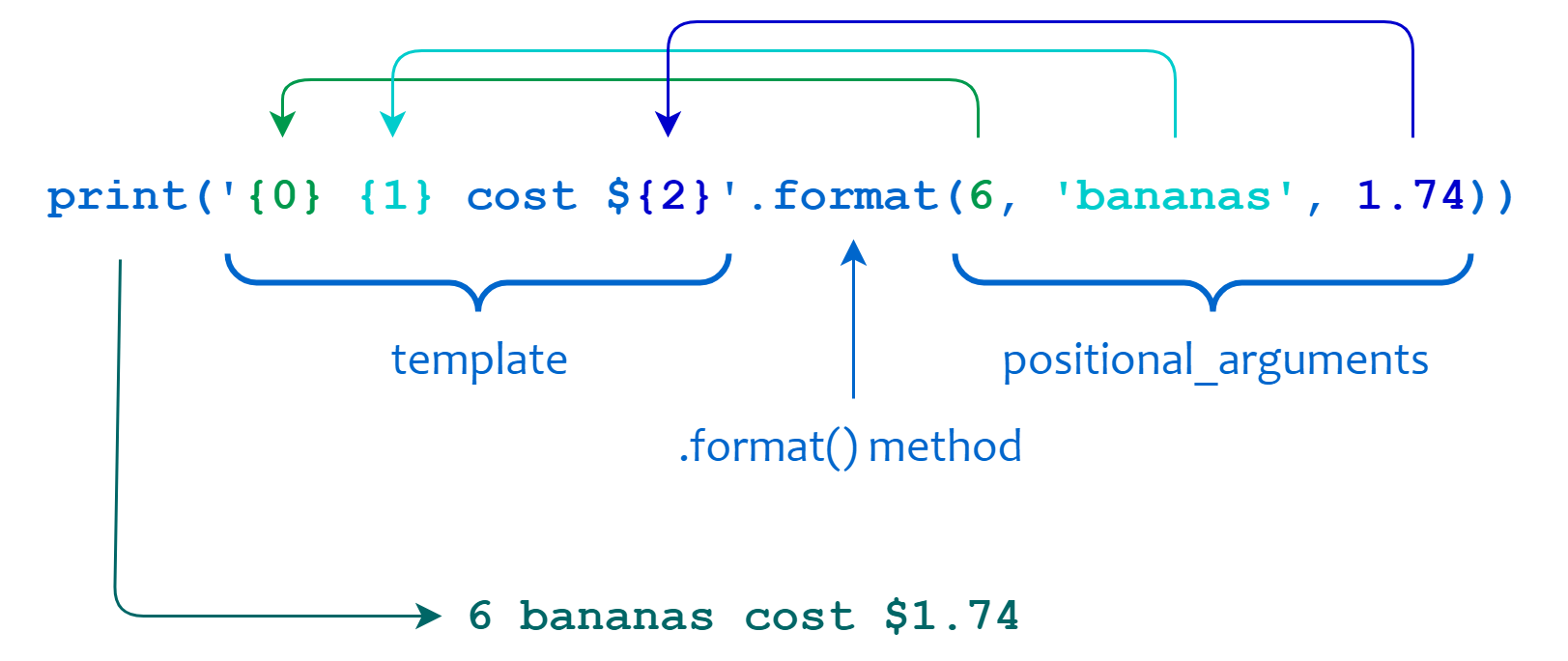
Строковые методы в python
Содержание:
- 2 ответа
- Python split String Syntax
- Блокировки как менеджеры контекста
- Строки байтов — bytes и bytearray
- Строки нарезки в Python – примеры
- Конкатенация строк
- Создает строку из списка строк.
- Ограничение одновременного доступа к ресурсам
- Методы строк
- Join Two Sets
- Специфичные для потока данные
- Работа с часовыми поясами
- Join Two or More Tables
- Определение текущего потока
- Что насчёт поиска в строке?
- Python NumPy
2 ответа
Лучший ответ
Согласованность .
Вам нужно будет следовать некоторым очень простым и, казалось бы, неуместным объяснениям, чтобы понять это.
В школе вы выучили деление с остатком. И вы сделали расчеты следующим образом:
Позже вы выучили деления на действительные числа:
До этого момента вы можете полагать, что и всегда дают один и тот же результат. Это ваше текущее понимание ситуации.
