Двуликий request_uri или в поисках корректного http/1.1 сервера
Содержание:
HTTP-заголовки
HTTP-сообщение состоит из начальной строки, за которой следуют набор заголовков, пустая строка и некоторые данные. Начальная строка задает действие, требуемое от сервера, тип возвращаемых данных или код состояния.
HTTP-заголовки можно подразделить на три крупные категории: заголовки, посылаемые в запросе, заголовки, посылаемые в ответе, и те, которые можно включать как в запросы, так и в ответы. Заголовки запросов указывают возможности клиента, например, типы документов, которые может обработать клиент, в то время как заголовки ответов предоставляют информацию о возвращенном документе.
Заголовки запросов
К числу наиболее важных HTTP-заголовков, которые можно включать в запросы, но нельзя включать в ответы, относятся:
- Заголовок Accept
-
Это список MIME-типов, принимаемых клиентом, в формате тип/подтип. Элементы списка должны разделяться запятыми:
Accept: text/html, image/gif, */*
Элемент */* указывает, что все типы будут приняты и обработаны клиентом. Если тип запрошенного файла не может быть обработан клиентом, возвращается ошибка HTTP 406 «Not acceptable» (недопустимо).
- Заголовок From
-
Указывает адрес электронной почты в Интернете учетной записи пользователя, под которой работает клиент, направивший запрос:
From: alexerohinzzz@gmail.com
- Заголовок Referer
-
Позволяет клиенту указать адрес (URI) ресурса, из которого получен запрашиваемый URI. Этот заголовок дает возможность серверу сгенерировать список обратных ссылок на ресурсы для будущего анализа, регистрации, оптимизированного кэширования и т.д. Он также позволяет прослеживать с целью последующего исправления устаревшие или введенные с ошибками ссылки:
Referer: http://www.professorweb.ru
- Заголовок User-Agent
-
Представляет собой строку, идентифицирующую приложение-клиент (обычно браузер) и платформу, на которой оно выполняется. Общий формат имеет вид: программа/версия библиотека/версий, но это не неизменный формат:
User-Agent: Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.17 (KHTML, like Gecko) Chrome/24.0.1312.56 Safari/537.17
Эта информация может использоваться в статистических целях, для отслеживания нарушений протокола и для автоматического распознавания клиента. Она позволяет приспособить ответ так, чтобы не нарушить ограниченные возможности конкретного клиента, например неспособность поддерживать HTML-таблицы.
Заголовки ответов
В ответы могут включаться следующие заголовки:
- Заголовок Content-Type
-
Используется для указания типа данных, отправляемых получателю или, в случае метода HEAD, тип данных, который был бы отправлен в ответ на запрос GET:
Content-Type: text/html
- Заголовок Expires
-
Представляет собой момент времени, после которого информация в документе становится недостоверной. Клиенты, использующие кэширование, в частности прокси-серверы, не должны хранить в кэше эту копию ресурса после заданного времени, если только состояние копии не было обновлено более поздним обращением к исходному серверу:
Expires: Fri, 19 Aug 2012 16:00:00 GMT
- Заголовок Location
-
Определяет точное расположение другого ресурса, к которому может быть перенаправлен клиент. Если это значение представляет собой полный URL, сервер возвращает клиенту «redirect» для непосредственного извлечения указанного объекта:
Location: http://www.samplesite.com
Если ссылка на другой файл относится к серверу, должен указываться частичный URL.
- Заголовок Server
-
Содержит информацию о программном обеспечении, используемом исходным сервером для обработки запроса:
Server: Microsoft-IIS/7.0
Общие заголовки
Несколько заголовков могут включаться как в запрос, так и в ответ, например:
- Заголовок Date
-
Используется для установки даты и времени создания сообщения:
Date: Tue, 16 Aug 2012 18:12:31 GMT
- Заголовок Connection
-
В НТТР/1.0 мы могли использовать в запросе заголовок Connection, указывая, что хотим сохранить соединение после отправки ответа. Теперь такое поведение принято по умолчанию, и в HTTP/1.1 можно использовать заголовок Connection, чтобы указать, что постоянное соединение не нужно:
Connection: close
HTTP POST
Use POST APIs to create new subordinate resources, e.g., a file is subordinate to a directory containing it or a row is subordinate to a database table. When talking strictly in terms of REST, POST methods are used to create a new resource into the collection of resources.
