Yandex wordstat assistant
Содержание:
- Ответы на вопросы, хитрости при работе с «Вордстатом»
- Используем поисковые операторы
- Кейс №4
- Как пользоваться?
- Программы парсеры
- Дополнительные возможности
- Инструменты для упрощения работы с «Вордстатом» – расширения и программы
- Что такое яндекс вордстат хелпер?
- Yandex Wordstat Assistant
- Анализ ключевых слов конкурентов
- Минус-режим
Ответы на вопросы, хитрости при работе с «Вордстатом»
За годы работы с «Вордстатом» у меня накопилась небольшая методичка по ответам на часто задаваемые неочевидные вопросы. Думаю, вы найдете что-то полезное.
Собрали кучу данных
Как проводить анализ запросов? На что обращать внимание?. В первую очередь обращаем внимание на коммерческие запросы, у которых частота без кавычек и в кавычках отличается плюс-минус в 2 раза или менее
Если при еще и слабая выдача (нет нормальных предложений), вообще отлично
В первую очередь обращаем внимание на коммерческие запросы, у которых частота без кавычек и в кавычках отличается плюс-минус в 2 раза или менее. Если при еще и слабая выдача (нет нормальных предложений), вообще отлично
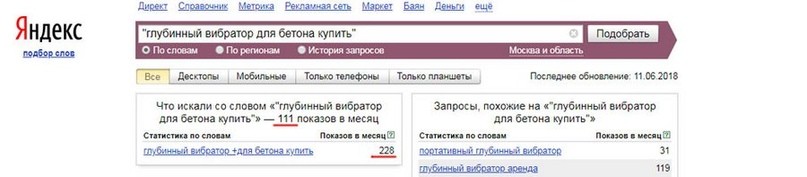
Чем больше расхождение в цифрах, тем больше у вас шанс не угадать намерение пользователя. Например, запрос «боковое стекло хендай» плохой, потому вообще непонятно, что ищут. Дефлектор бокового стекла? Само стекло? Левое? Правое? Переднее? Купить или продать?
Пример хорошего запроса:
2. Как посмотреть статистику запросов для одного города?
Выберите свой город в настройках региона. Помимо города хорошо бы понимать целевую аудиторию и дополнительно затачивать сайт под целевую аудиторию. Например, эвакуатор или вскрытие дверей почти наверняка будут искать со смартфона или планшета.
3. Как обойти ограничение на длину запроса в 8 слов?
Через «Вордстат» такие данные собрать нельзя. Запросы из 8 и более слов можно собрать в поисковых подсказках, найти в различных базах запросов или получить в статистике своего сайта.
4. Что означают абсолютные и относительные данные в истории запросов?
Абсолютный показатель – это фактическое цифровое значение, сколько было таких запросов за период. Относительное значение показывает популярность запроса среди всех запросов в поиске.

5. Что делать, если «Вордстат» собрал 2000 запросов, но нужно больше?
В широких нишах на 40-й странице «Вордстата» только начинается самое интересное:

Если в «Вордстат» ввести запрос в кавычках, повторяя основное слово, вы увидите все запросы из Х слов, содержащих нужное слово. Х – количество слов во фразе в кавычках. Пример:

Используя поочередно конструкции:
- «налог налог налог налог налог налог налог»
- «налог налог налог налог налог налог»
- «налог налог налог налог налог»
- «налог налог налог налог»
- «налог налог налог»
- «налог налог»
- налог
Можно собрать все запросы, которые содержат слово «налог» или его склонения.
6. Как провести массовую проверку частотности запросов из «Вордстат»?
Массово проверить все частотности фраз можно сделать в «Кей Коллекторе» или его бесплатном аналоге – программе «Словоеб».
7. Как убрать капчу в «Вордстате»?
Причина появления капчи – большое количество запросов с 1 IP адреса. Вы можете или сменить айпишник, или использовать программы для работы с «Вордстатом» вместе с сервисами разгадывания капчи.
8. Почему у «Вордстата» ограничение длины в 7 слов?
«Вордстат» изначально был создан как сервис статистики для «Яндекс Директа», в котором максимальное количество слов в рекламной фразе – 7. Никаких других причин для ограничения запроса нет.