Однако посмотрите, что происходит в целочисленном делении: число за R циклически изменяется от 3, 2, 1 до 0, а затем перезапускается: 3, 2, 1, 0. Число перед R уменьшается с каждым 4-м шагом.
Итак, как это будет продолжаться?
В то же время деление действительных чисел дает нам:
Вот почему дает -1, а дает 0.
Ну, они служат различным целям: является частью вычисления целых чисел с остатками, а дает вам часть перед операции с действительным числом.
Вы решаете, что вы хотите вычислить, затем вы решаете, какой оператор использовать в Python, чтобы получить правильный результат.
Хороший вопрос. Продолжайте учиться.
61
Thomas Weller
12 Дек 2019 в 12:56
Я бы сказал, что ваше наблюдение о том, что эти 2 операции должны быть интуитивно схожими, ожидается, поскольку при положительных числах они ведут себя одинаково. Но если вы посмотрите на их происхождение (одно из математики, а другое — из информатики), тогда будет более понятно их различное поведение.
Вы можете посмотреть там концепции:
- Этажное деление или функция пола, применяемое к математическому разделению
- Тип преобразования / Тип литья
================================================== ================
I) Этажное деление или функция пола, применяемая к математическому разделу
Функция пола — очень хорошо зарекомендовавшая себя концепция математики.
Из mathworld.wolfram:
Таким образом, разделение по этажам — это не более, чем функция по этажам, применяемая к математическому разделению. Поведение очень ясное, «математически точное».
II) Преобразование типов / приведение типов
Из википедии:
В большинстве языков программирования приведение формы с плавающей точкой к целому числу применяется правилом округления (поэтому существует соглашение):
Округление к 0 — направленное округление к нулю (также известное как усечение)
Правило округления в соответствии с IEEE 754.
Итак, другими словами, причина различия между целочисленным делением и преобразованием с плавающей точкой в int в python является математической, вот некоторые мысли от Гвидо ван Россума (думаю, мне не нужно его представлять: D) (из блог История Python, статья «Почему Python Целочисленное деление этажей «)
4
rusu_ro1
7 Янв 2020 в 22:09
Python split String Syntax
The syntax of the Python String split function is
- String_Value: A valid String variable, or you can use the String directly.
- Separator (Optional arg): If you forget this argument, the python split string function uses Empty Space as the separator.
- Max_Split: This argument is optional. If you specify this value then, split function restricts the list of words.
Python split function returns a List of words. For example, If we have X*Y*Z and If we use * as a separator, split function search for * from left to right. Once the split function finds *, Python returns the string before the * symbol as List Item 1 (X) so on and so forth.
If you add Max_Split argument to the above example, X*Y*Z.split(‘*’, 1), python split function search for *. Once it finds *, the split function returns the string before the * symbol as List Item 1 (X) and returns the remaining string as list item 2.
Блокировки как менеджеры контекста
Блокировки реализуют API context manager и совместимы с оператором with. Использование оператора with позволяет обойтись без блокировки.
import threading import logging logging.basicConfig(level=logging.DEBUG, format='(%(threadName)-10s) %(message)s', ) def worker_with(lock): with lock: logging.debug('Lock acquired via with') def worker_no_with(lock): lock.acquire() try: logging.debug('Lock acquired directly') finally: lock.release() lock = threading.Lock() w = threading.Thread(target=worker_with, args=(lock,)) nw = threading.Thread(target=worker_no_with, args=(lock,)) w.start() nw.start()
Функции worker_with() и worker_no_with() управляют блокировкой эквивалентными способами.
$ python threading_lock_with.py (Thread-1 ) Lock acquired via with (Thread-2 ) Lock acquired directly
Строки байтов — bytes и bytearray
Определение которое мы дале в самом начале можно считать верным только для строк типа str. Но в Python имеется еще два дугих типа строк: bytes – неизменяемое строковое представление двоичных данных и bytearray – тоже что и bytes, только допускает непосредственное изменение.
Основное отличие типа str от bytes и bytearray заключается в том, что str всегда пытается превратить последовательность байтов в текст указанной кодировки. По умолчанию этой кодировкой является utf-8, но это очень большая кодировка и другие кодировки, например ASCII, Latin-1 и другие являются ее подмножествами
Одни символы кодируются одним байтом, другие двумя, а некоторые тремя и функция при декодировании последовательности байтов принимает это во внимание. А вот функциям и до этого нет дела, для них абсолютно все данные состоят только из последовательности одиночных байтов.
