is for all bots that come to the site.
Advertisement
Continue Reading Below
The slash / after “Disallow” tells the robot to not go to any pages on the site.
Here is an example of Moz’s robots.txt file.

You can see they are telling the crawlers what pages to crawl using user-agents and directives. I’ll dive into those a little later.
What Are Robots Meta Tags?
A Robots meta tag, also known as robots tags, is a piece of HTML code that’s placed in the <head></head> section of a web page and is used to control how search engines crawl and index the URL.
This is what a robots meta tag looks like in the source code of a page:
These tags are page-specific and allow you to instruct search engines on how you want them to handle the page and whether or not to include it in the index.
What Are Robots Meta Tags Used For?
Robots meta tags are used to control how Google indexes your web page’s content. This includes:
- Whether or not to include a page in search results
- Whether or not to follow the links on a page (even if it is blocked from being indexed)
- Requests not to index the images on a page
- Requests not to show cached results of the web page on the SERPs
- Requests not to show a snippet (meta description) for the page on the SERPs
In order to understand how you can use the robots meta tag, we need to look at the different attributes and directives. We’ll also share code examples that you can take and drop into your page’s header to request the search engines to index your page in a certain way.
Run a Technical Site Audit
with the Semrush Site Audit Tool
Try for Free →
Try for Free →
Meta Robots Tag Code Examples
If you’re looking for meta robots tag examples that you can use to control how the search engines crawl and index your web pages, you can use the below that looks at the most common use scenarios:
Do not index the page but follow the links to other pages:
Do not index the page and do not follow the links to other pages:
Index the page but do not follow the links to other pages:
Do not show a copy of the page cache on the SERPs:
Do not index the images on a page:
Do not show the page on the SERPs after a specified date/time:
If needed, you can combine directives into a single tag, separating these with commas.
As an example, let’s say you don’t want any of the links on a page to be followed and also want to prevent the images from being indexed. Use:
Мета тег description
Мета-описание (meta description) – также находится в <head> веб-страницы и обычно (хотя далеко не всегда) отображается в сниппете поисковой выдачи вместе с заголовком и URL-адресом страницы.
Например, это мета-описание данной статьи:
И да, само по себе метаописание не является фактором ранжирования. Но для любого вебмастера, старающегося увеличить количество переходов из поиска и улучшить поисковую выдачу своего бренда, это уникальная возможность.
Description занимает большую часть сниппета поисковой выдачи и приглашает пользователей щёлкнуть именно по вашей ссылке, обещая чёткое и комплексное решение их запроса.
Описание влияет на количество получаемых вами кликов, а также может улучшить CTR и снизить показатель отказов, если содержание страницы действительно соответствует обещаниям. Вот почему описание должно быть в равной степени реалистичным, привлекательным и чётко отражать содержание.
Если ваше описание содержит ключевые слова, использованные человеком в своём поисковом запросе, они будут выделены в поисковой выдаче жирным шрифтом
Это помогает вам привлечь внимание и сообщить пользователю, что именно он найдёт на вашей странице.
Невозможно поместить каждое ключевое слово, по которому вы хотите ранжироваться, в мета-описание, и в этом нет реальной необходимости – вместо этого напишите пару связных предложений, описывающих суть вашей страницы, включая основные ключевые слова.
Лучший способ выяснить, что необходимо поместить в мета тег Description для эффективного ранжирования – провести анализ конкурентов. Вбейте главный поисковый запрос вашей будущей или текущей страницы в Яндекс и Google. Посмотрите, кто и как заполнил описание, и возьмите себе всё самое лучшее из топа.
Мета совет
Мета-описание не обязательно должно состоять из одного-двух предложений. Вы можете добавить дополнительную информацию о странице, которая обрабатывается поисковиками и позволит выделиться в SERP.
Например:
- Для авторской статьи вы можете добавить дату публикации, имя автора.
- На странице продукта вы можете указать цену и дату изготовления товара.
Что изменилось с вводом поддержки rel=nofollow?
- Для тех, кто ведет ресурсы для людей и не использует спам-продвижения, почти ничего не изменится. Возможно некоторое уменьшение числа внешних ссылок, закрытых с rel=»nofollow».