Источник статьи
Используем поисковые операторы
С их помощью можно значительно сократить список запросов.
Плюс
Ввод «+» позволяет сделать стоящее за ним слово или словосочетание обязательным. Сервис не учитывает предлоги и союзы, такие как: из, от, на, для, и, в. Наглядный пример, в котором количество запросов уменьшилось в более, чем 13 раз.
Восклицательный знак
С помощью «!» фиксируется окончание слова, перед которым он поставлен. Этот оператор часто используется для оптовых продаж. Например, вы вводите «купить кухонные столы» и получаете более 60 тысяч показов
Но, обратите внимание, слово «столы» в статистике отображается и в единственном числе – «стол». Ставим оператор «!» и получаем чуть больше 6 тысяч показов
[] фиксируют расстановку слов в искомом запросе. Часто используется в логистике. Пример:
Кавычки
Поставив запрос в “”, вы получите данные по показам без добавления лишних слов. То есть, если вы вводите «ремонт мебели москва», то получаете статистику по запросам из трёх слов
Важно: чем ближе числовой показатель запроса с кавычками и без, тем лучше работает данный запрос. На этом примере видно, что запрос малоэффективен
Или
Обозначается при помощи вертикальной черты «|» и используется при сравнении или перемещении отдельных слов/словосочетаний.
Символы () дают возможность сгруппировать запросы или несколько операторов вместе.
Минус
Знак «-» необходим для того, чтобы убрать из статистики ненужные для вас слова (минус слова). С его помощью удаётся дать реальную оценку спроса на товар. Если вы занимаетесь производством и установкой каменных столешниц и только из натурального камня, то вам нужно исключить запросы типа «искусственный», «своими руками», «в домашних условиях», «агломерат» и так далее. В результате список запросов сократился почти на тысячу.
Кейс №4
Допустим, перед нами стоит задача быстро собрать теги для категории «Смартфоны» и у нас нет времени чистить огромное облако запросов данной категории от мусора. Чаще всего тегами являются 2 типа интентов – характеристика объекта (белый смартфон, мощный смартфон) и по назначению объекта (смартфон для пожилых, смартфон для девушки). С помощью Вордстата мы можем легко собрать теги 2-го типа – по назначению, так как все такие запросы содержат предлоги. Исходя из этого мы делаем следующую регулярку:
смартфоны (+до|+с|+на) -скачать -игры -интернет -мтс -фото
Так же указываем базовые стоп слова, чтобы не собирать мусор.
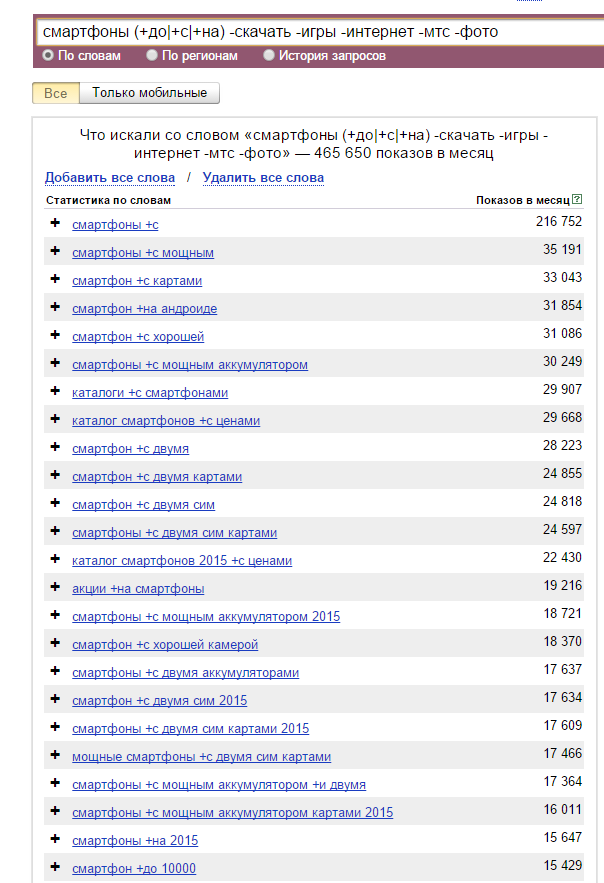
Сразу видны будущие теги – смартфоны на андроиде, с мощным аккумулятором, с хорошей камерой и т.д. Естественно у каждого могут быть индивидуальные проблемы и текущие кейсы не подойдут для решения вашей задачи, но включив логику, вы всегда можете видоизменить наши примеры под ваши нужды.
