Сервисы и программы распознавания текста с фото и картинок (онлайн, бесплатно)
Содержание:
- 10 лучших бесплатных программ для распознавания текста
- Текст извлечен с помощью OCR – что это значит?
- Возможности ABBYY FineReader
- Обходные пути
- Как перенести текст с фото в Word онлайн: 5 сервисов
- Сервисы бесплатного распознавания текста с фото онлайн
- Преимущества и недостатки
- Советы по распознаванию рукописного текста
- Преобразование графического файла
- Mobile OCR Free – распознание текста на Android
10 лучших бесплатных программ для распознавания текста
1. PDFelement
PDFelement обеспечивает удобную работу с отсканированными PDF-документами благодаря передовой технологии оптического распознавания символов. Эта функция позволяет распознавать текст отсканированных PDF-файлов, чтобы сделать текст и файл редактируемыми. Кроме того, с его помощью вы можете конвертировать ваши отсканированные PDF-файлы в другие редактируемые форматы, включая Excel, Word, PPT, Text и другие. Качество вашего оригинального документа будет полностью сохранено.
PDFelement оснащен мощными инструментами редактирования, которые позволяют вставлять, удалять или изменять текст, изображения и страницы. Вы также можете заполнять интерактивные и неинтерактивные формы и создавать новые формы с различными вариантами их заполнения.
Руководство:Как Скопировать Текст из Изображения
2. FreeOCR
Полностью бесплатный онлайн-инструмент для распознавания текста, который не требует регистрации или указания адреса электронной почты. Работает с различными файлами изображений, включая GIF, JPG, BMP, TIFF или PDF с многостолбцовым текстом. Распознает более 30 различных языков. Размер загрузки ограничен до 2 МБ или 5000 пикселей, можно загружать не более 10 изображений в час.
4. Online OCR
Online OCR позволяет конвертировать фотографии и цифровые изображения в текст. Распознает тексты на 32 языках и конвертирует отсканированные PDF-файлы в Word, RTF и текстовые форматы. С помощью данной программы можно также извлекать текст из изображений в форматах JPG, JPEG, BMP, TIFF и GIF и преобразовывать его в редактируемые документы Word, TXT, PDF, Excel или HTML. Конвертирование до 15 изображений в час.
5. Free Online OCR
Free Online OCR позволяет конвертировать скриншоты, отсканированные документы, факсы и фотографии в форматы текст с возможностью поиска и редактирования, например, TXT, DOC, RTF и PDF. Программа поддерживает такие форматы, как BMP, PDF, PNG, TIFF, JPG(JPEG), и GIF.
6. Cvisiontech
Cvisiontech также поддерживает одновременную загрузку нескольких файлов TIFF, PDF, BMP и JPG. Перед загрузкой необходимо убедиться, что размер любого из загруженных файлов менее 100 МБ. Программа позволяет сжимать файлы и оптимизировать их для веб-сайта.
7. SuperGeek Free Document OCR
SuperGeek Free Document OCR – удобная и мощная программа для конверирования изображений и распознавания текста (OCR), подходящая как для профессионального, так и для домашнего использования. Позволяет читать текст из JPG, JPEG, TIF, TIFF, PNG, BMP, PSD, GIF, EMF, WMF, J2K, DCX, PCX, JP2 и т.д. и конвертировать файлы данных типов в редактируемые документы MSWord и TXT всего за несколько кликов.
8. onOCR
Программа onOCR справляется с различными отсканированными PDF или файлами изображений независимо от их размера. Free OCR помогает преобразовывать нередактируемые документы в тексты с возможностью копирования и редактирования. Вы можете обрабатывать как крупные, так и мелкие изображения и преобразовывать их в редактируемый текст.
9. Investintech
Able2Extract от Investintech – это инструмент для работы PDF с возможностью конвертирования отсканированных PDF в один из более чем 10 различных типов редактируемых файлов. С его помощью вы можете преобразовывать файлы практически любого типа в защищенные PDF, просматривать и редактировать PDF и преобразованные файлы, а также извлекать текст из отсканированных документов.