- Для тех, кто использовал в продвижении ссылочный спам (спам в комментариях, спам в форумах, соц. сетях, Википедии и т.д), и у кого основная ссылочная масса, дающая ТИЦ, состояла из таких ссылок, будет существенное снижение ТИЦ и как правило, проседание в поисковой выдаче Yandex.
Кратко, о новинках апреля 2010 года в Яндекс:
- У страницы поисковой выдачи Яндекс теперь фиксированная ширина.
- Появились в выдаче навигационные цепочки, у некоторых сниппетов и даты публикации.
- Появился колдунщик видео.
- В панели веб-мастера появилась возможность просмотра статистики по собственным ключевым словам.
P.S. Теперь осталось дождаться включения поддержки Яндексом канонического атрибута rel=»canonical», о котором я писал в статье о дублированном контенте, и многие блогеры вздохнут с облегчением.
Хорошая новость, в конце мая 2011г. Яндекс стал учитывать атрибут rel=»canonical». Принесет это облегчение или нет, покажет время.
Why Is Robots.txt Important?
I can’t tell how many clients come to me after a website migration or launching a new website and ask me: Why isn’t my site ranking after months of work?
I’d say 60% of the reason is that the robots.txt file wasn’t updated correctly.
Meaning, your robots.txt file still looks like this:
This will block all web crawlers are visiting your site.
Another reason robots.txt is important is that Google has this thing called a crawl budget.
Google states:
Advertisement
Continue Reading Below
So, if you have a big site with low-quality pages that you don’t want Google to crawl, you can tell Google to “Disallow” them in your robots.txt file.
This would free up your crawl budget to only crawl the high-quality pages you want Google to rank you for.
There are no hard and fast rules for robots.txt files…yet.
Google announced a proposal in July 2019 to begin implementing certain standards, but for now, I’m following the best practices I’ve done for the past few years.
NOFOLLOW в ссылках
Nofollow используется как значение атрибута rel в теге <a>. И отвечает за индексацию каждой конкретной ссылки на странице.
<a href=»url» rel=»nofollow»>ссылка</a>
Атрибут rel показывает отношение данного документа к документу, на который ссылается.
В данном случае, указывая атрибуту rel значение nofollow, мы просим поисковую систему не переходить по внешней ссылке, а также подчеркиваем то, что мы не отвечаем за содержание, на которое ссылаемся.
По ссылкам, оформленным с данным значением, не передается авторитет нашей страницы, другими словами не передается тИЦ и Page Rank. Однако стоит также учитывать и то, что в случае с PR вес все же уходит, но не на сайт, на который мы ссылаемся, а в никуда в прямом смысле этого слова. По поводу тИЦ точной информации о том, уходит вес или остается на сайте — нет.
Остановимся подробнее на распределении и передаче веса в Google.
Итак, абсолютно не важно, сколько ссылок у вас имеют атрибут rel=»nofollow», а сколько без него. Если на странице стоит 10 ссылок, то каждая ссылка получит часть авторитета вашей страницы, и каждая из них передаст этот вес, но если в одном случае вес передастся на конкретный сайт, то в другом случае – вес просто уйдет в никуда
Давайте представим немного, как видит всемирную паутину поисковая система. Все сайты связаны между собой ссылками, абсолютно все. Первый ссылается на второй, второй на третий … тысячный на тысяча первый и миллион какой-то в итоге обязательно будет ссылаться на первый.
Таким образом цепочка замыкается, все сайты находятся в цикле, и вес, который передает первый сайт всегда возвращается к нему через сотни и тысячи других сайтов. Также не забываем, и я уже писала об этом в статье про перелинковку, что этот вес передается не единожды, а постоянно, при этом с течением времени вес становится только больше, все сильнее увеличивая свой авторитет. Именно на этом принципе строится перелинковка сайта.
Теперь представим, что первый сайт закрыл свои ссылки атрибутом rel=»nofollow». Вес не перейдет на второй сайт, а утечет в никуда, и второй сайт не получит ту часть веса, которую должен был, не сможет передать его дальше по цепочке, и в итоге, пройдя весь цикл, Х-какой-то сайт, который должен был передать вес на первый сайт, передаст его в значительно меньшем количестве, чем мог бы. Итак, каждый раз не получая ту часть веса, которую вы самостоятельно пускаете в никуда, закрывая свои ссылки атрибутом rel=»nofollow», сайт не может передать вам ее, из чего следует, что закрывая свои ссылки, вы сами лишаете себя увеличения веса, и такого показателя, как PR.