Ideally, if a resource has been created on the origin server, the response SHOULD be HTTP response code and contain an entity which describes the status of the request and refers to the new resource, and a Location header.
Many times, the action performed by the POST method might not result in a resource that can be identified by a URI. In this case, either HTTP response code or is the appropriate response status.
Responses to this method are not cacheable, unless the response includes appropriate or Expires header fields.
Please note that POST is neither safe nor idempotent, and invoking two identical POST requests will result in two different resources containing the same information (except resource ids).
Метод POST
Метод POST используется, когда вы хотите отправить некоторые данные на сервер, например, обновление файла, данные формы и т. Д. В следующем примере используется метод POST для отправки данных формы на сервер, который будет обработан process.cgi и, наконец, ответ будет возвращен:
POST /cgi-bin/process.cgi HTTP/1.1 User-Agent: Mozilla/4.0 (compatible; MSIE5.01; Windows NT) Host: www.it-brain.online Content-Type: text/xml; charset=utf-8 Content-Length: 88 Accept-Language: en-us Accept-Encoding: gzip, deflate Connection: Keep-Alive
<?xml version="1.0" encoding="utf-8"?> <string xmlns="http://clearforest.com/">string</string>
Сценарий на стороне сервера process.cgi обрабатывает переданные данные и отправляет следующий ответ:
HTTP/1.1 200 OK Date: Mon, 27 Jul 2009 12:28:53 GMT Server: Apache /2.2.14 (Win32) Last-Modified: Wed, 22 Jul 2009 19:15:56 GMT ETag: "34aa387-d-1568eb00" Vary: Authorization,Accept Accept-Ranges: bytes Content-Length: 88 Content-Type: text/html Connection: Closed
<html> <body> <h1>Request Processed Successfully</h1> </body> </html>
Request-URI
The Request-URI is a Uniform Resource Identifier and identifies the resource upon which to apply the request. Following are the most commonly used forms to specify an URI:
Request-URI = "*" | absoluteURI | abs_path | authority
| S.N. | Method and Description |
|---|---|
| 1 | The asterisk * is used when an HTTP request does not apply to a particular resource, but to the server itself, and is only allowed when the method used does not necessarily apply to a resource. For example:
OPTIONS * HTTP/1.1 |
| 2 | The absoluteURI is used when an HTTP request is being made to a proxy. The proxy is requested to forward the request or service from a valid cache, and return the response. For example:
GET http://www.w3.org/pub/WWW/TheProject.html HTTP/1.1 |
| 3 | The most common form of Request-URI is that used to identify a resource on an origin server or gateway. For example, a client wishing to retrieve a resource directly from the origin server would create a TCP connection to port 80 of the host «www.w3.org» and send the following lines:
GET /pub/WWW/TheProject.html HTTP/1.1 Host: www.w3.org Note that the absolute path cannot be empty; if none is present in the original URI, it MUST be given as «/» (the server root). |
Этап поиска DNS
Браузер запускает поиск DNS, чтобы получить IP-адрес сервера.
Доменное имя — удобный способ для нас, людей, но Интернет организован таким образом, что компьютеры могут искать точное местоположение сервера по его IP-адресу, который представляет собой набор чисел, например 222.324.3.1 (IPv4).
Во-первых, он проверяет локальный кэш DNS, чтобы узнать, был ли домен разрешен недавно.
В Chrome есть удобный визуализатор DNS-кэша, который вы можете увидеть в
Если там ничего не найдено, браузер использует распознаватель DNS, используя системный вызов gethostbyname POSIX для получения информации о хосте.
gethostbyname
Сначала gethostbyname просматривает локальный файл hosts, который в macOS или Linux находится в /etc/hosts , чтобы проверить, предоставляет ли система информацию локально.
Если это не дает никакой информации о домене, система отправляет запрос на DNS-сервер.
Адрес DNS-сервера сохраняется в системных настройках.
Это 2 популярных DNS-сервера:
- 8.8.8.8: публичный DNS-сервер Google
- 1.1.1.1: DNS-сервер CloudFlare
Большинство людей используют DNS-сервер, предоставленный их интернет-провайдером.
Браузер выполняет DNS-запрос по протоколу UDP.
