Как организована информация в реляционной базе данных
Содержание:
- [править] Процедура нормализации
- СУБД
- Хранилище пар «ключ — значение»
- Структура реляционной модели данных
- Связывание таблиц
- Что такое нереляционная база данных
- Ключи в БД
- Таблица как важная часть реляционной БД
- Реляционная модель данных: кем, когда и для чего создана
- Проблемы модели
- Доля рынка
- Применение
- Операция проекции
- Хранилища данных графов
- Хранилища данных временных рядов
- Хранилища данных документов
- SQL и NoSQL
- Графы
- Подводим итоги проектирования
[править] Процедура нормализации
- Функциональные зависимости
- Нормализация отношений Нормализация — формальная процедура разбиения некоторой реляционной таблицы на две или более с целью получения такого проекта БД, в котором исключено избыточное дублирование информации. Это делается не столько с целью экономии памяти, сколько для исключения возможной противоречивости хранимых данных, возникающих в результате аномалий обновления, удаления и вставки, и создания структуры, в которой предусмотрена возможность ее будущих изменений и влияние этих изменений на приложения, использующие информацию этой БД, минимально.
- Многозначная зависимость В отношении R атpибут Y многозначно зависит от X, если каждому значению X соответствует несколько значений Y.
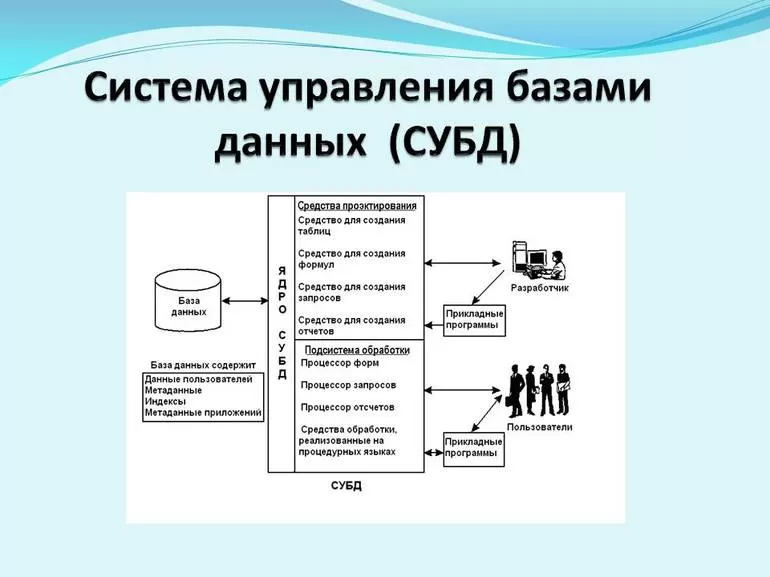
СУБД
Общая структура реляционной базы данных
Коннолли и Бегг определяют систему управления базой данных (СУБД) как «систему программного обеспечения, которая позволяет пользователям определять, создавать, поддерживать и контролировать доступ к базе данных». СУБД — это расширение этого акронима, которое иногда используется, когда базовая база данных является реляционной.
Альтернативным определением системы управления реляционными базами данных является система управления базами данных (СУБД), основанная на реляционной модели . Большинство широко используемых сегодня баз данных основано на этой модели.
РСУБД были распространенным вариантом для хранения информации в базах данных, используемых для финансовых отчетов, производственной и логистической информации, данных о персонале и других приложений с 1980-х годов. Реляционные базы данных часто заменяли устаревшие иерархические базы данных и сетевые базы данных , потому что СУБД было проще внедрять и администрировать. Тем не менее, реляционные хранимые данные получали постоянные безуспешные попытки систем управления объектными базами данных в 1980-х и 1990-х годах (которые были введены в попытке устранить так называемое несоответствие объектно-реляционного импеданса между реляционными базами данных и объектно-ориентированными прикладными программами). а также системами управления базами данных XML в 1990-х годах. Однако, в связи с просторов технологий, таких как горизонтальное масштабирование от компьютерных кластеров , NoSQL баз данных в последнее время стали популярными в качестве альтернативы к базам данных СУБД.