Чтобы было проще это понять, представим, что каждая ссылка передает вес, равным единице.
Таким образом, если первый сайт не закрыл ссылку атрибутом rel=»nofollow», то в конце цикла получит больший вес от входящих ссылок, чем в случае, если исходящие ссылки будут закрыты.
Но есть ситуации, когда действительно необходимо закрывать ссылки значением nofollow. Обратимся к источникам, Яндекс и Google, что они говорят по этому поводу?
Выдержка из раздела Помощь Яндекса:
Выдержка из раздела Справка Google:
Мы должны закрывать ссылки в тех разделах своего сайта, где любой пользователь может оставить свою ссылку, за которую мы не сможем поручиться, гарантировать, что там качественное содержание.
Также мне хотелось бы уделить внимание ещё одному моменту. Некоторые ярые борцы за закрытые ссылки ставят rel=»nofollow» не только в самих ссылках, т.е
в теге , но и везде, на что только хватает фантазии. И в теге
Давайте не будем выдумывать свои собственные стандарты, а обратимся к существующим, которые разрабатывает международная организация W3C.
Значение rel=»nofollow» можно использовать только в теге , и в других тегах его использовать нельзя!
Итак, мы выяснили, когда стоит пользоваться атрибутом ссылки rel=»nofollow», а когда это не целесообразно. Также мы больше не будем вставлять его никуда, кроме одного единственного тега, обозначающего ссылку
Теперь уделим внимание тегу noindex.
Влияние внутренних ссылок на индексацию сайта
Внутренние ссылки являются основной и практически единственной причиной того, что нам приходится закрывать ненужные и попавшие в индекс страницы разными метатегами и директивами robots.txt. Однако реальность такова, что ненужные роботам страницы очень даже нужны пользователям сайта, а следовательно должны быть и ссылки на эти самые страницы.
А что же делать? При любом варианте запрета индексации ссылок (rel=”nofollow”) и страниц (robots.txt, meta robots), вес сайта просто теряется, утекает на закрытые страницы.
Вариант №1. Большинство распространенных CMS имеют возможность использования специальных тегов (в DLE точно это есть, я сам этим очень активно пользуюсь) при создании шаблонов оформления, которые позволяют регулировать вывод определенной информации. Например, показывать какой-либо текст только гостям или группе пользователей с определенным id и т.д. Если таких тегов вдруг нет, то наверняка на помощь придут логические конструкции (такие конструкции есть в WordPress, а так же форумных движках IPB и vbulletin, опять же, я сам пользуюсь этими возможностями), представляющие из себя простейшие условные алгоритмы на php.
Так вот, логично было бы скрывать неважные и ненужные ссылки от гостей (обычно эту роль играют и роботы при посещении любого сайта), а так же скрывать ссылки на страницы, которые выдают сообщение о том, что вы не зарегистрированы, не имеете прав доступа и все такое. При необходимости можно специально для гостей выводить блок с информацией о том, что после регистрации у них появится больше прав и возможностей, а значит и соответствующие ссылки появятся 😉
Но бывают такие моменты, что ссылку нельзя скрыть или удалить, потому что она нужна, и нужна сразу всем – гостям, пользователям… А вот роботам не нужна. Что делать?
Вариант №2. В редких случаях (хотя последнее время все чаще и чаще) бывает необходимо, чтобы ссылки или даже целые блоки сайта были недоступны и невидны роботам, а вот людям отображались и работали в полной мере, вне зависимости от групп и привилегий. Вы уже, наверное, догадались, что я говорю про сокрытие контента при помощи JavaScript или AJAX. Как это делается технически, я не буду расписывать, это очень долго. Но есть замечательный пост Димы Dimox’а о том, как загрузить часть контента с помощью AJAX на примере WordPress (линк). В примере рассказывается про подгрузку целого сайдбара, но таким же методом можно подгрузить одну только ссылку, например. В общем, немного покопаетесь и разберетесь.