Такое поведение bytes и bytearray очень удобно, если вы работаете с изображениями, аудиофайлами или сетевым трафиком. В этом случае, вам следует знать, что ничего магического в этих типах нет, они поддерживоют все теже строковые методы, операции индексирования, а так же операторы и функции для работы с последовательностями. Единственное, что следует держать в уме, так это то, что вы имеете дело с последовательностью байтов, т.е. последовательностью чисел из интервала в шестнадцатеричном представлении, и что байтовые строки отличаются от обычных символом (реже) предваряющим все литералы обычных строк.
Например, что бы создать строку типа bytes или bytearray достаточно передать соответствующим функциям последовательности целых чисел:
Учитывая то, что для кодирования некоторых символов (например ASCII) достаточно всего одного байта, данные типы пытаются представить последовательности в виде символов если это возможно. Например, строка будет выведена как :
А это значит, что байтовые данные могут вполне обоснованно интерпретированться как ASCII символы и наоборот. Т.е. строки байтов могут быть созданы и так:
Но, следует помнить что это все-таки байты, в чем легко убедиться, если мы обратимся к какому-нибудь символу по его индексу в строке:
Так как строковые методы не изменяют сам объект, а создают новый, то при работе с очень длинными строками (а в мире двоичных данных это далеко не редкость) это может привести к большому расходу памяти. Собственно, по этой причине и существует тип bytearray, который позволяет менять байты прямо внутри строки:
Строки нарезки в Python – примеры
Струны нарезки Python могут быть сделаны по-разному.
Обычно мы получаем доступ к строковым элементам (символам) с помощью простой индексации, которая начинается с до N-1 (n – длина строки). Следовательно, для доступа к 1-й Элемент строки Мы можем просто использовать код ниже.
s1 = String1
Опять же, есть еще один способ получить доступ к этим персонажам, то есть используя Отрицательная индексация Отказ Отрицательная индексация начинается с -1 к -n (n – длина для данной строки). Примечание, отрицательная индексация выполняется с другого конца строки. Следовательно, для доступа к первому символу на этот раз нам нужно следовать указанному ниже коду.
s1 = String1
Теперь давайте рассмотрим некоторые способы, следующие, которые мы можем нарезать строку, используя вышеуказанную концепцию.
1. Строки нарезки в Python с началом и концом
Мы можем легко нарезать данную строку, упомянувая начальные и окончательные индексы для желаемой подковы, которую мы ищем. Посмотрите на приведенный ниже пример, он объясняет нарезку строк, используя начальные и окончательные индексы для обычной, так и для негативного метода индексации.
#string slicing with two parameters
s = "Hello World!"
res1 = s
res2 = s #using negative indexing
print("Result1 = ",res1)
print("Result2 = ",res2)
Выход :
Result1 = llo Wo Result2 = rld
Здесь,
- Мы инициализируем строку, как “Привет мир!” ,
- Сначала мы нарезаем данную строку с начальным индексом 2 и окончание индекса как 8 Отказ Это означает, что результирующая подконта будет содержать символы из S к S ,
- Аналогично, для следующего, результирующая подкора должна содержать символы из S к S Отказ
Следовательно, наш выход оправдан.
2. Струки срез, используя только начало или конец
Как упоминалось ранее, все три параметра для нарезки строки являются необязательными. Следовательно, мы можем легко выполнить наши задачи с использованием одного параметра. Посмотрите на код ниже, чтобы получить четкое понимание.
#string slicing with one parameter
s1= "Charlie"
s2="Jordan"
res1 = s1 #default value of ending position is set to the length of string
res2 = s2 #default value of starting position is set to 0
print("Result1 = ",res1)
print("Result2 = ",res2)
Выход :
Result1 = arlie Result2 = Jord
Здесь,
Сначала инициализируем две строки, S1 и S2 , Для нарезки их обоих мы просто упомяну о start_pos Для S1 и End_Pos только для S2, Следовательно, для RES1 , он содержит подконтную строку S1 из индекса 2 (как упоминалось) до последнего (по умолчанию он устанавливается на N-1)
Принимая во внимание, что для RES2 диапазон индексов лежит от 0 до 4 (упомянутых).
3. Строки нарезки в Python со ступенчатым параметром
Значение решает прыжок операции нарезки займет из одного индекса к другому. Посмотрите на пример ниже.