Хранилище пар «ключ — значение»
Хранилище пар «ключ — значение» по сути представляет собой большую хэш-таблицу. Каждое значение сопоставляется с уникальным ключом, и хранилище ключей использует этот ключ для хранения данных, применяя к нему некоторую функцию хэширования. Выбор функции хэширования должен обеспечить равномерное распределение хэшированных ключей по хранилищу данных.
Большинство хранилищ пар «ключ — значение» поддерживают только самые простые операции запроса, вставки и удаления. Чтобы частично или полностью изменить значение, приложение всегда перезаписывает существующее значение целиком. В большинстве реализаций атомарной операцией считается чтение или запись одного значения. Запись больших значений занимает относительно долгое время.
Приложение может хранить в наборе значений произвольные данные, но некоторые хранилища пар «ключ — значение» накладывают ограничения на максимальный размер значений. Программное обеспечение хранилища ничего не знает о значениях, которые в нем хранятся. Все сведения о схеме поддерживаются и применяются на уровне приложения. Эти значения по существу являются большими двоичными объектами, которые хранилище извлекает и сохраняет по соответствующему ключу.
Хранилища пар «ключ — значение» рассчитаны на приложения, выполняющие простые операции поиска на основе значения ключа или диапазона ключей, но не очень подходят для систем, которым нужно запрашивать данные из нескольких таблиц хранилищ пар «ключ — значение», например присоединенные данные в нескольких таблицах.
Кроме того, хранилища пар «ключ — значение» неудобны в сценариях, где могут выполняться запросы или фильтрация по значению, а не только по ключам. Например, с помощью реляционной базы данных можно найти запись, используя предложение WHERE для фильтрации неключевых столбцов, но в хранилищах «ключ-значение» обычно отсутствует возможность поиска в значениях, или, если они есть, требуется медленный Просмотр всех значений.
Одно хранилище пар «ключ — значение» очень легко масштабируется, поскольку позволяет удобно распределить данные среди нескольких узлов на разных компьютерах.
Соответствующие службы Azure:
- API таблиц Azure Cosmos DB
- Кэш Azure для Redis
- хранилище таблиц Azure
Структура реляционной модели данных
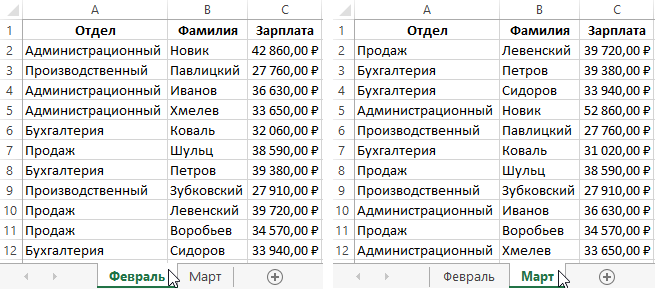
При табличной организации данных отсутствует иерархия элементов. Строки и столбцы могут быть просмотрены в любом порядке, поэтому высока гибкость выбора любого подмножества элементов в строках и столбцах. Любая таблица в реляционной базе состоит из строк, которые называют записями, и столбцов, которые называют полями. На пересечении строк и столбцов находятся конкретные значения данных. Для каждого поля определяется множество его значений.
В реляционной модели данных применяются разделы реляционной алгебры, откуда и была заимствованна соответствующая терминология.В реляционной алгебре поименованный столбец отношения называется атрибутом, а множество всех возможных значений конкретного атрибута – доменом. Строки таблицы со значениями разных атрибутов называют кортежами. Атрибут, значение которого однозначно идентифицирует кортежи, называется ключевым (или просто ключом). Так ключевое поле – это такое поле, значения которого в данной таблице не повторяется. В отличие от иерархической и сетевой моделей данных в реляционной отсутствует понятие группового отношения. Для отражения ассоциаций между кортежами разных отношений используется дублирование их ключей. Сложный ключ выбирается в тех случаях, когда ни одно поле таблицы однозначно не определяет запись.
Записи в таблице хранятся упорядоченными по ключу. Ключ может быть простым, состоящим из одного поля, и сложным, состоящим из нескольких полей. Сложный ключ выбирается в тех случаях, когда ни одно поле таблицы однозначно не определяет запись.