TCP и UDP являются двумя основополагающими протоколами компьютерных сетей. Они находятся на том же концептуальном уровне, но TCP ориентирован на соединение, а UDP — это протокол без установления соединения, более легкий, используемый для отправки сообщений с небольшими издержками.
DNS-сервер может иметь IP-адрес домена в кэше. Если нет, он спросит корневой DNS-сервер . Это система (состоящая из 13 реальных серверов, распределенных по всей планете), которая управляет всем интернетом.
DNS-сервер не знает адреса каждого доменного имени на планете.
Он знает, где находятся DNS-преобразователи верхнего уровня .
Домен верхнего уровня — это расширение домена: .com , .it , .pizza и так далее.
Как только корневой DNS-сервер получает запрос, он перенаправляет запрос на этот DNS-сервер домена верхнего уровня (TLD).
Скажем, вы ищете ip-calculator.ru. DNS-сервер корневого домена возвращает IP-адрес TLD-сервера .ru.
Теперь наш распознаватель DNS будет кэшировать IP-адрес этого сервера TLD, поэтому ему не нужно будет снова запрашивать его у корневого DNS-сервера.
DNS-сервер TLD будет иметь IP-адреса официальных серверов имен для домена, который мы ищем.
Это DNS-серверы хостинг-провайдера. Их обычно больше 1, чтобы служить резервной копией.
Например:
- ns1.example.com
- ns2.example.com
- ns3.example.com
DNS-распознаватель запускается с первого и пытается запросить IP-адрес домена (также с поддоменом), который вы ищете.
Это основной источник правды для IP-адреса.
Теперь, когда у нас есть IP-адрес, мы можем продолжить наше путешествие.
Как работает HTTP, и зачем нам это знать
Программировать на PHP можно и без знания протокола HTTP, но есть ряд ситуаций, когда для решения задач нужно знать, как именно работает веб-сервер. Ведь PHP — это, в первую очередь, серверный язык программирования.
Протокол HTTP очень прост и состоит, по сути, из двух частей:
- Заголовков запроса/ответа;
- Тела запроса/ответа.
Сначала идёт список заголовков, затем пустая строка, а затем (если есть) тело запроса/ответа.
И клиент, и сервер могут посылать друг другу заголовки и тело ответа, но в случае с клиентом доступные заголовки будут одни, а с сервером — другие. Рассмотрим пошагово, как будет выглядеть работа по протоколу HTTP в случае, когда пользователь хочет загрузить главную страницу социальной сети «Вконтакте».
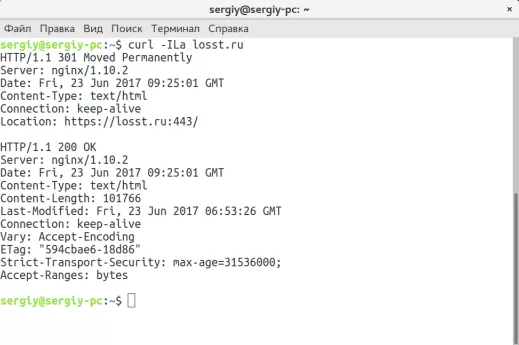
1. Браузер пользователя устанавливает соединение с сервером vk.com и отправляет следующий запрос:
GET / HTTP/1.1 Host: vk.com
2. Сервер принимает запрос и отправляет ответ:
3. Браузер принимает ответ и показывает готовую страницу
Больше всего нам интересен самый первый шаг, где браузер инициирует запрос к серверу vk.com
Рассмотрим подробнее, что там происходит. Первая строка запроса определяет несколько важных параметров, а именно:
- Метод, которым будет запрошен контент;
- Адрес страницы;
- Версию протокола.
— это метод (глагол), который мы применяем для доступа к указанной странице. является самым часто используемым методом, потому что он говорит серверу о том, что клиент всего лишь хочет прочитать указанный документ. Но помимо есть и другие методы, один из них мы рассмотрим уже в следующем разделе.
После метода идет указание на адрес страницы — URI (универсальный идентификатор ресурса). В нашем случае мы запрашиваем главную страницу сайта, поэтому используется просто слэш — .
Последним в этой строке идет версия протокола и почти всегда это будет
После строки с указанием основных параметров всегда следует перечисление заголовков, которые передают серверу дополнительную полезную информацию: название и версию браузера, язык, кодировку, параметры кэширования и так далее.