Все приведенные выше примеры работают в нашем парсере Wordstat – можете сами в этом убедиться. 🙂

Как пользоваться?
Перед тем, как пользоваться программкой, обозначим ее основной функционал:
- копирование данных с одного клика;
- подсчет количества слов;
- автосортировка в алфавитном порядке;
- удаление и добавление произвольных или выбранных слов;
- проверка на предмет дублей и их удаление;
- оповещение о всех происходящих действиях.
Для подбора ключевиков с помощью виджета нужно ввести в поисковую строку «Вордстата» нужное слово или запрос. С левой стороны от каждого появившегося пункта стоит знак «+». Нажав на него, можно добавлять в расширение интересующие ключевики. Либо можно выбрать вариант «Добавить все», и тогда все пункты автоматически перейдут в плагин.
Иконка виджета снабжена тремя кнопками:
- добавить ключевое слово;
- копировать в буфер обмена;
- очистить список.
Для добавления списка в Excel, «Блокнот» нужно выбрать опцию копирования в буфер обмена, перейти в место копирования и с помощью комбинации Ctrl + V вставить выбранные данные. Альтернатива буквенной комбинации на клавиатуре – последовательность «правка-вставить» в меню, либо клик правой кнопкой мыши с выбором действия «вставить».
Стоит добавить, что для эффективного и быстрого сбора семантического ядра, автоматизации работы с Yandex Wordstat, экономии личного времени существуют также другие расширения и плагины. Однако Yandex Wordstat Helper является одним из самых популярных и востребованных виджетов среди сео-специалистов.
Программы парсеры
Для точной обработки ключевых слов рекомендуется использовать программные комплексы. Преимущество – они работают напрямую с базами данных Ворстат. Полная версия платная, некоторые разработчики предоставляют демо-режим с ограниченным функционалом.
Кей Коллектор
Программа «Кей Коллектор» популярна среди разработчиков и СЕО-оптимизаторов. Причины – работа с популярными поисковыми системами, сегментация выборок по параметрам пользователя. Предоставляется только на платной основе, стоимость зависит от количества приобретаемых лицензий.
Особенности «Кей Коллектор»:
- Анализируется только актуальная статистика, сбор информации ведется напрямую из баз данных (БД) Яндекса.
- Ключевые слова подбираются по региону, частоте, сезонности.
- Учитываются стоп-слова.
Возможен многопоточный режим работы. Но есть вероятность получения бана или многократного ввода капчи при формировании нескольких потоков запроса информации с одного IP. Возможен сбор информации через Яндекс.Директ, что уменьшает скорость обработки.
Словоёб
Бесплатная альтернатива Кей Коллектор, но с меньшими функциональными возможностями. Отличие – «Словоёб» работает только с Вордстат. При анализе некоторых ключевых фраз могут не учитываться низкочастотные запросы, которые есть в статистике Яндекс.Директ. Глубина эффективного парсинга ограничена 40 страницами.
Особенности программы «Словоёб»:
- меньшие возможности работы с таблицами;
- нет «поисковых подсказок»;
- отсутствует сбор главных страниц выдачи;
- нет позиций по запросам.
Программа подходит для формирования СЯ небольшого проекта. Причина – скорость обработки полученных данных, нет углубленного анализа запросов.
Магадан
Технические ограничения в бесплатном варианте программы:
- нельзя выбрать региональность для запросов;
- отключены фильтры по количеству символов, слов;
- нет импорта файлов со стоп-словами;
- нельзя задавать правила к генерируемым ключевым фразам;
- отключен экспорт КС.