Кроме первичного ключа в таблице могут быть вторичные ключи, называемые еще внешними ключами, или индексами. Индекс – это поле или совокупность полей, чьи значения имеются в нескольких таблицах и которое является первичным ключом в одной из них. Значения индекса могут повторяться в некоторой таблице. Индекс обеспечивает логическую последовательность записей в таблице, а также прямой доступ к записи.
По первичному ключу всегда отыскивается только одна строка, а по вторичному – может отыскиваться группа строк с одинаковыми значениями первичного ключа. Ключи нужны для однозначной идентификации и упорядочения записей таблицы, а индексы для упорядочения и ускорения поиска.
Индексы можно создавать и удалять, оставляя неизменным содержание записей реляционной таблицы. Количество индексов, имена индексов, соответствие индексов полям таблицы определяется при создании схемы таблицы.
Индексы позволяют эффективно реализовать поиск и обработку данных, формирую дополнительные индексные файлы. При корректировке данных автоматически упорядочиваются индексы, изменяется местоположение каждого индекса согласно принятому условию (возрастанию или убыванию значений). Сами же записи реляционной таблицы не перемещаются при удалении или включении новых экземпляров записей, изменении значений их ключевых полей.
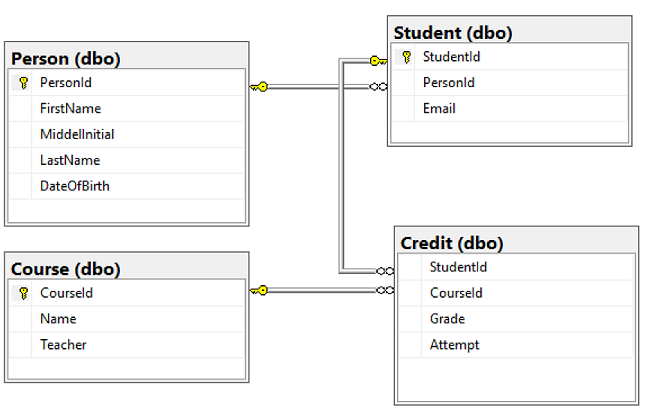
С помощью индексов и ключей устанавливаются связи между таблицами. Связь устанавливается путем присвоения значений внешнего ключа одной таблицы значениям первичного ключа другой. Группа связанных таблиц называется схемой данных. Информация о таблицах, их полях, ключах и т.п. называется метаданными.
Связывание таблиц
Для любой таблицы реляционной БД задаётся первичный ключ (primary key) — поле или сочетание полей, которые определяют каждую запись. Внешний или вторичный ключ (foreign key) — это одно или несколько полей, ссылающихся на поле primary key другой таблицы.

Составной ключ называется так, потому что создаётся из нескольких полей. При образовании составных ключей не рекомендуется включать в них поля, значения которых точно определяют запись. Например, не следует образовывать ключ, в котором находятся вместе поля «номер паспорта» и «шифр клиента», потому что оба эти атрибута однозначно определяют запись. Поля с повторяющимися в таблице значениями тоже нельзя делать составной частью ключа. По значению ключа возможно найти только одну запись.
Ячейка — это наименьший структурный элемент, который задаёт определённое значение соответствующего поля. Таблицы связываются друг с другом, и поэтому данные могут выбираться сразу из нескольких таблиц. Связь создаётся, если в них присутствуют одинаковые поля. Типы связей:
- один к одному;
- один ко многим;
- многие ко многим.
Связи «один к одному» встречаются довольно редко. «Один ко многим» применяются чаще, например, кассир продаёт много билетов. «Многие ко многим» тоже встречаются часто. Например, студент изучает много предметов. Связи «многие ко многим» нельзя организовывать непосредственно. Для установления отношения необходимо сопоставить каждому primary key внешний ключ, который представляет собой primary key другой таблицы. Реляционные системы базируются на теории реляционной модели, которая включает в себя три аспекта:
- структурный — данные в базе рассматриваются как набор отношений, то есть упорядоченных пар, составленных из заголовка и полей;
- целостности — состоит в проверке правильности согласования данных при обновлении;
- обработки — использование операторов манипулирования таблицами, таких как реляционная алгебра и реляционное исчисление, которые генерируют новые таблицы на основании уже имеющихся.
Под их руководством:
- производится добавление, определение, удаление и поиск записей;
- изменяются значения полей.