Среди всех этих заголовков, которые передаются при каждом запросе, есть один обязательный и самый важный — это заголовок . Он определяет адрес домена, который запрашивает браузер клиента.
Сервер, получив запрос, ищет у себя сайт с доменом из заголовка , а также указанную страницу.
Если запрошенный сайт и страница найдены, клиенту отправляется ответ:
Такой ответ означает, что всё хорошо, документ найден и будет отправлен клиенту. Если говорить более обобщённо, стартовая строка ответа имеет следующую структуру:
Больше всего здесь интересен именно код состояния, он же код ответа сервера.
В этом примере код ответа — 200, что означает: сервер работает, документ найден и будет передан клиенту. Но не всегда всё идет гладко.
Например, запрошенный документ может отсутствовать или сервер будет перегружен, в таком случае клиент не получит контент, а код ответа будет отличным от 200.
- 404 — если сервер доступен, но запрошённый документ не найден;
- 503 — если сервер не может обрабатывать запросы по техническим причинам.
Спецификация HTTP 1.1 определяет 40 различных кодов HTTP.
После стартовой строки следуют заголовки, а затем тело ответа.
HTML Tags
<!—><!DOCTYPE><a><abbr><acronym><address><applet><area><article><aside><audio><b><base><basefont><bdi><bdo><big><blockquote><body><br><button><canvas><caption><center><cite><code><col><colgroup><data><datalist><dd><del><details><dfn><dialog><dir><div><dl><dt><em><embed><fieldset><figcaption><figure><font><footer><form><frame><frameset><h1> — <h6><head><header><hr><html><i><iframe><img><input><ins><kbd><label><legend><li><link><main><map><mark><meta><meter><nav><noframes><noscript><object><ol><optgroup><option><output><p><param><picture><pre><progress><q><rp><rt><ruby><s><samp><script><section><select><small><source><span><strike><strong><style><sub><summary><sup><svg><table><tbody><td><template><textarea><tfoot><th><thead><time><title><tr><track><tt><u><ul><var><video>
2 Метод GET
Напишем наш запрос.
GET http://www.site.ru/news.html HTTP/1.0\r\n Host: www.site.ru\r\n Referer: http://www.site.ru/index.html\r\n Cookie: income=1\r\n \r\n
Данный запрос говорит нам о том, что мы хотим получить содержимое страницы по адресу http://www.site.ru/news.html, использую метод GET. Поле Host говорит о том, что данная страница находится на сервере www.site.ru, поле Referer говорит о том, что за новостями мы пришли с главной страницы сайта, а поле Cookie говорит о том, что нам была присвоена такая-то кука. Почему так важны поля Host, Referer и Сookie? Потому что нормальные программисты при создании динамических сайтов проверяют данные поля, которые появляются в скриптах (РНР в том числе) в виде переменных. Для чего это надо? Для того, например, чтобы сайт не грабили, т.е. не натравливали на него программу для автоматического скачивания, или для того, чтобы зашедший на сайт человек всегда попадал бы на него только с главной страницы и.т.д.
Теперь давайте представим, что нам надо заполнить поля формы на странице и отправить запрос из формы, пусть в данной форме будет два поля: login и password (логин и пароль),- и, мы естественно знаем логин и пароль.
GET http://www.site.ru/news.html?login=Petya%20Vasechkin&password=qq HTTP/1.0\r\n Host: www.site.ru\r\n Referer: http://www.site.ru/index.html\r\n Cookie: income=1\r\n \r\n
Логин у нас «Petya Vasechkin» Почему же мы должны писать Petya%20Vasechkin? Это из=за того, что специальные символы могут быть распознаны сервером, как признаки наличия нового параметра или конца запроса и.т.д. Поэтому существует алгоритм кодирования имен параметров и их значений, во избежание оштбочных ситуаций в запросе. Полное описание данного алгоритма можно найти здесь, а в PHP есть функции rawurlencode и rawurldecode для кодирования и декодирования соответственно. Хочу отметеить, что декодирование РНР делает сам, если в запросе были переданы закодированные параметры. На этом я закону первую главу знакомства c протоколом HTTP. В следуючей главе мы рассмотрим построение запросов типа POST (в переводе с английского — «отправить»), что будет гораздо интереснее, т.к. именно данный тип запросов используется при отправке данных из HTML форм.
Endpoint
Адрес, на который посылаются сообщения называется Endpoint.