Так вот, если хочется какую-то часть контента роботам не показывать, то лучший выбор – JavaScript. А после того как провернете всю техническую часть, проверить это на работоспособность поможет замечательный плагин для FireFox под названием QuickJava. Просто с помощью плагина отключите для браузера обработку яваскрипта и перезагрузите страницу, весь динамически подгружаемый контент должен пропасть 😉 Но помните, что тут тоже надо знать меру!
И, кстати, еще парочка интересных моментов, которые необходимо знать:
Яндексу в индексации сайтов помогает Яндекс.Метрика, которая автоматически пингует в индекс все посещенные страницы, на которых установлен код Метрики. Но эту функцию можно отключить при получении кода счетчика, установив соответсвующую галочку.
Возможно как то в индексации замешаны Яндекс.Бар и сборка браузера Хром от Яндекса, но в этом я не уверен.
Но вот для Гугла есть информация, что роль поискового робота выполняет сам браузер Google Chrome. Такие уж они хитрецы.
Так что, как видим, скрыть информацию от роботов почти невозможно, если не предпринимать специальные меры.
Как с помощью расширения обнаружить статьи с мета-тегом?
Значок грустного робота на странице канала
При установленном расширении проверка главной страницы канала производится автоматически. Если канал отмечен как неиндексируемый, то в меню расширения пункт «Неиндексируемые» заменяется значением «Канал не индексируется».
Если в меню расширения в редакторе указано «Канал не индексируется», значит в коде страницы канала присутствует <meta property=»robots» content=»none» />
Ещё раз подчеркну, что наличие этого кода, а значит и соответствующего оповещения в меню — норма для новых каналов.
Значок «грустного робота» на странице публикации
При установленном расширении на странице публикации может отображаться значок грустного робота.
Если в публикации есть такой значок, значит в коде страницы есть <meta name=»robots» content=»noindex» />
Соответственно, для того чтобы его увидеть нужно зайти на страницу публикации. Но зато не нужно изучать исходный код страницы.
Поиск публикаций с мета-тегом
Если вы решите проверить не одну, а десяток публикаций, то придётся заходить в каждую и проверять наличие мета-тега в каждой из них. Вручную это неудобно, поэтому в расширении предусмотрена возможность автоматической проверки.
Для того чтобы начать поиск нужно выбрать пункт меню «Неиндексируемые».
Правда, этот пункт меню будет недоступен, если весь канал отмечен, как неиндексируемый — нет смысла запускать проверку, теги будут обнаружены на всех публикациях.
При первом запуске будет отображено большое страшное предупреждение о том, что процедура поиска производится на страх и риск пользователя.
Дело в том, что стандартной процедуры поиска публикаций с мета-тегом в Дзене не предусмотрено, и расширению приходится буквально открывать каждую проверяемую публикацию и заглядывать в код страницы.
Теоретически это может быть воспринято как DDOS-атака или как попытка накрутить просмотры. На практике с этим проблем не было, но предупредить я вас обязан.
Можно проверить все публикации на канале, а можно проверить лишь 20 последних.
Процедура поиска может занять продолжительное время, по завершении вы получите список публикаций, на которых обнаружен мета-тег.
На моём канале только на одной публикации есть этот мета-тег.
На мой странице (не) обнаружен мета-тег, а страница (не) видна в поиске
Действительно, так бывает, что статью из Дзена не удаётся найти в поиске, хотя на ней нет зловредного мета-тега; или наоборот — тег есть, но и на статью есть переходы из поиска.
Всё дело в том, что поисковики работают с определённой задержкой, кроме того у них свои алгоритмы, определяющие, отвечает ли статья на поисковый запрос и насколько она релевантна ему.
Статья, которая отлично чувствуют себя в Дзене, собирает сотни тысяч и миллионы показов, поисковику может показаться неинтересной, и тогда он не будет показывать ссылку на неё на первых страницах поиска.
Кроме того, индексирование может занимать продолжительное время, это значит, что после появления (или удаления мета-тега), должно пройти какое-то время, прежде чем изменение будет учтено поисковыми системами.