Для проведения этих операций организуются запросы. Итогом выполнения запросов будут либо изменения в таблицах, либо получение таблицы данных. При этом поддерживается принцип безопасности информации. Для реляционной БД основным языком управления является SQL.
Что такое нереляционная база данных
Реляционная база данных не эффективна для хранения большого количества данных, таких как BigData. Нереляционная база данных является решением этой проблемы. Кроме того, нереляционная база данных также называется NoSQL, Эти базы данных могут хранить большие данные. Также возможно кластеризовать данные на несколько машин, чтобы снизить затраты на обслуживание.

Существуют различные типы нереляционных баз данных.
Базы документов — Хранить динамические данные. Они хранят данные в формате JavaScript Object Notation (JSON). Например. CouchDB, Монго
Базы данных столбцов — Чтение и запись данных столбца мудро. Это полезно в аналитике данных. Например. Апач Кассандра.
Значение ключа хранимых баз данных — Быстро и не очень настраиваемый. Например. Couchbase Server, Redis.
Кэш базы данных — Храните данные на диске или в кеше. Например. Memcache
Граф базы данных — состоят из узлов. Отношения создаются с использованием ребер. Например. Oracle NoSQL, Neo4J.
Ключи в БД
Первичный ключ (РК, primary key) — столбец, значения которого различны во всех строках. РК бывают логические (естественные) и суррогатные (искусственные).
Суррогатный ключ — это дополнительное поле в БД. Обычно это уникальный id (порядковый номер записи), хотя принцип может быть и другой, главное — уникальность.
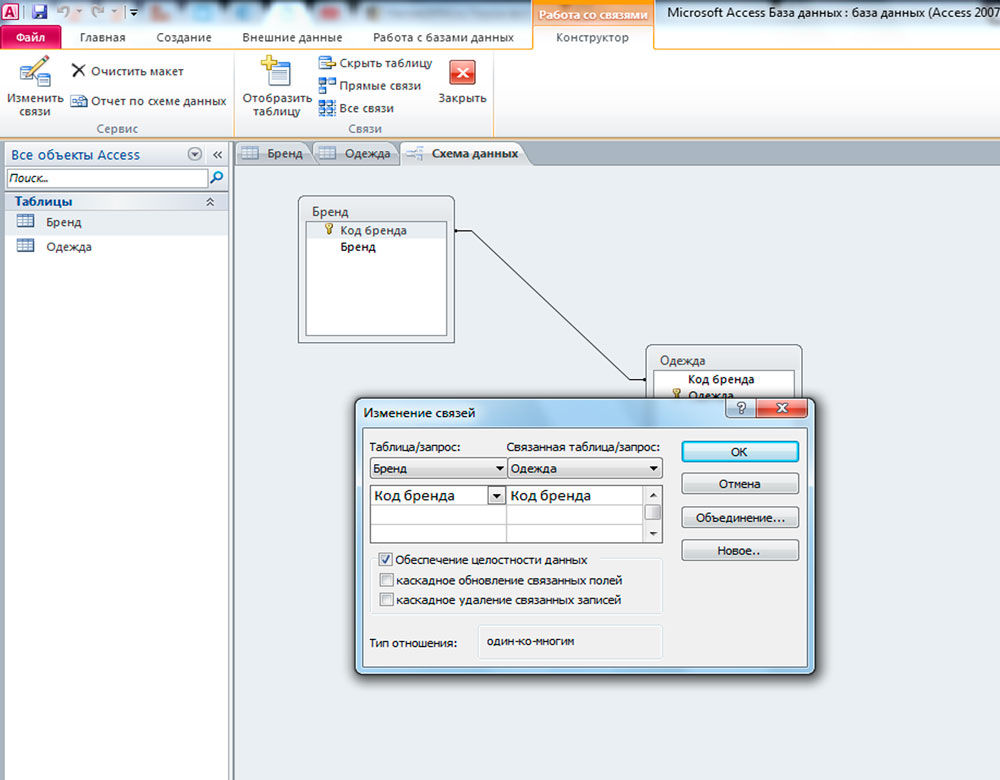
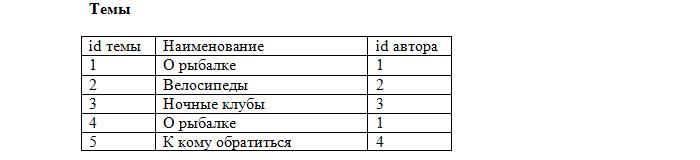
Вносим первичные ключи в наши таблицы:

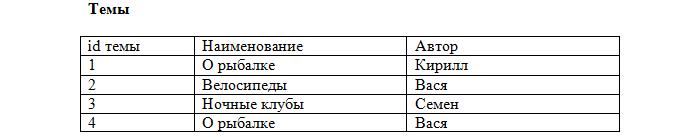
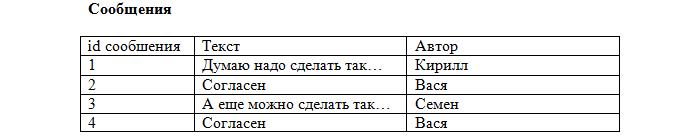
Заметьте, что каждая запись в таблице уникальна. Осталось лишь установить соответствие между сообщениями и темами, используя первичные ключи. Добавляем в таблицу с сообщениями ещё одно поле:
Теперь становится ясно, что сообщение id=2 относится к теме «О рыбалке» (id=4), которая создана Васей, а остальные принадлежат теме «О рыбалке», созданной Кириллом (id=1). Такое поле будет называться внешний ключ (FK, foreign key). При этом каждое значение данного поля сопоставляется с каким-либо первичным ключом из таблицы «Темы». В результате устанавливается однозначное соответствие между темами и сообщениями.
Ещё момент: допустим, добавляется новый пользователь по имени Вася.