Обычно это URL (например, название сайта) и порт. Если я хочу создать веб сервис
на порту 8080 Endpoint будет выглядеть так:
Если моему Web сервису нужно будет отвечать на различные сообщения я
создам сразу несколько URL (interfaces) по которым к сервису можно будет обратиться.
Например
Как видите у моих эндпойнтов (Enpoints) различные окончания. Такое окончание в Endpoint
называются Resource, а начало
Base URL.
Такое определение Endpoint и Resource используется, например, в
SOAP UI
для RESTful интерфейсов
https://andreyolegovich.ru:8080 — это Base URL
/resource1/status — это Resource
Endpoint = Base URL + Resource
Понятие Endpoint может использоваться в более широком смысле. Можно сказать, что
какой-то определённый роутер или компьютер является Endpoint. Например, в понятии
Endpoint Management под Endpoint
имеют в виду конечное устройство
Обычно это
понятно из контекста.
Также следует обратить внимание на то, что понятие Endpoint выходит за рамки
RESTful и может использовать как в SOAP так и в других протоколах.
Термин Resource также связан с RESTful, но в более широком смысле может
означать что-то другое.
HTML Теги
<!—…—><!DOCTYPE><a><abbr><acronym><address><applet><area><article><aside><audio><b><base><basefont><bdi><bdo><big><blockquote><body><br><button><canvas><caption><center><cite><code><col><colgroup><data><datalist><dd><del><details><dfn><dialog><dir><div><dl><dt><em><embed><fieldset><figcaption><figure><font><footer><form><frame><frameset><h1> — <h6><head><header><hr><html><i><iframe><img><input><ins><kbd><label><legend><li><link><main><map><mark><meta><meter><nav><noframes><noscript><object><ol><optgroup><option><output><p><param><picture><pre><progress><q><rp><rt><ruby><s><samp><script><section><select><small><source><span><strike><strong><style><sub><summary><sup><svg><table><tbody><td><template><textarea><tfoot><th><thead><time><title><tr><track><tt><u><ul><var><video>
Glossary
Safe Methods
As per HTTP specification, the GET and HEAD methods should be used only for retrieval of resource representations – and they do not update/delete the resource on the server. Both methods are said to be considered “safe“.
This allows user agents to represent other methods, such as POST, PUT and DELETE, in a unique way so that the user is made aware of the fact that a possibly unsafe action is being requested – and they can update/delete the resource on server and so should be used carefully.
Idempotent Methods
The term idempotent is used more comprehensively to describe an operation that will produce the same results if executed once or multiple times. Idempotence is a handy property in many situations, as it means that an operation can be repeated or retried as often as necessary without causing unintended effects. With non-idempotent operations, the algorithm may have to keep track of whether the operation was already performed or not.
In HTTP specification, The methods GET, HEAD, PUT and DELETE are declared idempotent methods. Other methods OPTIONS and TRACE SHOULD NOT have side effects, so both are also inherently idempotent.
References:
https://www.w3.org/Protocols/rfc2616/rfc2616.txthttp://tools.ietf.org/html/rfc6902
HTTP-запросы
Каждый клиент посылает запрос, и сервер на него отвечает. Все запросы и ответы состоят из трех частей, а именно: строки запроса или ответа, секции заголовков и тела сущности (любого содержания, отправляемого вместе с сообщением, например, страницы HTML для отображения в браузере или данных формы, пересылаемых на сервер).
Клиент связывается с сервером в назначенном номере порта (по умолчанию равном 80) и запрашивает у сервера документ, задавая HTTP-команду, называемую методом, за которой следует адрес документа и номер версии HTTP. Клиент также отправляет серверу необязательную информацию в заголовках, чтобы сообщить серверу о своей конфигурации и приемлемых для него форматах документов. Информация заголовка дается в одной строке вместе с именем и значением заголовка. После заголовков клиент посылает пустую строку. Затем клиент отправляет дополнительные данные. Это могут быть данные формы, отправляемые на сервер методом POST, или файл, копируемый на сервер методом PUT.