Что такое мета тег Robots
Сначала уясним, что есть мета тег Robots, а есть файл Robots.txt, и путать их не будем. Метатег имеет отношение только к одной html странице (на которой он указан), в то время, как файл txt может содержать директивы не только к странице, но к целым каталогам.
Важный момент — для поисковика директивы метатега Роботс имеют преимущество перед директивами из robots.txt. То есть если в .txt у вас указано, что страницу можно индексировать, а в её метатеге указано, что нельзя, поисковик будет слушаться именно директиве из метатега.
При помощи мета тега Robots можно запрещать индексировать содержимое всей страницы. На страницах моего блога он выглядит так:
<meta name="robots" content="noodp"/>
Это означает, что метатег роботс не запрещает индексировать страницу. Noodp тут означает, что он запрещает Google брать в сниппеты описание для страниц из каталога DMOZ — это одна из стандартных настроек плагина Yoast SEO, которым я пользуюсь.
А вот как выглядит метатег Robots, который запрещает индексацию страницы:
<meta name =“robots” content=”noindex,nofollow”/>
Как прописать
Дедовский способ — вручную прописать для страницы. Способ подходит для сайтов на чистом HTML.
Для сайтов на CMS рекомендую использовать SEO-плагины. Я, например, для WordPress использую плагин Yoast SEO, и там под каждой записью в режиме редактирования есть такая опция:
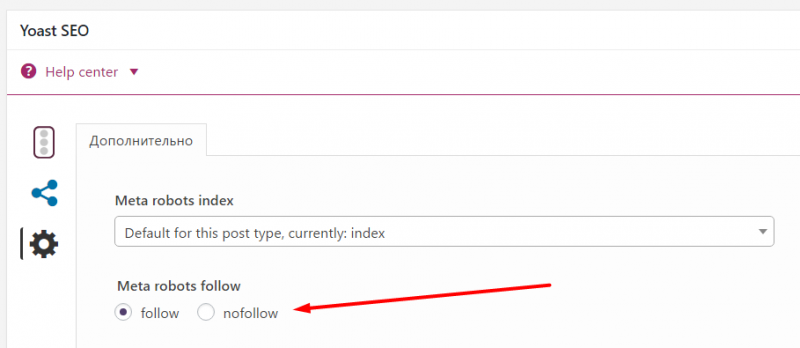
То есть проставить нужное значение можно парой щелчков.
Лучшие примеры использования
- Добавление директивы sitemap в файл robots.txt технически не требуется, но считается хорошей практикой.
- После обновления файла robots.txt рекомендуется проверить, не заблокированы ли важные страницы. Это можно сделать с помощью txt Tester в Google Search Console.
- Используйте инструмент проверки URL-адреса в Google Search Console, чтобы увидеть статус индексации страницы.
- Также можно проверить, проиндексировал ли Google ненужные страницы. Это можно сделать с помощью отчета в Google Search Console. Еще одной альтернативой может быть использование оператора «site». Это команда Google, которая отображает все страницы сайта, доступные в результатах поиска.
Мета тег title
Например, если вы посмотрите HTML-код этой страницы, то увидите, что заголовок выглядит следующим образом:
Теги заголовков помещаются в <head> вашей веб-страницы и предназначены для предоставления чёткого и исчерпывающего представления о том, о чём эта страница. Но имеют ли они такое же сильное влияние на позиции в выдаче, как это было много лет назад?
В последние несколько лет идёт активное обсуждение поведенческих факторов, как логического доказательства релевантности и, следовательно, сигнала ранжирования – даже представители поисковых систем периодически признают их влияние.
Заголовок страницы по-прежнему является первым, что пользователь видит в поисковой выдаче и решает, отвечает ли страница поисковому запросу. Правильно написанный title может значительно увеличить количество кликов по сниппету и трафик на сайт, что, безусловно, влияет на ранжирование.
Простой эксперимент показывает, что Гуглу больше не нужен ваш тайтл, включающий ключ с точным соответствием, чтобы понять тему страницы. Например, несколько лет назад выдача Гугла по запросу «как повысить узнаваемость бренда» очень сильно походила на то, что вы можете наблюдать сейчас в Яндексе:
Всего 1 заголовок из всего топа не включает точное соответствие. А теперь давайте взглянем на Google:
Всего 1 заголовок из всего топа включает точное соответствие. Но при этом в Гугле нет ни одного неуместного результата: каждая, из приведённых здесь страниц, объясняет, как повысить узнаваемость, и заголовки это отражают.