Как узнать, какой же из «Васей» оставил сообщение? Для этого поля «Автор» в наших таблицах «Сообщения» и «Темы» мы тоже сделаем внешними ключами:

Итак, наша база данных фактически готова. Схематично она выглядит так:
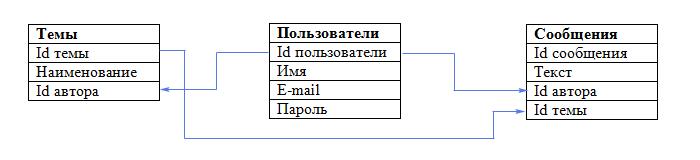
В этой небольшой базе данных лишь 3 таблицы. А что делать, если их 10 либо 200? Ясно, что всё не так просто. Именно поэтому любое проектирование реляционных баз данных начинается с разработки концептуальной модели данных.
Таблица как важная часть реляционной БД
Всем известно, что реляционная база данных состоит из таблиц. При этом каждая таблица включает в себя столбцы (поля либо атрибуты) и строки (записи либо кортежи).
Таблицы в таких БД обладают следующими свойствами:
— столбцы размещаются в определённом порядке, формируемом при создании таблицы. Таблица может не иметь ни одной строки, однако хотя бы один столбец должен быть обязательно;
— в таблице не может быть 2-х одинаковых строк. Если вспомнить математику, то такие таблицы называют отношениями (relation). Именно поэтому данные БД и считаются реляционными;
— каждый столбец в пределах таблицы имеет уникальное имя, а все значения в одном столбце должны быть одного типа (дата, текст, число и т. п.);
— на пересечении строки и столбца может быть только атомарное значение (значение, не состоящее из группы значений). Таблицы, которые удовлетворяют этим условиям, считаются нормализованными.
Реляционная модель данных: кем, когда и для чего создана
Реляционная модель данных — созданная Эдгаром Коддом логическая модель данных, описывающая:
- структуры данных в виде (изменяющихся во времени) наборов отношений;
- теоретико-множественные операции над данными: объединение, пересечение разность и декартово произведение;
- специальные реляционные операции: селекция, проекция, соединение и деление;
- специальные правила, обеспечивающие целостность данных.
Эдгар Франк «Тед» Кодд — (23 августа 1923 —18 апреля 2003) — британский учёный, работы которого заложили основы
теории реляционных баз данных. Работая в компании IBM, он создал реляционную модель данных. В 1970 издал работу «A Relational Model
of Data for Large Shared Data Banks», которая считается первой работой по реляционной модели данных.
Реляционная модель данных — это способ рассмотрения данных, то есть предписание для способа представления данных
(посредством таблиц) и для способа работы с таким представлением (посредством операторов). Она связана с тремя аспектами
данных: структурой (объекты), целостностью и обработкой данных (операторы).