Запросы клиентов подразделяются на три секции. Первая строка сообщения всегда должна содержать HTTP-команду, называемую методом, за которой следует URI, идентифицирующий файл или ресурс, запрашиваемый клиентом, и номер версии HTTP:
GET /default.aspx HTTP/1.1
Теперь исследуем каждую из этих секций. Метод — это HTTP-команда, начинающая первую строку запроса клиента. Метод информирует сервер о цели запроса клиента. Для HTTP определены семь методов: GET, HEAD, POST, OPTIONS, PUT, DELETE и TRACE, но HTTP-серверы могут также реализовать методы расширения, не определенные протоколом HTTP. Заметим, что названия методов зависят от регистра клавиатуры, поэтому, например, слово get не будет распознано как допустимый метод.
Метод GET используется для запроса информации, расположение которой на сервере определяется заданным URI. Этот метод широко применяется браузерами, чтобы извлекать документы для просмотра. Результат запроса GET генерируется разными способами. Это может быть файл, доступный с сервера, вывод программы, вывод, полученный на устройстве, и т. д.
Когда клиент в своем запросе использует метод GET, сервер отправляет ответ, содержащий строку состояния, заголовки и метаданные. Если сервер не может обработать запрос из-за ошибки или отсутствия авторизации, он отправляет объяснение в текстовом виде, помещая его в ответе в секцию данных.
Секция тела о сути запроса GET всегда остается пустой. Запрошенный клиентом ресурс (файл или программа) идентифицируется по его полному пути на сервере. Любая дополнительная информация, например, значения из формы, которую клиенту нужно отправить серверу, присоединяется вслед за URI как строка запроса:
GET /default.aspx?name=Alex HTTP/1.1
Метод HEAD функционально аналогичен методу GET, не считая того, что сервер ничего не помещает в секцию данных ответа. Методом HEAD запрашивается только заголовочная информация по файлу или ресурсу. Для запроса HEAD HTTP-сервер должен отправить в заголовках ту же информацию, которую он бы отправил в ответ на запрос GET. Данный метод используется, если клиенту нужна информация о документе, но не нужно получать сам документ.
Метод POST позволяет отправить данные серверу в клиентском запросе. Эти данные посылаются программе обработки данных, к которой у сервера есть доступ. Метод POST может использоваться для многих приложений, например, для обеспечения входных данных сетевых служб, программ интерфейса командной строки и т.д. Данные отправляются на сервер в секции тела сути клиентского запроса. Обработав запрос POST и заголовки, сервер передает это тело программе, указанной в URI.
В методе OPTIONS запрашивается информация о поддержке HTTP на Web-cepвeре. Метод OPTIONS может применяться с URL, чтобы извлечь информацию о конкретном документе или, с групповым символом *, чтобы получить информацию о возможностях сервера в целом. Информация возвращается в заголовках ответа.
Compare GET vs. POST
The following table compares the two HTTP methods: GET and POST.
| GET | POST | |
|---|---|---|
| BACK button/Reload | Harmless | Data will be re-submitted (the browser should alert the user that the data are about to be re-submitted) |
| Bookmarked | Can be bookmarked | Cannot be bookmarked |
| Cached | Can be cached | Not cached |
| Encoding type | application/x-www-form-urlencoded | application/x-www-form-urlencoded or multipart/form-data. Use multipart encoding for binary data |
| History | Parameters remain in browser history | Parameters are not saved in browser history |
| Restrictions on data length | Yes, when sending data, the GET method adds the data to the URL; and the length of a URL is limited (maximum URL length is 2048 characters) | No restrictions |
| Restrictions on data type | Only ASCII characters allowed | No restrictions. Binary data is also allowed |
| Security | GET is less secure compared to POST because data sent is part of the URL Never use GET when sending passwords or other sensitive information! |
POST is a little safer than GET because the parameters are not stored in browser history or in web server logs |
| Visibility | Data is visible to everyone in the URL | Data is not displayed in the URL |
❮ Previous
Next ❯
DELETE Method
The DELETE method is used to request the server to delete a file at a location specified by the given URL. The following example requests the server to delete the given file hello.htm at the root of the server:
DELETE /hello.htm HTTP/1.1 User-Agent: Mozilla/4.0 (compatible; MSIE5.01; Windows NT) Host: www.tutorialspoint.com Accept-Language: en-us Connection: Keep-Alive
The server will delete the mentioned file hello.htm and will send the following response back to the client:
HTTP/1.1 200 OK Date: Mon, 27 Jul 2009 12:28:53 GMT Server: Apache/2.2.14 (Win32) Content-type: text/html Content-length: 30 Connection: Closed
<html> <body> <h1>URL deleted.</h1> </body> </html>
Как нарисовать граф на 1С Промо
Описывается реализация на языке запросов 1С метода расположения вершин графа на плоскости, основанного на использовании электромеханической аналогии. При этом вершины графа представляются одноименными электрическими зарядами, дуги — пружинками. Силы взаимодействия вершин в этой системе переводят их из случайного начального в нужное конечное положение. Приведена обработка рисования графов «ГрафОграф», реализующая данный подход, показывающая также динамику процесса. Граф можно задать списком ребер вручную, выбрать из нескольких предопределенных примеров или сформировать по данным информационной базы.