Несмотря на такие ограничения «Магадан» можно использовать для формирования СЯ 1-3 проектов. Но по отзывам пользователей по сравнению с ручной обработкой Вордстата теряются низкочастотные запросы.
Дополнительные возможности
На иллюстрации выше, цифрами отмечены: 1 — сам запрос, 2 — дата обновления статистики Яндекса по данным фразам, 3 — суммарное число показов по фразам которые соответствуют запросу, 4 — общее число показов по фразе.
Здесь очень важно не путать общее число показов из колонки 4 и число точных запросов по фразе, которое можно получить с использованием операторов «Кавычки», «Восклицательный знак» и «Квадратные скобки». К дополнительным возможностям WordStat отнесем изучение истории (сезонности) спроса в тематике, получение частоты в заданном регионе и анализ популярности фраз в мобильном поиске (планшеты, мобильные телефоны)
К дополнительным возможностям WordStat отнесем изучение истории (сезонности) спроса в тематике, получение частоты в заданном регионе и анализ популярности фраз в мобильном поиске (планшеты, мобильные телефоны).
Данные функции часто оказываются полезны при планировании рекламных кампаний.
История запроса
Можно быстро понять, как меняется интерес к выходу новой модели «IPhone 6S». К сожалению, в текущий момент история запросов не поддерживает операторы («ИЛИ», «Группировка», «Квадратные скобки»).
Изучение динамики по запросу . Хорошо видны резкие сезонные всплески и провалы после наступления января.
Частота в заданном регионе
Отдельного упоминания заслуживает получение частоты запроса в заданном регионе. С помощью разделения общей частоты запроса по регионам можно оценить как частоту заданного запроса в интересующей нас регионе (Москва, Москва и область, Санкт-Петербург и т.д.), так и относительную популярность того или иного запроса в регионе.
Из примера приведенного ниже видно, что запросы со словами «купить» и «Казань» преимущественно задают жители г. Казань, что весьма очевидно. Использование данной функции на практике иногда открывает и более неожиданные закономерности.
Сбор (парсинг) запросов заданной длинны
На практике бывает полезным использовать приём парсинга запросов заданной длинны (из 2, 3, 4 слов и так далее) с вхождением ключевого слова. Данная возможность оказывается особенно актуальной, если вы работаете в популярной тематике и сбор первых 41 страниц не позволяет получить все поисковые фразы.
Для сбора всех фраз с длиной в 3 слова используется конструкция вида:
«IPhone IPhone IPhone»
Данный запрос позволяет собрать уже не просто 41 страницу поисковых фраз произвольной длины, а 41 страницу фраз из трёх слов с вхождением «IPhone». Последовательный анализ запросов с длиной от 2 до 7 слов позволяет существенно увеличить охват целевой аудитории.
Для ускорения сбора частот, быстрого парсинга Яндекс.Вордстат и хранения целевых ядер, рекомендуется использовать программы и онлайн-сервисы автоматизации, к числу которых можно отнести «Пиксель Тулс». После быстрой настройки параметров сбора, можно получить широкое семантического ядро в рамках тематики.
Анализ проведён с помощью инструментов в сервисе Пиксель Тулс.
Детальный анализ словоформ для ВЧ-запросов
Для ВЧ-запросов длиной в 2 и более слов может пригодиться анализ частоты встречаемости словоформ. Для этого требуется ввести исходную фразу, скажем, «продвижение сайтов» и далее последовательно исключать точные популярные написания с помощью комбинации операторов вида — -«», что приводит к исключению наиболее частотной формы написания из статистики и появлению второй по популярности версии. Далее процедуру можно повторить.
Инструменты для упрощения работы с «Вордстатом» – расширения и программы
Работать с «Вордстатом» просто – научиться сносно пользоваться пятью операторами можно за полчаса. А вот собирать большие объемы данных и работать с ними – уже сложнее. В первой части статьи были рассмотрены основы работы с «Вордстатом», потому что без понимания какие данные и почему отдаются сервисом, невозможно эффективно использовать средства автоматизации. Вот три самых популярных программы:
- «Яндекс Вордстат Ассистент»;
- «Яндекс Вордстат Хелпер»;
- «Кей Коллектор» (и его бесплатная версия).