В 2002 журнал Forbes поместил реляционную модель данных в список важнейших инноваций
последних 85 лет.
Цели создания реляционной модели данных:
- обеспечение более высокой степени независимости от данных;
- создание прочного фундамента для решения семантических вопросов и проблем непротиворечивости и избыточности данных;
- засширение языков управления данными за счёт включения операций над множествами.
Проблемы модели
Преимущество реляционных хранилищ состоит в том, что они способны обеспечить наилучшее соотношение устойчивости, производительности, гибкости, совместимости и масштабируемости. Реляционные БД предоставляют лёгкий доступ к составляемым отчётам и обеспечивают высокую надёжность и целостность информации из-за отсутствия избыточных данных. Но сейчас, когда всё большее количество приложений работает с высокой нагрузкой, увеличивается значение фактора масштабируемости.
Реляционные БД легко масштабируются, только когда они расположены на одном сервере. Если потребуется увеличить количество серверов и разделить нагрузку между ними, то возрастёт сложность хранилищ, что значительно снизит возможность использовать их как платформу для мощных распределённых систем. Поэтому приходится применять другие типы БД, которые обладают лучшей масштабируемостью и отказываться от возможностей, предоставляемых реляционными хранилищами.
Реляционная БД — это совокупность связей, которые способны структурировать данные, что даёт возможность рационального хранения и эффективного использования информационных материалов.
Доля рынка
По данным DB-Engines , в марте 2021 года наиболее широко используемыми системами были:
- Oracle
- MySQL
- Microsoft SQL Server
- PostgreSQL (бесплатное программное обеспечение)
- IBM Db2
- SQLite (бесплатное программное обеспечение)
- Microsoft Access
- MariaDB (бесплатное программное обеспечение)
- Hive (бесплатное программное обеспечение; специализировано для хранилищ данных ).
- Терадата
- База данных Microsoft Azure SQL
По данным исследовательской компании Gartner , в 2011 году в пятерку ведущих производителей реляционных баз данных собственного ПО по объему выручки входили Oracle (48,8%), IBM (20,2%), Microsoft (17,0%), SAP, включая Sybase (4,6%) и Teradata (3,7 %). %).
Применение
Обычные SQL-базы отлично подходят для типовых задач, где надёжность и предсказуемость важнее скорости. Например, для записей о пациентах, перемещениях товаров со склада или школьных оценок.
Но если вам нужна скорость, масштаб и большая мощность — посмотрите на NoSQL. Единственный минус — у каждой базы свои правила работы с данными, поэтому быстро перейти от одной к другой не получится.
Текст и иллюстрации:Миша Полянин
Редактор:Максим Ильяхов
Корректор:Ира Михеева
Иллюстратор:Даня Берковский
Вёрстка:Маша Дронова
Доставка:Олег Вешкурцев
Операция проекции
Операция проекции () работает, как и операция выборки, только с одним отношением
и определяет
новое отношение , в котором есть лишь те атрибуты (столбцы),
которые заданы в операции, и их значения.
Запрос SQL
SELECT DISTINCT A4, A3 from R3
Пусть вновь дано то же отношение :
| R3 | |||
| A1 | A2 | A3 | A4 |
| 3 | hh | yl | ms |
| 4 | pp | a1 | sr |
| 1 | rr | yl | ms |
Из исходного отношения выбираем только столбцы А4 и А3 и видим, что строки
со значениями — первая и третья — идентичны. Исключаем дубликат (за это отвечает ключевое
слово DISTINCT в SQL-запросе, которое говорит, что нужно выбрать только уникальные записи)
и получаем следующее новое отношение, в котором два атрибута и две строки (записи):
| R | |
| A4 | A3 |
| ms | yl |
| sr | a1 |
Хранилища данных графов
Хранилища данных графов управляют сведениями двух типов: узлами и ребрами. Узлы в этом случае представляют сущности, а ребра определяют связи между ними. Узлы и грани имеют свойства, которые предоставляют сведения о конкретном узле или грани, примерно как столбцы в реляционной таблице. Грани могут иметь направление, указывающее на характер связи.