1 стартмани
Контроль безопасности
Кросс-доменные запросы проходят специальный контроль безопасности, цель которого – не дать злым хакерам завоевать интернет.
Серьёзно. Разработчики стандарта предусмотрели все заслоны, чтобы «злой хакер» не смог, воспользовавшись новым стандартом, сделать что-то принципиально отличное от того, что и так мог раньше и, таким образом, «сломать» какой-нибудь сервер, работающий по-старому стандарту и не ожидающий ничего принципиально нового.
Давайте, на минуточку, вообразим, что появился стандарт, который даёт, без ограничений, возможность делать любой странице HTTP-запросы куда угодно, какие угодно.
Как сможет этим воспользоваться злой хакер?
Он сделает свой сайт, например и заманит туда посетителя (а может посетитель попадёт на «злонамеренную» страницу и по ошибке – не так важно). Когда посетитель зайдёт на , он автоматически запустит JS-скрипт на странице
Этот скрипт сделает HTTP-запрос на почтовый сервер, к примеру,. А ведь обычно HTTP-запросы идут с куками посетителя и другими авторизующими заголовками
Когда посетитель зайдёт на , он автоматически запустит JS-скрипт на странице. Этот скрипт сделает HTTP-запрос на почтовый сервер, к примеру, . А ведь обычно HTTP-запросы идут с куками посетителя и другими авторизующими заголовками.
Поэтому хакер сможет написать на код, который, сделав GET-запрос на , получит информацию из почтового ящика посетителя. Проанализирует её, сделает ещё пачку POST-запросов для отправки писем от имени посетителя. Затем настанет очередь онлайн-банка и так далее.
Спецификация CORS налагает специальные ограничения на запросы, которые призваны не допустить подобного апокалипсиса.
Запросы в ней делятся на два вида.
считаются запросы, если они удовлетворяют следующим двум условиям:
- : GET, POST или HEAD
- – только из списка:
- со значением , или .
«Непростыми» считаются все остальные, например, запрос с методом или с заголовком не подходит под ограничения выше.
Принципиальная разница между ними заключается в том, что «простой» запрос можно сформировать и отправить на сервер и без XMLHttpRequest, например при помощи HTML-формы.
То есть, злой хакер на странице и до появления CORS мог отправить произвольный GET-запрос куда угодно. Например, если создать и добавить в документ элемент , то браузер сделает GET-запрос на этот URL.
Аналогично, злой хакер и ранее мог на своей странице объявить и, при помощи JavaScript, отправить HTML-форму с методом GET/POST и кодировкой . А значит, даже старый сервер наверняка предусматривает возможность таких атак и умеет от них защищаться.
А вот запросы с нестандартными заголовками или с методом таким образом не создать. Поэтому старый сервер может быть к ним не готов. Или, к примеру, он может полагать, что такие запросы веб-страница в принципе не умеет присылать, значит они пришли из привилегированного приложения, и дать им слишком много прав.
Поэтому при посылке «непростых» запросов нужно специальным образом спросить у сервера, согласен ли он в принципе на подобные кросс-доменные запросы или нет? И, если сервер не ответит, что согласен – значит, нет.
В спецификации CORS, как мы увидим далее, есть много деталей, но все они объединены единым принципом: новые возможности доступны только с явного согласия сервера (по умолчанию – нет).
HTTP-сервис «Товары»
HTTP-сервис «Товары» написан в REST-стиле. Он позволяет получать и удалять элементы и группы в справочнике товаров. Доступ к элементу осуществляется с помощью его пути в иерархии.