10. OCRgeek
OCRGeek.com позволяет вам выполнять распознавать тексты онлайн в пакетном режиме. Вы можете без проблем загружать по несколько файлов одновременно. Процесс распознавания происходит быстро и просто. Загруженные вами документы будут организованы и одновременно преобразованы в формат TXT. Форматы ввода, которые поддерживает OCRgeek: JPG, PNG, TIFF, PDF, DJVU, GIF и BMP.
Текст извлечен с помощью OCR – что это значит?
Нередко студенты сталкиваются с фразой, представленной в полных отчетах системы Антиплагиат.ВУЗ, «Текст извлечен с помощью OCR». Это значит, что перед проверкой работы преподаватель подключил модуль OCR – поставил галочку напротив «Использовать распознавание текста (OCR)». С помощью этого модуля в файле будут подвергаться проверке только видимые элементы, а это значит, что искусственное завышение уникальности с помощью скрытых символов в 90% случаев не сработает. Поскольку для того, чтобы использовать распознавание текста при проверке документа его сначала нужно подключить, многие преподаватели просто забывают о такой возможности, однако если же этот модуль действительно включен, информация об этом обязательно отобразиться в полном отчете о проверке.
После того как мы разобрали принципы распознавания текста OCR и что это в антиплагиате, стоит подробней остановиться на способах повышения уровня оригинальности текста и на том, как можно обойти модуль OCR.
Возможности ABBYY FineReader
- Программа распознавания текста, предполагает работу со 179 языками;
- После обработки текста, имеется опция его сохранения, а также отправка по почте или публикация в интернет-сети;
- Встроенные инструменты, отвечающие за увеличение качества фото и изображений;
- Точность распознания пдф, сканов и изображений благодаря технологии Abbyy OCR;
- Утилита поддерживает Windows 7, а также Windows 8 и 10;
- Возможность конвертирования готового текста в форматы PDF, DOC, RTF, XLS и HTML;
- Сохраняется оформление, а также стиль документа с последующей возможностью запуска через Microsoft Word, Outlook и Excel;
- Программа поддерживает распознавание документов, полученных с МФУ, сканеров, цифровых фотоаппаратов и даже с мобильного телефона;
- Имеется русская версия реализации простого и понятного интерфейса;
- Зарегистрированным пользователям лицензионного Абби Файнридер предоставляются доступ к онлайн сервису Abbyy Finereader Online.
Преимущества
- Разработчик ABBYY, предоставляет периодические обновления своей утилиты сканирования, распознавания текста;
- Обработка документов, которые были сфотографированы на мобильное устройство;
- Одновременная работа с пакетом изображений или сканов;
- Наличие полезных дополнений, таких как ABBYY Screenshot Reader и прочие;
- Программное обеспечение автоматически распознает разные языки в одном документе;
- Высокие показатели точности оптического распознавания текстовой информации;
- Сохранение исходного высокого качества изображения документов;
- Поддерживается любая актуальная система Windows, отличные показатели работы с редакторами Microsoft Office;
- Программа распознавания текстовых данных, сохраняет контент в редактируемый формат;
- Имеется профессиональная модификация софта FineReader 12;
- Приложение качественно обрабатывает персональные бумажные документы.
Недостатки
Обходные пути
Существует несколько методов решения проблемы распознавания символов с помощью других средств, помимо улучшенных алгоритмов OCR.
Принудительный ввод лучше
Специальные шрифты, такие как шрифты OCR-A , OCR-B или MICR , с точно указанным размером, интервалом и характерной формой символов, обеспечивают более высокую точность при транскрипции при обработке банковских чеков. Однако по иронии судьбы несколько известных механизмов OCR были разработаны для захвата текста в популярных шрифтах, таких как Arial или Times New Roman, и неспособны захватывать текст в этих специализированных шрифтах, которые сильно отличаются от широко используемых шрифтов. Поскольку Google Tesseract можно обучить распознавать новые шрифты, он может распознавать шрифты OCR-A, OCR-B и MICR.
«Поля гребней» — это заранее напечатанные поля, которые побуждают людей писать более разборчиво — по одному глифу на поле. Они часто печатаются «выпадающим цветом», который может быть легко удален системой OCR.
В Palm OS использовался специальный набор глифов, известный как « Граффити », который похож на печатные английские символы, но упрощен или модифицирован для облегчения распознавания на аппаратном обеспечении платформы с ограниченными вычислительными возможностями. Пользователи должны научиться писать эти специальные символы.