#string slicing with step parameter
s= "Python"
s1="Kotlin"
res = s
res1 = s1 #using negative parameters
print("Resultant sliced string = ",res)
print("Resultant sliced string(negative parameters) = ",res1)
Выход :
Resultant sliced string = Pto Resultant sliced string(negative parameters) = nl
В коде выше,
- Мы инициализируем две строки S и S1 и попытайтесь нарезать их за данные начальные и окончательные индексы, как мы сделали для нашего первого примера,
- Но на этот раз мы упомянули шаг значение, которое было установлено на 1 по умолчанию для предыдущих примеров,
- Для RES, имеющих размер шага 2 означает, что, в то время как прохождение для получения подстроки от индекса от 0 до 4, каждый раз, когда индекс будет увеличен по значению 2. То есть первый символ S («P») следующие символы в подпологе будут S и S до тех пор, пока индекс не будет меньше 5.
- Для следующего я. RES1 Упомянутый шаг (-2). Следовательно, похоже на предыдущий случай, персонажи в подстроке будут S1 Тогда S1 или S1 до тех пор, пока индекс не будет меньше (-4).
4. Реверсируя строку с помощью нарезки в Python
С использованием отрицательной индексной строки нарезки в Python мы также можем поменять строку и хранить ее в другой переменной. Для этого нам просто нужно упомянуть Размер (-1) Отказ
Давайте посмотрим, как это работает в приведенном ниже примере.
#reversing string using string slicing s= "AskPython" rev_s = s #reverse string stored into rev_s print(rev_s)
Выход :
nohtyPksA
Как мы видим, строка S обращается и хранится в Отказ Примечание : Для этого тоже исходная строка остается неповрежденной и нетронутой.
Конкатенация строк
Конкатенация – это важный момент, это означает соединение или добавление двух объектов вместе. В нашем случае, нам нужно узнать, как добавить две строки вместе. Как вы можете догадаться, в Python эта операция очень простая:
Python
# -*- coding: utf-8 -*-
string_one = «Собака съела »
string_two = «мою книгу!»
string_three = string_one + string_two
print(string_three) # Собака съела мою книгу!
|
1 |
# -*- coding: utf-8 -*- string_one=»Собака съела « string_two=»мою книгу!» string_three=string_one+string_two print(string_three)# Собака съела мою книгу! |
Оператор + конкатенирует две строки в одну
Создает строку из списка строк.
Описание:
Метод возвращает строку, которая является конкатенацией (объединением) всех элементов строк итерируемого объекта .
В итоговой строке элементы объединяются между собой при помощи строки-разделителя .
Если в последовательности есть какие-либо НЕ строковые значения, включая байтовые строки , то поднимается исключение .
Примеры создания строки из списка строк.
>>> x = 'возвращает', 'строку', 'которая',
'является', 'конкатенацией'
# объединение списка строк с разделителем "пробел"
>>> line = ' '.join(x)
>>> line
# 'возвращает строку которая является конкатенацией'
# в качестве разделителя символ новой строки '\n'
>>> line = '\n'.join(x)
>>> line
# 'возвращает\nстроку\nкоторая\nявляется\nконкатенацией'
>>> print(line)
# возвращает
# строку
# которая
# является
# конкатенацией
Очень часто метод используется для формирования какого то итогового сообщения, в зависимости от условий в программе. В начале кода определяется пустой список, а по ходу программы, в результате проверок, добавляются части выходного сообщения (например при проверке корректности заполнения полей формы).
В примере будем использовать словарь из двух списков — (для ошибок) и (для итогового сообщения):
# здесь поступают какие то данные, пускай
# num - должно быть целым числом
# name - имя, которое должно быть не менее 3-х букв
content = {'message' [], 'error' []}
# далее идет код проверок например:
if num
if type(num) is int
content'message'.append(f' - Введено число {num}')
else
content'error'.append(f' - {num} - это не целое число')
else
content'error'.append(' - Вы не ввели число')
if name
if len(name) > 3
content'message'.append(f' - Введено имя: {name}')
else
content'error'.append(' - Имя не должно быть короче 3-х букв')
else
content'error'.append(' - Вы не ввели имя')
# в конце кода итоговые проверки и вывод сообщения
if content'error']:
# если есть какие-то ошибки
content'error'.insert(, 'При вводе данных возникли ошибки:\n')
result_message = '\n'.join(content'error'])
else
# если все хорошо.
content'message'.insert(, 'Результаты ввода данных:\n')
result_message = '\n'.join(content'message'])
print(result_message)
Как добавить/соединить существующую строку со списком строк.