«Яндекс Вордстат Ассистент»
На официальном сайте https://semantica.in/tools/yandex-wordstat-assistant выбираем браузер, который используется для работы. После установки возле каждого запроса появится возможность добавить или удалить его из списка:

Все «проплюсованные» запросы добавляются в список. После того, как все нужные запросы скопированы в список, можно:
- Посмотреть в списке количество добавленных фраз и их суммарную частотность (цифры 2 и 25 над списком на скриншоте выше).
- Скопировать фразы в буфер обмена.
- Скопировать фразы и их частотность в буфер обмена.
- Отсортировать запросы по убыванию или по возрастанию в алфавитном порядке, по порядку добавления в список или по частотности.
Основной плюс – простота использования, дополнение бесплатное. Основной минус – инструмент собирает только фразу и базовую частотность запроса.
«Яндекс Вордстат Хелпер»
Установить дополнение можно также выбрав браузер на странице официального сайта https://arcticlab.ru/yandex-wordstat-helper/

Фактически, это полный аналог предыдущего дополнения, но чуть более удобный (сортировку можно сделать в 1 клик).
Еще один недостаток обоих дополнений – муторная ручная работа при работе с большим количеством запросов. Я уже писал ранее, что популярный запрос может отдавать данные на 40 страницах по убыванию частотности. Чтобы только собрать эти данные, нужно будет произвести более 80 кликов (40 переходов на следующую страницу и 40 добавлений запросов в дополнение).
«Кей Коллектор», описание и настройка парсера данных из «Яндекс.Вордстат»
По сути, это комбайн для работы с данными. Я не буду пересказывать справку программы, а напишу только о плюсах и минусах «Кей Коллектора» при работе с «Вордстатом».
Сначала о минусах. Их всего четыре:
- Как я уже писал, программа платная.
- Потребуется завести отдельные аккаунты в «Яндексе» для «Кей Коллектора», так как при частых автоматических запросах может быть затруднен доступ к «Вордстату» (будет выбиваться несколько капч на каждый запрос).
- Нужно будет 1 раз настроить программу по справке или по скриншотам моих настроек для быстрого сбора данных.
- Потребуется оплатить 1 из сервисов антикапчи, чтобы можно было поставить программу на сбор данных и забыть о ней. Хотя я собираю данные в промышленных объемах (сотни тысяч запросов в месяц), мне на 3 компьютера хватает 150–350 рублей в месяц на оплату антикапча-сервисов.
Теперь интерфейс:

Полный обзор возможностей программы лежит за рамками темы о «Вордстате», потому что краткий видео обзор возможностей программы занимает около полутора часов. Я обозначу только настройки, которые нужны для того, чтобы быстро начать работать с «Вордстатом».

Три волшебных кнопки:
- Сбор фраз из «Яндекс Вордстат». Аналогично тому, как если бы вы руками с каждой страницы копировали запрос и частотность в таблицу.
- Сбор поисковых подсказок. Если вы каждую фразу будете вставлять в поиск и выписывать для нее поисковые подсказки – получите такой же результат, как и программа.
- Сбор частотностей в кавычках «» и с уточнением словоформы «!». Работает так же, как если бы вы каждый запрос вбивали с этими операторами и записывали цифры.
Порядок действий – сначала собираем запросы (1), затем частотность (3). По интересующим запросам собираем подсказки (2) и снова частотность (3).
Полученный результат:

Фактически, сбор десятков тысяч запросов со всеми данными занимает 2-3 часа.
Я приведу настройки, которые нужно сделать, чтобы собирать данные с лучшим сочетанием скорости и дешевизны (не супер быстро, но с небольшим расходом на антикапчу). По порядку:

Сбор разных видов частотностей проходит через «Яндекс.Директ» – настраиваем и его:

Кроме этого в верхней части этого окна нужно добавить несколько аккаунтов «Яндекса»:

И последнее что нужно сделать – зарегистрироваться в любом из совместимых сервисов разгадки капчи, получить в нем код для работы и ввести его в настройках:

Я пробовал разные схемы настроек, эта – самая эффективная и простая.