Например, для того чтобы получить информацию о товаре «Ряженка» с кодом 000000027, входящем в группу «Молочные» с кодом 000000099, которая входит, в свою очередь в группу «Продукты» с кодом 000000011, в браузере надо будет набрать http://<ПутьПубликацииИБ>/hs/Products/000000011/000000099/000000027. Если база опубликована по пути http://localhost:8090/Platform8Demo/, то путь будет:
http://localhost:8090/Platform8Demo/hs/Products/000000011/000000099/000000027.
Из чего состоит путь? Рассмотрим по частям:
- http://localhost:8090/Platform8Demo/ — путь публикации информационной базы
- hs – обязательный сегмент пути, сообщающий серверу, что будет происходить работа с http-сервисами
- Products – строка, идентифицирующая конкретный веб-сервис. Задается свойством «Корневой URL http-сервиса» объекта метаданных веб-сервиса
- 000000011/000000099/000000027 – путь внутри сервиса. Все допустимые пути для данного сервиса определяются совокупностью дочерних объектов метаданных «Шаблон URL».
В нашем случае у сервиса один дочерний объект шаблон URL. В свойстве «Шаблон» этого объекта записана строка “/*». Звездочка – это специальное значение, указывающее на то, что к данному шаблону подходят любые URL. В нашем случае необходимость использования такого шаблона (т.е. по сути отказа от ограничения URL) обусловлена произвольной глубиной иерархии товаров.
У нашего шаблона URL имеются два дочерних объекта, соответствующих HTTP-методам GET (получение) и DELETE (удаление). Именно в них указаны обработчики, которые будут вызываться при обращении к HTTP-сервису.
Для обработки запроса с использованием HTTP-метода GET (а именно такой будет создан, если вставить указанные выше URL в браузер) используется функция ПутьКТоваруGET. Рассмотрим эту функцию немного подробнее:
- Функция принимает единственный параметр «Запрос», это объект типа HTTPСервисЗапрос, содержащий всю нужную нам информацию о выполняемом вызове.
- Функция определяет путь к запрашиваемому ресурсу при помощи конструкции Запрос.ПараметрыURL . По сути, она спрашивает: «Что в реальном URL присутствует на том месте, где в шаблоне была звездочка»?
- Дальнейший код функции ищет элемент справочника по цепочке «00000011/000000099/000000027», используя объекты «1С:Предприятия».
- Если в какой-то момент следующее звено цепочки не находится, то формируется ответ сервиса с кодом 404, знакомым каждому пользователю веб-браузера.
Ответ = Новый HTTPСервисОтвет(404);
Если цепочка пройдена успешно и конечный элемент найден, то для него формируется XML-представление при помощи встроенной XML-сериализации. Если элемент является группой, то в ответ включается XML-представление всех непосредственных потомков.
Ответ = Новый HTTPСервисОтвет(200);
Ответ.УстановитьТелоИзСтроки(СтрокаXML);
// Помогает клиенту понять, что за данные к нему пришли
// Браузеры, например, применят удобную подсветку XML-синтаксиса
Ответ.Заголовки.Вставить("Content-type", "application/xml");
Обработка HTTP-метода DELETE происходит в функции ПутьКТоваруDELETE имало чем отличается от обработки запроса с использованием HTTP-метода GET
Стоит обратить внимание на то, что в случае DELETE используется код ответа 204, а не 200. Код ответа 204 также свидетельствует об успешном выполнении операции на сервере, но сообщает клиенту, что сервер не посылал в ответ никаких данных в теле запроса
GET Method
A GET request retrieves data from a web server by specifying parameters in the URL portion of the request. This is the main method used for document retrieval. The following example makes use of GET method to fetch hello.htm:
GET /hello.htm HTTP/1.1 User-Agent: Mozilla/4.0 (compatible; MSIE5.01; Windows NT) Host: www.tutorialspoint.com Accept-Language: en-us Accept-Encoding: gzip, deflate Connection: Keep-Alive
The server response against the above HEAD request will be as follows:
HTTP/1.1 200 OK Date: Mon, 27 Jul 2009 12:28:53 GMT Server: Apache/2.2.14 (Win32) Last-Modified: Wed, 22 Jul 2009 19:15:56 GMT ETag: "34aa387-d-1568eb00" Vary: Authorization,Accept Accept-Ranges: bytes Content-Length: 88 Content-Type: text/html Connection: Closed
<html> <body> <h1>Hello, World!</h1> </body> </html>