Очень просто. Необходимо существующую строку добавить в начало списка методом изменяющихся последовательностей , а затем применить метод .
# начальная строка >>> line = 'Состав корзины покупателя:' # список строк, которые нужно добавить >>> lst_line = '- картошка', '- морковь', '- лук', '- чеснок', '- свекла' # вставляем начальную строку по индексу 0 в список >>> lst_line.insert(, line) # объединяем список строк по разделителю '\n' >>> rez = '\n'.join(lst_line) >>> print(rez) # Состав корзины покупателя: # - картошка # - морковь # - лук # - чеснок # - свекла
Конечно данную операцию можно осуществить другим способом, при помощи оператора присваивания на месте . Но такой код будет работать значительно дольше и потреблять больше памяти, особенно это заметно, когда строк очень много.
Ограничение одновременного доступа к ресурсам
Как разрешить доступ к ресурсу нескольким worker одновременно, но при этом ограничить их количество. Например, пул соединений может поддерживать фиксированное число одновременных подключений, или сетевое приложение может поддерживать фиксированное количество одновременных загрузок. Semaphore является одним из способов управления соединениями.
import logging
import random
import threading
import time
logging.basicConfig(level=logging.DEBUG,
format='%(asctime)s (%(threadName)-2s) %(message)s',
)
class ActivePool(object):
def __init__(self):
super(ActivePool, self).__init__()
self.active = []
self.lock = threading.Lock()
def makeActive(self, name):
with self.lock:
self.active.append(name)
logging.debug('Running: %s', self.active)
def makeInactive(self, name):
with self.lock:
self.active.remove(name)
logging.debug('Running: %s', self.active)
def worker(s, pool):
logging.debug('Waiting to join the pool')
with s:
name = threading.currentThread().getName()
pool.makeActive(name)
time.sleep(0.1)
pool.makeInactive(name)
pool = ActivePool()
s = threading.Semaphore(2)
for i in range(4):
t = threading.Thread(target=worker, name=str(i), args=(s, pool))
t.start()
В этом примере класс ActivePool является удобным способом отслеживания того, какие потоки могут запускаться в данный момент. Реальный пул ресурсов будет выделять соединение для нового потока и восстанавливать значение, когда поток завершен. В данном случае он используется для хранения имен активных потоков, чтобы показать, что только пять из них работают одновременно.
$ python threading_semaphore.py 2013-02-21 06:37:53,629 (0 ) Waiting to join the pool 2013-02-21 06:37:53,629 (1 ) Waiting to join the pool 2013-02-21 06:37:53,629 (0 ) Running: 2013-02-21 06:37:53,629 (2 ) Waiting to join the pool 2013-02-21 06:37:53,630 (3 ) Waiting to join the pool 2013-02-21 06:37:53,630 (1 ) Running: 2013-02-21 06:37:53,730 (0 ) Running: 2013-02-21 06:37:53,731 (2 ) Running: 2013-02-21 06:37:53,731 (1 ) Running: 2013-02-21 06:37:53,732 (3 ) Running: 2013-02-21 06:37:53,831 (2 ) Running: 2013-02-21 06:37:53,833 (3 ) Running: []
Методы строк
Строка является объектом в Python. Фактически, все, что есть в Python – является объектом. Если вы хотите узнать больше об Объектно-ориентированном программирование, мы рассмотрим это в другой статье «Классы в Python«. В данный момент достаточно знать, что строки содержат собственные встроенные методы. Например, допустим, у вас есть следующая строка:
Python
my_string = «This is a string!»