Остальные 200 кнопок и настроек я предлагаю вам освоить самостоятельно (-:
Существует и бесплатная версия «Кей Коллектора» – программа «Словоеб», которая так же позволяет полноценно работать с «Вордстатом». Ссылка на сайт программы.
Что такое яндекс вордстат хелпер?
Яндекс вордстат хелпер – полезное расширение, подходящее для сбора семантических ядер малого объема. В данном случае речи о кластеризации запросов не идет. Кроме того, нельзя с помощью Yandex Wordstat Helper воспользоваться и поиском подсказов, другими полезными опциями.
Это простейший скрипт, который хорош тем, что ускоряет работу с сервисом Wordstat. Виджет имеет несколько неоценимых функций, о которых более подробно будет сказано чуть ниже. Вордстат хелпер, к примеру, как нельзя лучше подойдет для сбора ключевых слов и фраз к постам интернет-блога. Разработчиками расширения являются сотрудники компании «Арктическая лаборатория».
Yandex Wordstat Assistant
Сначала рассмотрим как пользоваться Yandex Wordstat Assistant. Приложение разработано компанией Semantica, официальная страница с описанием находится здесь.
Там, как видите, указана поддержка всего трех браузеров: Яндекс, Google Chrome и Opera, хотя в каталоге Firefox плагинов можно найти и скачать Yandex Wordstat Assistant для Firefox (Mozilla).
Алгоритм работы с программой:
- Первым делом требуется установить аддон под тот браузер, который вы используете.
- Потом переходите в сервис статистики поисковых запросов и вводите интересующую вас фразу.
- Для добавления подходящего ключевого слова в список нужно нажать на «плюс», для удаления – на «минус» в окне виджета или в статистике.
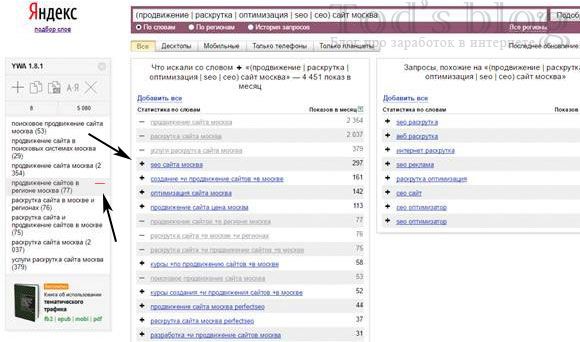
Дубли автоматически удаляются. Расширение собирает не только фразы, но и их частотность. Также подсчитывается суммарный показатель всех добавленных фраз и их количество.
Есть возможность свободного включения в ваше семантическое ядро с Wordstat своих дополнительных фраз. В этом случае частотность не определяется, и вместо нее будет знак вопроса.
Сортировка списка в Yandex Wordstat Assistant настраивается:
- по алфавиту от А до Я и в обратном направлении;
- по возрастанию или убыванию частотности;
- по порядку включения.
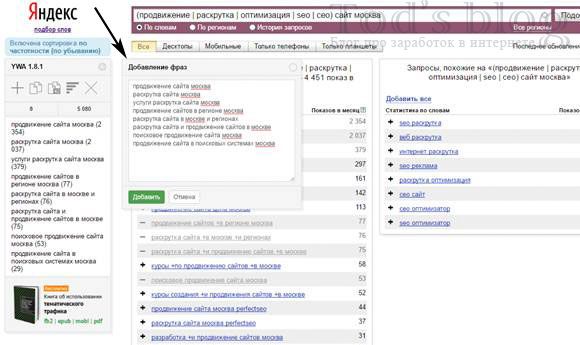
Для удобства добавленные слова могут обесцвечиваться, или перед ними просто появится знак «минус» (это настраивается). Также имеется дополнительная опция, которая удаляет из фраз плюсы перед стоп-словами.
Полученную заготовку семантического ядра из Wordstat Assistant скачать можно в буфер в один клик. При этом допускается копирование фраз с частотностью, так и без нее. В первом случае при вставке в Excel данные автоматически разбиваются на два столбца.
Вкладки синхронизируются, не очищаются при закрытии.