Хранилища данных графов позволяют приложениям эффективно выполнять запросы, которые проходят через сеть узлов и ребер, а также анализировать связи между сущностями. На схеме ниже представлены данные персонала организации, структурированные в виде графа. Сущностями здесь являются сотрудники и отделы, а грани определяют отношения подчинения и отдел, в котором работает каждый сотрудник. Стрелки на ребрах этого графа показывают направление связей.
Такая структура позволяет легко выполнять такие запросы, как «найти всех сотрудников, которые прямо или косвенно подчиняются Светлане» или «найти всех, кто работает в одном отделе с Дмитрием». Для больших диаграмм с большим количеством сущностей и связей можно быстро выполнять сложный анализ. Многие базы данных графов предоставляют язык запросов, который можно использовать для эффективного обхода сети связей.
Соответствующие службы Azure:
API Graph в Azure Cosmos DB
Хранилища данных временных рядов
Данными временных рядов называются наборы значений, которые упорядочены по времени. Соответственно хранилища данных временных рядов оптимизированы для хранения данных именно такого типа. Хранилища данных временных рядов должны поддерживать очень большое число операций записи, так как обычно в них в режиме реального времени собирается большой объем данных из большого количества источников. Эти хранилища также хорошо подходят для хранения данных телеметрии. Например, для сбора данных от датчиков Интернета вещей или счетчиков в приложениях или системах. Обновления в таких базах данных выполняются редко, а удаление чаще всего является массовой операцией.
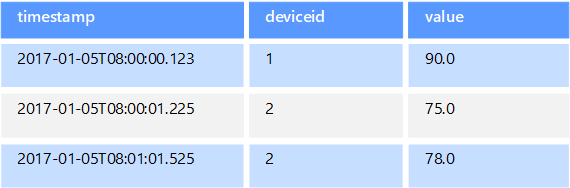
Размер отдельных записей в базе данных временных рядов обычно невелик, но их очень много, а значит общий размер данных быстро увеличивается. Хранилища данных временных рядов также обрабатывают данные, полученные вне очереди или несвоевременно, автоматически индексируют точки данных и оптимизируют запросы, полученные в течение определенного промежутка времени. Эта последняя возможность позволяет быстро выполнять запросы к миллионам точек данных и нескольким потокам данных, что, в свою очередь, обеспечивает поддержку визуализации временных рядов (стандартный способ потребления данных временных рядов).
Дополнительные сведения см. в статье Решения для временных рядов.
Соответствующие службы Azure:
- Аналитика временных рядов Azure
- OpenTSDB с HBase в HDInsight
Хранилища данных документов
Хранилище данных документов управляет набором значений именованных строковых полей и данных объекта в сущности, которая называется документом. Обычно данные в этих хранилищах содержатся в виде документов JSON. Каждое значение поля может представлять собой скалярный элемент, например число, или сложный объект, например список или коллекция типа «родитель — потомок». Данные в полях документа можно закодировать разными способами, например в формате XML, YAML, JSON, BSON, или хранить в виде обычного текста. Поля документов доступны системе управления хранилищем, что позволяет приложению выполнять запросы и применять фильтры, основанные на значениях этих полей.
Как правило, документ содержит все данные для сущности. Элементы, составляющие сущность, зависят от конкретного приложения. Например, сущность может содержать сведения о клиенте, заказе или их сочетание. Один документ может содержать сведения, которые в реляционной СУБД обычно распределяются по нескольким реляционным таблицам. Хранилище документов не требует, чтобы все документы имели одинаковую структуру. Такой свободный подход к форме обеспечивает большую гибкость. Например, приложения могут хранить в документах разные данные в соответствии с текущими требованиями компании.
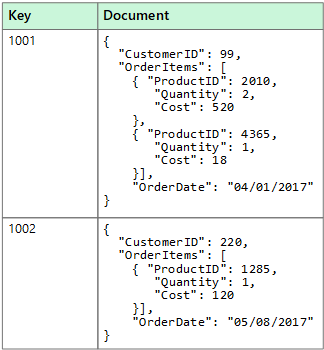
Приложение может получать документы по ключу документа. Это уникальный идентификатор документа. Часто к нему применяется хэширование для равномерного распределения данных. Некоторые базы данных документов автоматически создают ключ документа. Другие позволяют указать атрибут документа, который будет использоваться в качестве ключа. Приложение также может запрашивать документы на основе значения одного или нескольких полей. Некоторые базы данных документов поддерживают индексирование, чтобы облегчить быстрый поиск документов по одному или нескольким индексированным полям.