| 1 | my_string=»This is a string!» |
Теперь вам нужно сделать так, чтобы вся эта строка была в верхнем регистре. Чтобы сделать это, все, что вам нужно, это вызвать метод upper(), вот так:
Python
my_string.upper()
| 1 | my_string.upper() |
Если вы открыли ваш интерпретатор, вы также можете сделать то же самое:
Python
«This is a string!».upper()
| 1 | «This is a string!».upper() |
Существует великое множество других методов строк. Например, если вам нужно, что бы все было в нижнем регистре, вам нужно использовать метод lower(). Если вы хотите удалить все начальные и конечные пробелы, вам понадобится метод strip(). Для получения списка всех методов строк, впишите следующую команду в ваш интерпретатор:
Python
dir(my_string)
| 1 | dir(my_string) |
Вы увидите что-то на подобие этого:
Python
|
1 |
‘__add__’,‘__class__’,‘__contains__’,‘__delattr__’,‘__doc__’,‘__eq__’,‘__format__’, ‘__ge__’,‘__getattribute__’,‘__getitem__’,‘__getnewargs__’,‘__getslice__’,‘__gt__’, ‘__hash__’,‘__init__’,‘__le__’,‘__len__’,‘__lt__’,‘__mod__’,‘__mul__’,‘__ne__’, ‘__new__’,‘__reduce__’,‘__reduce_ex__’,‘__repr__’,‘__rmod__’,‘__rmul__’,‘__- setattr__’,‘__sizeof__’,‘__str__’,‘__subclasshook__’,‘_formatter_field_name_split’, ‘_formatter_parser’,‘capitalize’,‘center’,‘count’,‘decode’,‘encode’,‘endswith’,‘expandtabs’, ‘find’,‘format’,‘index’,‘isalnum’,‘isalpha’,‘isdigit’,‘islower’,‘isspace’, ‘istitle’,‘isupper’,‘join’,‘ljust’,‘lower’,‘lstrip’,‘partition’,‘replace’,‘rfind’,‘rindex’, ‘rjust’,‘rpartition’,‘rsplit’,‘rstrip’,‘split’,‘splitlines’,‘startswith’,‘strip’,‘swapcase’, ‘title’,‘translate’,‘upper’,‘zfill’ |
Вы можете спокойно игнорировать методы, которые начинаются и заканчиваются двойным подчеркиванием, например __add__. Они не используются в ежедневном программировании в Python
Лучше обратите внимание на другие. Если вы хотите узнать, что делает тот или иной метод, просто обратитесь к справке. Например, если вы хотите узнать, зачем вам capitalize, впишите следующее, чтобы узнать:
Например, если вы хотите узнать, зачем вам capitalize, впишите следующее, чтобы узнать:
Python
help(my_string.capitalize)
| 1 | help(my_string.capitalize) |
Вы получите следующую информацию:
Python
Help on built-in function capitalize:
capitalize(…)
S.capitalize() -> string
Выдача копии строки S только с заглавной буквой.
|
1 |
Help on built-in function capitalize: capitalize(…) S.capitalize() -> string Выдача копии строки S только с заглавной буквой. |
Вы только что узнали кое-что о разделе, под названием интроспекция. Python может исследовать все свои объекты, что делает его очень легким в использовании. В основном, интроспекция позволяет вам спрашивать Python о нём. Вам моет быть интересно, как сказать о том, какой тип переменной был использован (другими словами int или string). Вы можете спросить об этом у Python!
Python
type(my_string) # <type ‘str’>
| 1 | type(my_string)# <type ‘str’> |
Как вы видите, тип переменной my_string является str!
Join Two Sets
There are several ways to join two or more sets in Python.
You can use the method that returns a new set containing all items from both sets,
or the method that inserts all the items from one set into another:
Example
The method returns a new set with all items from both sets:
set1 = {«a», «b» , «c»}set2 = {1, 2, 3}
set3 = set1.union(set2)print(set3)
Example
The method inserts the items in set2 into set1:
set1 = {«a», «b» , «c»}set2 = {1, 2, 3}
set1.update(set2)print(set1)
Note: Both and
will exclude any duplicate items.
There are other methods that joins two sets and keeps ONLY the duplicates, or NEVER the duplicates,
check all the built-in set methods in Python.
Python Sets Tutorial
Set
Access Set Items
Add Set Items
Loop Set Items
Check if Set Item Exists
Set Length
Remove Set Items
Специфичные для потока данные
Некоторые ресурсы должны быть заблокированы, чтобы их могли использовать сразу несколько потоков. А другие должны быть защищены от просмотра в потоках, которые не «владеют» ими. Функция local() создает объект, способный скрывать значения для отдельных потоков.