Анализ ключевых слов конкурентов
1. Serpstat
Serpstat — cервис позволяет получить информацию о ключевых словах конкурентов в SEO и контекстной рекламе. Умеет работать с разными регионами мира и поисковыми системами.
Тарифы стартуют от 69$ до 499$.
Есть trial.
2. SpyWords
SpyWords — полезный сервис позволяющий узнать ключевые слова конкурентов, осуществить подбор ключевых слов для сайта, сравнить видимость и другие параметры на уровне доменов.
Возможности сервиса:
- Анализ конкурентов
- Сравнение доменов
- Продвинутое сравнение
- Рейтинг доменов
- Умный подбор запросов
- Сравнение позиций
Тарифы от 1 978 руб. до 4 950 руб.
3. Keys.so
Keys.so — дает возможность анализа сайта по видимости в поисковых системах, в сетях контекстной рекламы. Оценивает стоимость трафика и ключевых слов.
Стоимость от 1 500 руб./мес. до 14 500 руб./мес. в зависимости от выбранного тарифа (есть скидки при оплате сразу за год).
При подписке на “Базовый” или “Корпоративный тариф” открывается возможность использовать функционал “СемЯдро”.
“СемЯдро” — модуль, позволяющий быстро и удобно создать семантическое ядро для сайта или рекламной кампании с помощью древовидных структур и автоматической кластеризации.
4. SimilarWeb
SimilarWeb — всемирный сервис для анализа сайтов, в платной версии позволяет узнать ключевые фразы, источники трафика и так далее.
Есть свободный тариф и тариф для компаний — от 199$.
5. Ahrefs
Ahrefs — глобальный сервис для анализа сайтов, не так давно начал работать с ключевыми фразами. Позволяет оценить ключевые фразы конкурентов, наиболее популярный контент и много других параметров.
Недавно появилась обновленная версия Ahrefs Site Explorer с усовершенствованным функционалом для работы с ключевыми словами.
Стоимость тарифных планов: от 82$ до 832$ в месяц (+возможность получить скидку при оплате за год).
6. Semrush
Semrush — сервис отлично работает с западным сегментом, позволяет проанализировать ключевые слова, оценить конкурентов, увидеть распределение трафика по страницам и т.д. С русскоязычным сегментом работает хуже.
Стоимость подписки стартует от 119$ и до 449$ в месяц.
7. SpyFu
SpyFu — анализ конкурентов в разрезе платного и бесплатного трафика. Отличный удобный интерфейс. Один из лидеров западного рынка по работе с ключевыми словами.
Подписка стоит от 33$ до 299$ в месяц.
|
Название |
Описание |
Тарифы |
Trial |
|
Serpstat |
Cервис позволяет получить информацию о ключевых словах конкурентов в SEO и контекстной рекламе |
от 69$ до 499$ |
Есть |
|
SpyWords |
Сервис позволяющий узнать ключевые слова конкурентов, осуществить подбор ключевых слов для сайта, сравнить видимость и другие параметры на уровне доменов |
от 1 978 руб. до 4 950 руб. |
Нет |
|
Keys.so |
Сервис дает возможность анализа сайта по видимости в поисковых системах, в сетях контекстной рекламы. Оценивает стоимость трафика и ключевых слов |
от 1 500 руб./мес. до 14 500 руб./мес. |
Нет |
|
SimilarWeb |
Сервис для анализа сайтов, в платной версии позволяет узнать ключевые фразы, источники трафика |
от 199$/мес. |
Есть |
|
Ahrefs |
Сервис для анализа сайтов, позволяет оценить ключевые фразы конкурентов, наиболее популярный контент и много других параметров |
от 82$ до 832$ в месяц |
Есть |
|
Semrush |
Сервис отлично работает с западным сегментом, позволяет проанализировать ключевые слова, оценить конкурентов, увидеть распределение трафика по страницам |
от 119$ и до 449$ в месяц |
Есть |
|
SpyFu |
Анализ конкурентов в разрезе платного и бесплатного трафика |
от 33$ до 299$ в месяц |
Нет |
Минус-режим
В основном из-за этой функции я перешел на это расширение с другого. Поэтому посвящу ей отдельный раздел. Его можно включить кликом по off как на скрине выше, горячей клавишей Ctrl+Q либо кликом на ярлычке
После активации режима вы можете просто кликать по нужному слову и оно выделится красным во всех фразах
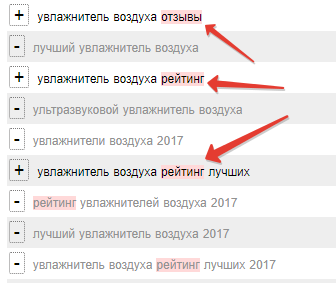
А еще добавится на вкладку списка минус-слов.