Зональное распознавание текста ограничивает изображение определенной частью документа. Это часто называют «шаблоном OCR».
Краудсорсинг
Краудсорсинг людей для распознавания символов может быстро обрабатывать изображения, такие как компьютерное оптическое распознавание символов, но с более высокой точностью распознавания изображений, чем это достигается с помощью компьютеров. Практические системы включают Amazon Mechanical Turk и reCAPTCHA . Национальная библиотека Финляндии разработала веб — интерфейс для пользователей , чтобы исправить тексты OCRed в стандартизированном формате ALTO. Краудсорсинг также использовался не для непосредственного распознавания символов, а для приглашения разработчиков программного обеспечения к разработке алгоритмов обработки изображений, например, с помощью турниров по ранжированию .
Как перенести текст с фото в Word онлайн: 5 сервисов
Прибегают к ним, как правило, для переноса текста с фото в Word в небольших объемах, а также тогда, когда операция носит разовый характер. Подавляющее большинство таких сервисов являются условно-бесплатными, при этом в бесплатном режиме они ограничивают функционал — устанавливают лимиты на объем текста, количество языков, требуют обязательной регистрации и так далее.
Convertio
Хороший сервис для перевода текста с фото в Word, понимает несколько десятков языков, работает с PDF и популярными форматами растровых изображений, позволяет сканировать до 10 страниц в бесплатном режиме. Результат сканирования может быть сохранен в 9 форматов, включая Word.
- На странице сервиса нажмите «Выберите файлы» и укажите изображение на диске. Можно последовательно добавить еще 9 файлов;
- Укажите распознаваемый язык (по умолчанию русский) и формат сохранения;
- Нажмите «Распознать», а затем появившуюся чуть выше кнопку «Скачать».
- Не требует обязательной регистрации.
- Загрузка с Dropbox, Google Drive и по URL.
Плохо работает с изображениями с многоцветным фоном.
Img2txt
Бесплатный онлайн-сканер текста с фото для Word, поддерживает работу с растровыми изображениями и PDF-документами размером не более 8 Мб.
- Выберите файл нажатием одноименной кнопки;
- Укажите язык распознаваемого текста;
- Нажмите «Загрузить» и дождитесь результата;
- Прокрутите страницу немного вниз, нажмите «Скачать» и укажите формат Word.
- Совершенно бесплатен и не требует регистрации.
- Предпросмотр результатов конвертации текста с фото в Word.
- Может распознавать текст даже из картинок с цветным фоном, но не исключены и ошибки.
Размер фото не должен превышать 8 Мб.
Online OCR
Этот бесплатный сервис позиционируется как конвертер PDF в Word с оптическим распознаванием, но с таким же успехом он может быть использован как преобразователь текста с фото в Word в режиме онлайн. Без регистрации позволяет вытащить из фото текст в Word до 15 раз в час.
- Нажмите кнопку «Файл» и выберите на жестком диске фото;
- Укажите язык распознавания и выходной формат файла DOСX;
- Нажмите «Конвертировать», отредактируйте, если потребуется, текст в поле предпросмотра и скачайте выходной файл.
- Регистрироваться необязательно.
- Распознаёт текст с картинок с цветным фоном с выводом в область предпросмотра.
- Поддерживает распознавание текста с фото в Word в пакетном режиме.
- При извлечении текста из цветного фото текст иногда приходится копировать из области предпросмотра, так как при сохранении даже хорошо распознанного текста в Word в файл вставляется картинка-исходник.
- Разрешение картинки должно быть не менее 200 DPI, в противном случает текст будет содержать много ошибок.
Free Online OCR
Неказистый на вид, но достаточно неплохой англоязычный сервис, позволяющий распознать текст с фото в Word онлайн. В отличие от аналогичных ресурсов, Free Online OCR умеет автоматически определять язык текста на изображении, поддерживается добавление дополнительных локализаций на случай, если фото содержит текст двух языков. Из дополнительных возможностей стоит отметить поворот картинки на 180°, 90° вправо/влево, а также разделение многоколоночного текста на столбцы.