import random
import threading
import logging
logging.basicConfig(level=logging.DEBUG,
format='(%(threadName)-10s) %(message)s',
)
def show_value(data):
try:
val = data.value
except AttributeError:
logging.debug('No value yet')
else:
logging.debug('value=%s', val)
def worker(data):
show_value(data)
data.value = random.randint(1, 100)
show_value(data)
local_data = threading.local()
show_value(local_data)
local_data.value = 1000
show_value(local_data)
for i in range(2):
t = threading.Thread(target=worker, args=(local_data,))
t.start()
Обратите внимание, что значение local_data.value не доступно ни для одного потока, пока не будет установлено
$ python threading_local.py (MainThread) No value yet (MainThread) value=1000 (Thread-1 ) No value yet (Thread-1 ) value=34 (Thread-2 ) No value yet (Thread-2 ) value=7
Чтобы все потоки начинались с одного и того же значения, используйте подкласс и установите атрибуты с помощью метода __init __() .
import random
import threading
import logging
logging.basicConfig(level=logging.DEBUG,
format='(%(threadName)-10s) %(message)s',
)
def show_value(data):
try:
val = data.value
except AttributeError:
logging.debug('No value yet')
else:
logging.debug('value=%s', val)
def worker(data):
show_value(data)
data.value = random.randint(1, 100)
show_value(data)
class MyLocal(threading.local):
def __init__(self, value):
logging.debug('Initializing %r', self)
self.value = value
local_data = MyLocal(1000)
show_value(local_data)
for i in range(2):
t = threading.Thread(target=worker, args=(local_data,))
t.start()
__init __() вызывается для каждого объекта (обратите внимание на значение id()) один раз в каждом потоке
$ python threading_local_defaults.py (MainThread) Initializing <__main__.MyLocal object at 0x100514390> (MainThread) value=1000 (Thread-1 ) Initializing <__main__.MyLocal object at 0x100514390> (Thread-1 ) value=1000 (Thread-2 ) Initializing <__main__.MyLocal object at 0x100514390> (Thread-1 ) value=81 (Thread-2 ) value=1000 (Thread-2 ) value=54
Работа с часовыми поясами
Выбор функции для определения текущего времени зависит от того, установлен ли часовой пояс программой или системой. Изменение часового пояса не изменяет фактическое время — только способ его представления.
Чтобы изменить часовой пояс, установите переменную среды TZ, затем вызовите tzset(). Часовой пояс можно указать с различными данными, вплоть до времени начала и завершения периода так называемого «летнего» времени. Проще всего использовать название часового пояса, но базовые библиотеки получают и другую информацию.
Приведенная ниже программа без time sleep python, и задает несколько разных значений для часового пояса и показывает, как изменения влияют на другие настройки в модуле времени:
time_timezone.py
import time
import os
def show_zone_info():
print(' TZ :', os.environ.get('TZ', '(not set)'))
print(' tzname:', time.tzname)
print(' Zone : {} ({})'.format(
time.timezone, (time.timezone / 3600)))
print(' DST :', time.daylight)
print(' Time :', time.ctime())
print()
print('Default :')
show_zone_info()
ZONES = [
'GMT',
'Europe/Amsterdam',
]
for zone in ZONES:
os.environ = zone
time.tzset()
print(zone, ':')
show_zone_info()
Часовой пояс по умолчанию для системы, используемой в примерах — US / Eastern. Другие зоны в примере, который позволяет реализовать модуль time Python изменяют значение tzname, продолжительности светового дня и значение смещения часового пояса:
$ python3 time_timezone.py
Default :
TZ : (not set)
tzname: ('EST', 'EDT')
Zone : 18000 (5.0)
DST : 1
Time : Sun Aug 14 14:10:42 2016
GMT :
TZ : GMT
tzname: ('GMT', 'GMT')
Zone : 0 (0.0)
DST : 0
Time : Sun Aug 14 18:10:42 2016
Europe/Amsterdam :
TZ : Europe/Amsterdam
tzname: ('CET', 'CEST')
Zone : -3600 (-1.0)
DST : 1
Time : Sun Aug 14 20:10:42 2016
Join Two or More Tables
You can combine rows from two or more tables, based on a related column
between them, by using a JOIN statement.
Consider you have a «users» table and a «products» table:
users
{ id: 1, name: ‘John’, fav: 154},{ id:
2, name: ‘Peter’, fav: 154},{ id: 3, name: ‘Amy’, fav: 155},{ id: 4, name: ‘Hannah’, fav:},{ id: 5, name: ‘Michael’, fav:}
products
{ id: 154, name:
‘Chocolate Heaven’ },{ id: 155, name: ‘Tasty Lemons’ },{
id: 156, name: ‘Vanilla Dreams’ }
These two tables can be combined by using users’ field and products’
field.