Многие базы данных документов поддерживают обновления «на месте», то есть позволяют приложению изменять значения отдельных полей без перезаписи всего документа. Операции чтения и записи для нескольких полей в одном документе обычно являются атомарными.
Соответствующие службы Azure:
Azure Cosmos DB
SQL и NoSQL
abДва варианта представления данных
уплотнения
Масштабируемость
Тип хранилища данных
Сценарий использования
Пример
Рекомендации
Хранилище типа ключ-значение
Подходит для простых приложений, с одним типом объектов, в ситуациях, когда поиск объектов выполняют лишь по одному атрибуту.
Интерактивное обновление домашней страницы пользователя в Facebook.
Рекомендовано знакомство с технологией memcached.
Если приходится искать объекты по нескольким атрибутам, рассмотрите вариант перехода к хранилищу, ориентированному на документы.
Хранилище, ориентированное на документы
Подходит для хранения объектов различных типов.
Транспортное приложение, оперирующее данными о водителях и автомобилях, работая с которым надо искать объекты по разным полям, например — имя или дата рождения водителя, номер прав, транспортное средство, которым он владеет.
Подходит для приложений, в ходе работы с которыми допускается реализация принципа «согласованность в конечном счёте» с ограниченными атомарностью и изоляцией. Рекомендуется применять механизм кворумного чтения для обеспечения своевременной атомарной непротиворечивости.
Система хранения данных с расширяемыми записями
Более высокая пропускная способность и лучшие возможности параллельной обработки данных ценой слегка более высокой сложности, нежели у хранилищ, ориентированных на документы.
Приложения, похожие на eBay
Вертикальное и горизонтальное разделение данных для хранения информации клиентов.
Для упрощения разделения данных используются HBase или Hypertable.
Масштабируемая RDBMS
Использование семантики ACID освобождает программистов от необходимости работать на достаточно низком уровне, а именно, отвечать за блокировки и непротиворечивость данных, обрабатывать устаревшие данные, коллизии.
Приложения, которым не требуются обновления или слияния данных, охватывающие множество узлов.
Стоит обратить внимание на такие системы, как MySQL Cluster, VoltDB, Clustrix, ориентированные на улучшенное масштабирование.
этом
Графы
Если ваши данные можно представить в виде графа или дерева, то вам подойдёт и база данных с таким же подходом к хранению и поиску.
Дерево — это когда данные хранятся по системе «родитель — отпрыски». Есть некий родительский кусок данных, у него есть связанные с ним отпрыски. У тех тоже могут быть свои отпрыски и так далее. Каждая единица данных может быть чьим-то отпрыском (но только кого-то одного) и иметь сколько-то собственных отпрысков.
В деревьях удобно хранить данные, например, для поисковых алгоритмов. В «деревьях» также хранятся файлы на вашем компьютере: есть корневой каталог, в нём вложенные папки, в них ещё папки, в них файлы. Один и тот же файл не может храниться одновременно в двух местах.
Графы — это когда данные связаны вообще как хочешь. Один кусок данных может быть связан с любыми другими в любом количестве и в любом направлении. Дерево — частный случай графа.

Подводим итоги проектирования
Проектирование БД — процесс небыстрый и достаточно трудоёмкий. Во время проектирования надо хорошо знать предметную область, учитывать все нюансы. Вся информация должна отображаться в виде таких элементов, как объекты, атрибуты, связи, причём проектирование успешно лишь тогда, когда всё сделано максимально рационально.
Вообще, взгляды на проектирование среди разработчиков могут различаться. Некоторые игнорируют теорию, руководствуясь лишь опытом и здравым смыслом. Другие во время проектирования отводят главную роль интуиции, считая проектирование искусством, которым владеют далеко не все. Как бы там ни было, знания никогда не бывают лишними.
Да, реляционная база данных — это не более чем хранилище, где хранятся данные. Однако от того, как грамотно вы его организуете, будет зависеть стабильность работы всего приложения, где используются эти самые данные.
В заключение, добавим, что умение проектировать базы вам никогда не помешает. А научиться всему этому вы сможете на нашем курсе «Реляционные СУБД». Ждём вас!