Поисковые системы смотрят на общую картину и обычно оценивают содержание страницы в целом, но «обложка книги» всё ещё имеет значение, особенно, когда речь идёт о взаимодействии с пользователями.
Как правильно заполнять title
- Сделайте для каждой страницы уникальный заголовок, который кратко и точно описывает её контент.
- Если хотите, чтобы заголовки не обрезались в поисковой выдаче, лучше ограничивать их 50-60 символами. В Google длинные заголовки сокращаются, примерно, до 600-700 пикселей, но эти цифры иногда меняются, так что не стоит их жёстко придерживаться.
- Главные ключевые слова должны стоять как можно ближе к началу заголовка. Но вставляйте их максимально органично, как будто вы это делаете для посетителей сайта.
- Используйте название вашего бренда в названии, даже если оно не отображается в поисковой выдаче, это всё равно будет иметь значение для поисковой системы.
Совет: используйте title для привлечения внимания
Тег заголовка ценен не только потому, что он является основным элементом поисковой выдачи, но и потому, что он действует, как заголовок вкладки в вашем веб-браузере. Это можно использовать для привлечения внимания пользователя. Например:
Такой подход используют социальные сети: ВКонтакте, Facebook, LinkedIn, чтобы показать вам, что имеются новые уведомления. Эта тактика может дать весьма неплохой результат!
Выводы
Чтобы максимизировать отдачу от внутренней оптимизации сайта, не пренебрегайте небольшими изменениями, которые складываются в общую картину.
Некоторые мета теги, из описанных выше, являются обязательными, поскольку составляют таксономию ваших страниц. Другие, на первый взгляд, могут показаться второстепенными. Но зачем их игнорировать, когда можно быть на 1 расширенный сниппет впереди конкурента?
Небольшие изменения, которые улучшают взаимодействие с пользователем и помогают поисковым системам лучше понимать ваш сайт, будут оценены обеими сторонами и определённо окупятся в долгосрочной перспективе.
Так что внедряйте!
ПОНРАВИЛСЯ ПОСТ? ПОДЕЛИСЬ ССЫЛКОЙ С ДРУЗЬЯМИ!
СТАТЬИ ИЗ РУБРИКИ:
Тематика: , SEM, Яндекс
(некоторые ответы перед публикацией проверяются модератором)
Итоги — или что сделать, чтобы стало все круто?
Наконец-то я могу подвести итог сегодняшнего огромного поста, и он будет кратким.
Чтобы улучшить качество индексации сайта, необходимо:
- Скрыть от гостей (к ним относятся и роботы) ссылки, которые им не нужны или не предназначены.
- Ссылки, которые нельзя удалить или спрятать от живых посетителей, стоит скрыть и выводить через JavaScript.
- Если ничего из перечисленного невозможно или не получается, то хотя бы необходимо закрыть ссылки на ненужные страницы атрибутом rel=”nofollow”. Хоть польза от этого и сомнительная, но все же…
- Страницы, которые не должны быть проиндексированы и не должны попасть в индекс поисковых систем, стоит запрещать при помощи метатега robots и параметра noindex:
- Страницы, содержащие тег robots не должны быть запрещены к индексации через robots.txt
Что даст нам весь этот «улучшайзинг»:
- Во-первых, чистота индекса сайта, что в наше время очень редко и почти не встречается.
- Во-вторых, быстрота индексации/переиндексации сайта увеличится за счет того, что робот не будет загружать страницы, которые закрыты для него.
- В-третьих, сохранится какая-то часть статического веса сайта, которая раньше утекала по ссылкам на закрытые страницы, а это может положительно отразится на ранжировании сайта.
- В-четвертых, это просто круто и говорит об уровне профессионализма вебмастера.
Фуф, два дня (а точнее — две ночи) писал этот пост и никак не мог дописать, но я это сделал! Потому жду ваших отзывов и комментариев.
Если у кого-то есть практический опыт по теме, обязательно поделитесь им со мной и другими читателями, это будет очень интересно и полезно.
Всем спасибо за внимание и до скорой встречи!