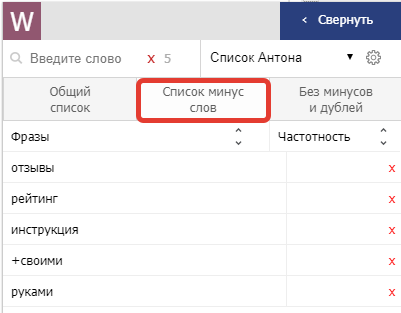
Этот список также можно копировать, очищать, вставлять в него фразы из буфера.
С помощью этого функционала я быстро копирую эти фразы в Стоп-слова в KeyCollector перед запуском парсинга Wordstat.
Теперь самое интересное: одним кликом эти слова добавляются в запрос и минусуются, позволяя увидеть чистую частотность (согласен, тут криво смотрится «-+своими», но это слово минусуется по факту). Всегда не любил добавлять минусы руками =)
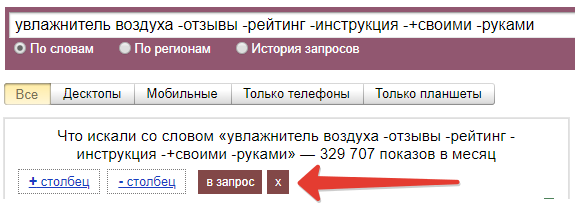
Нажатием на крестик минус-слова убираются из строки поиска.
На вкладке «Без минусов и дублей» можно найти фразы из исходного списка за вычетом фраз, содержащих минус-слова. Его все так же можно скопировать.
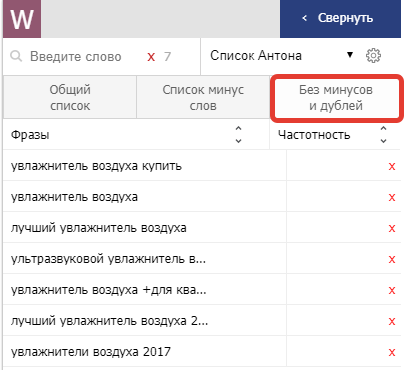
Также на вкладке минус-слов можно заметить Бета-функцию ГЕО.
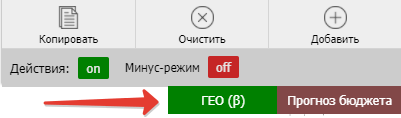
По клику появляется список регионов. Мы ставим галочки в ненужных нам регионах и нажимаем «Добавить».
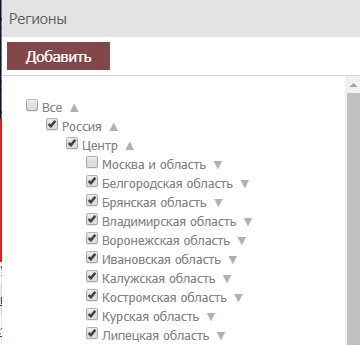
И получаем в списке минус-слов города, районы, области, округа из выбранных пунктов, чтобы быстро отминусовать их из запросов.
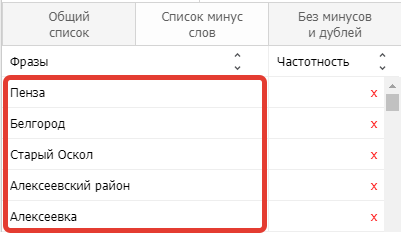
Напоминает аналогичный удобный функционал минусовки нерелевантных регионов в Rush Analytics. Можно пользоваться, но отминусуются только точные вхождения, а не склонения.