Example
Join users and products to see the name of the users favorite product:
import mysql.connectormydb = mysql.connector.connect( host=»localhost»,
user=»yourusername», password=»yourpassword», database=»mydatabase»)
mycursor = mydb.cursor()sql = «SELECT \ users.name AS user,
\ products.name AS favorite \ FROM users \ INNER JOIN
products ON users.fav = products.id»mycursor.execute(sql)
myresult = mycursor.fetchall()for x in myresult: print(x)
Note: You can use JOIN instead of INNER JOIN. They will
both give you the same result.
Определение текущего потока
Использование аргументов для идентификации потока является трудоемким процессом. Каждый экземпляр Thread имеет имя со значением, присваиваемым по умолчанию. Оно может быть изменено, когда создается поток.
Именование потоков полезно в серверных процессах с несколькими служебными потоками, обрабатывающими различные операции.
import threading
import time
def worker():
print threading.currentThread().getName(), 'Starting'
time.sleep(2)
print threading.currentThread().getName(), 'Exiting'
def my_service():
print threading.currentThread().getName(), 'Starting'
time.sleep(3)
print threading.currentThread().getName(), 'Exiting'
t = threading.Thread(name='my_service', target=my_service)
w = threading.Thread(name='worker', target=worker)
w2 = threading.Thread(target=worker) # используем имя по умолчанию
w.start()
w2.start()
t.start()
Программа выводит имя текущего потока в каждой строке. «Thread-1» — это безымянный поток w2.
$ python -u threading_names.py worker Thread-1 Starting my_service Starting Starting Thread-1worker Exiting Exiting my_service Exiting
Большинство программ не используют print для отладки. Модуль logging поддерживает добавление имени потока в каждое сообщение журнала с помощью % (threadName)s. Включение имен потоков в журнал облегчает отслеживание этих сообщений.
import logging
import threading
import time
logging.basicConfig(level=logging.DEBUG,
format=' (%(threadName)-10s) %(message)s',
)
def worker():
logging.debug('Starting')
time.sleep(2)
logging.debug('Exiting')
def my_service():
logging.debug('Starting')
time.sleep(3)
logging.debug('Exiting')
t = threading.Thread(name='my_service', target=my_service)
w = threading.Thread(name='worker', target=worker)
w2 = threading.Thread(target=worker) # use default name
w.start()
w2.start()
t.start()
Модуль logging также является поточно-ориентированным, поэтому сообщения из разных потоков сохранятся в выводимых данных.
$ python threading_names_log.py (worker ) Starting (Thread-1 ) Starting (my_service) Starting (worker ) Exiting (Thread-1 ) Exiting (my_service) Exiting
Что насчёт поиска в строке?
Самое быстрое — проверить, начинается ли (заканчивается ли) строка с выбранных символов. Для этого в Python предусмотрены специальные строковые методы.
Для поиск подстроки в произвольном месте есть метод с говорящим названием . Он вернет индекс начала найденного вхождения подстроки в строку, либо -1, если ничего не найдено.
Для сложных случаев, когда нужно найти не конкретную последовательность символов, а некий шаблон, помогут регулярные выражения. Они заслуживают отдельной статьи. Глубокого знания регулярок на собеседованиях не требуется, достаточно знать про них, уметь написать несложное выражение и прочитать чуть более сложное. Например, такое:
Python NumPy
NumPy IntroNumPy Getting StartedNumPy Creating ArraysNumPy Array IndexingNumPy Array SlicingNumPy Data TypesNumPy Copy vs ViewNumPy Array ShapeNumPy Array ReshapeNumPy Array IteratingNumPy Array JoinNumPy Array SplitNumPy Array SearchNumPy Array SortNumPy Array FilterNumPy Random
Random Intro
Data Distribution
Random Permutation
Seaborn Module
Normal Distribution
Binomial Distribution
Poisson Distribution
Uniform Distribution
Logistic Distribution
Multinomial Distribution
Exponential Distribution
Chi Square Distribution
Rayleigh Distribution
Pareto Distribution
Zipf Distribution
NumPy ufunc
ufunc Intro
ufunc Create Function
ufunc Simple Arithmetic
ufunc Rounding Decimals
ufunc Logs
ufunc Summations
ufunc Products
ufunc Differences
ufunc Finding LCM
ufunc Finding GCD
ufunc Trigonometric
ufunc Hyperbolic
ufunc Set Operations