- Нажмите кнопку выбора файла, а когда его имя появится рядом с кнопкой, нажмите «Preview»;
- Убедитесь, что программа точно определила язык, если нужно, добавьте кликом по полю «Recognition language(s) (you can select multiple)» второй язык.
- Нажмите кнопку «OCR» для запуска процедуры распознавания.
- Проверьте корректность распознавания, в меню выберите Download → DOC.
- Прост и удобен.
- Наличие дополнительных опций.
- Имеется возможность выбрать конкретный участок изображения.
- Нет поддержки пакетного режима.
- Иногда игнорирует второй язык.
- Не поддерживает конвертирование в DOCX.
ABBYY FineReader Online
Наиболее известный и качественный сервис, позволяющий выполнить распознавание текста с фото в Word онлайн. Отличается функциональностью, поддержкой множества языков и девяти форматов, загрузкой файлов с облачных хранилищ, а также сохранением результатов в облачные хранилища.
- Зайдите на сервис с помощью учетной записи Facebook, Google или Microsoft;
- Нажатием одноименной кнопки загрузите изображения с текстом;
- Выберите язык документа и формат сохранения;
- Нажмите «Распознать»;
- Скачайте готовый файл на следующей странице.
- Отличное качество распознавания.
- Пакетный режим.
- Требуется обязательная регистрация.
- В бесплатном режиме можно обработать не более 12 документов.
- Текст в документах Word может нуждаться в дополнительном форматировании.
Сервисы бесплатного распознавания текста с фото онлайн
Хочу заменить, что качество, получаемое при считывании текста с картинки, зависит от следующих факторов:
- качества исходника;
- размера элементов и четкости символов на отсканированном материале;
- формата файла.
Вашему вниманию представляю подборку сервисов, позволяющих преобразовать картинку в текст онлайн. Большинство из них бесплатные, а об имеющихся ограничениях, я упомяну в отдельной таблице. Большинство сайтов на английском языке.
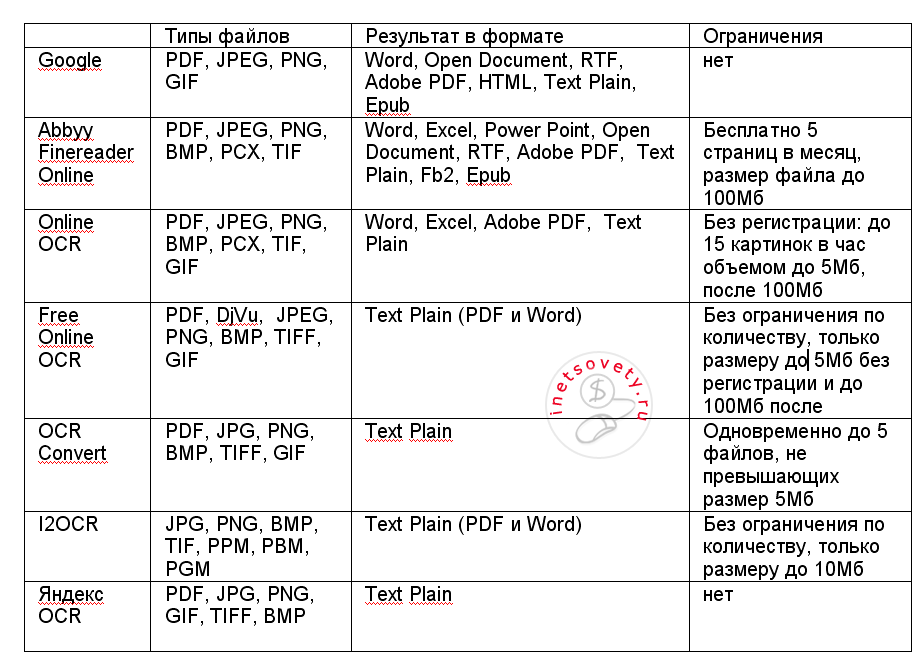
Сравнение онлайн распознавателей текста с фото или PDF смотрите в таблице ниже:
Сервис от Гугл
Чтобы перевести с текст с фото в ворд понадобится электронная почта gmail. С ее помощью вы получите доступ ко многим сервисам от Google. Ограничений по количеству файлов нет, как и по их объему.
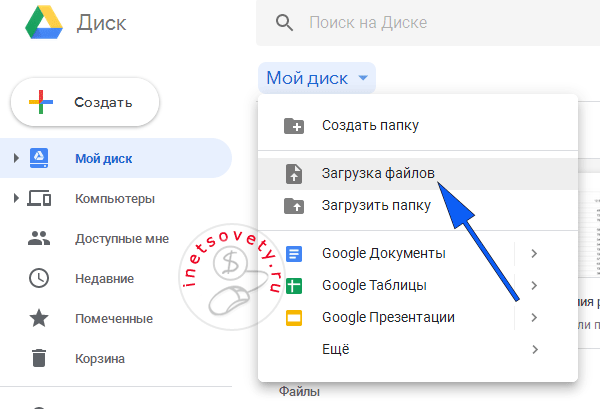
После этого кликаете по нему правой кнопкой и выбираете в меню открыть с помощью “Google Документы”:
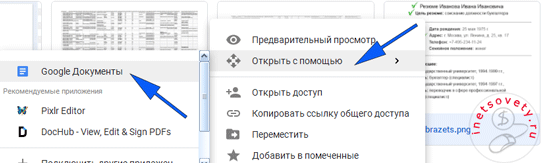
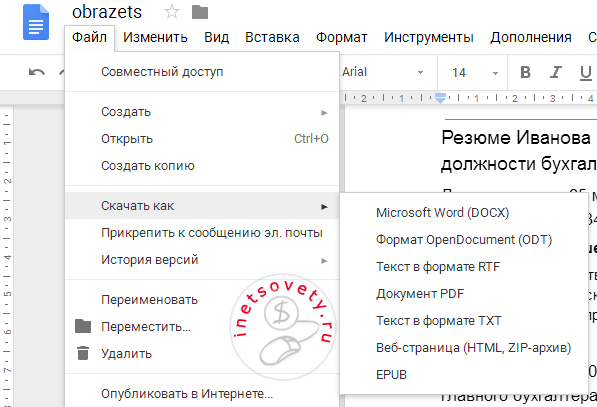
Результат перевода текста с картинки в ворд будет помещен в Google Документы и откроется на соседней вкладке. Далее вы можете его там редактировать или скопировать на компьютер в одном из форматов:
Abbyy Finereader Online
Это онлайн распознаватель текста с pdf или изображения в word, аналог одноименной программы для ПК. Файн ридер онлайн позволяет бесплатно распознать до 5 страниц в месяц и то только после регистрации. Плюс бонусом предоставляется 10 страниц после подтверждения имейла. Стоимость платного пакета услуг — 129 € / год на 5000 страниц.
Как использовать сервис показано на скрине — всего 5 шагов к получению текста с фото или pdf в ворд онлайн:
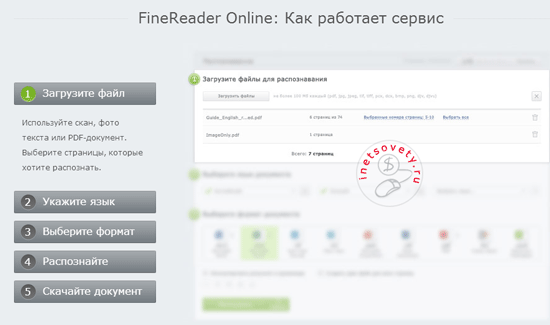
Ссылка для перехода finereaderonline.com
Online OCR
Отличный сервис распознавания текста с фото или из pdf с приемлемыми ограничениями в формате гостевого доступа, т.е. без регистрации на сайте. Позволяет произвести преобразование картинки в текст онлайн в количестве до 15 штук в час или 15 страниц в многостраничном PDF файле
Обратите внимание, что для работы с PDF документами понадобится регистрация
Ссылка на сам сервис OnlineOCR.net
Как вытащить текст из картинки в word этим сервисом смотрите ниже на скрине:
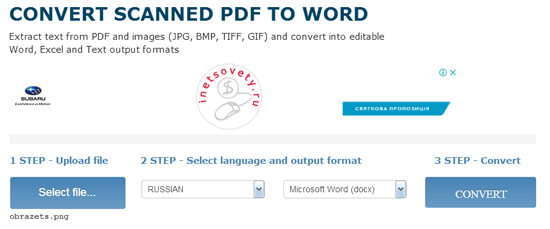
Отличительная особенность — в получаемых результатах изображения сохраняются с текстом. В других сервисах, что будут описаны ниже такого нет.
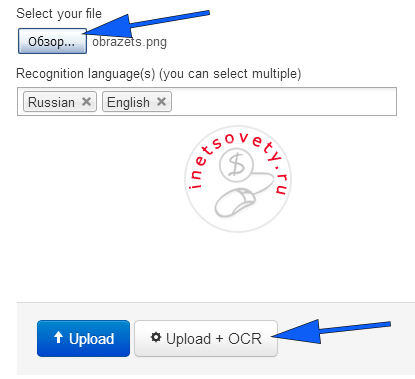
Free Online OCR
Довольно неплохой бесплатный и не имеющий ограничений по количеству файлов переводчик текста с картинки онлайн. Один его недостаток — сохранение результата без изображений с источника.
Для открытия сайта кликните newocr.com
Выбираем файл, ниже уже будет добавлено 2 языка, при необходимости добавьте другие. Кликните по кнопке «Upload & OCR»:
Изображение будет автоматически загружено и распознано. Результаты можно сохранить в документ или скопировать прямо из сайта:
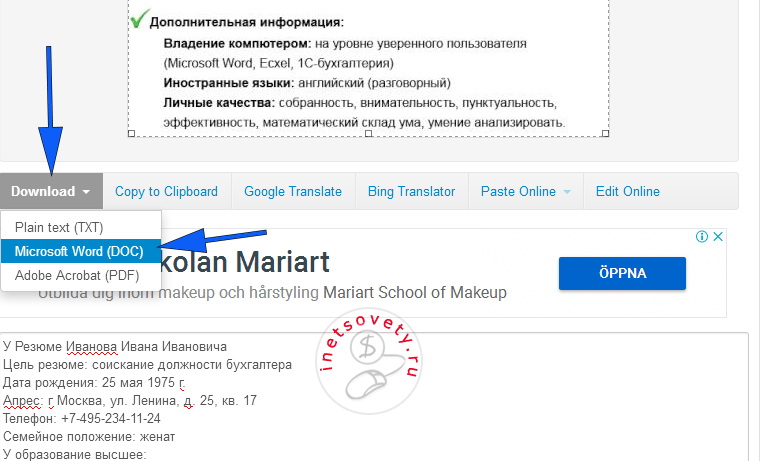
Есть возможность выделить участок на изображении для распознавания. А также несколько разных языков.
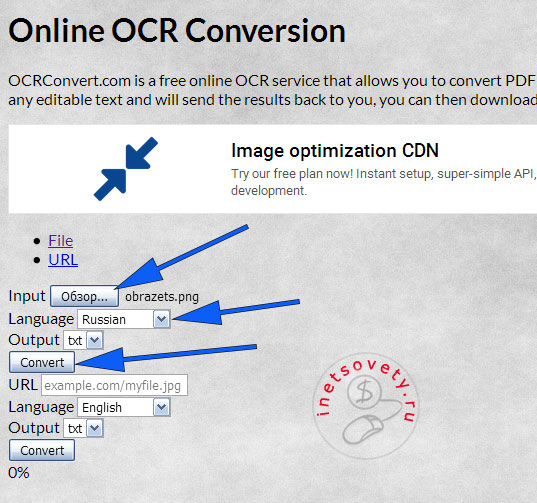
OCR Convert
Распознавание текста с картинки онлайн сервисом OCR Convert происходит не мгновенно! Вам предлагают оставить имейл, на который придет оповещении об удачном завершении распознавания. И скачать готовый файл можно в течении 24 часов, дальше он будет удален автоматически. Это главный минус данного сайта!
Работать просто, выберите файл, язык и кликните по кнопке «Convert»:
Soda PDF OCR
Многофункциональный сервис для работы с PDF документами. Полный список возможностей представлен на скрине ниже, но нас в первую очередь интересует распознавание текста из pdf в word онлайн.

Загрузите файл и получите расшифрованный документ.
I2OCR
Работать с сайтом просто, всего 4 действия, чтобы преобразовать фото в текст:
- Выбираем язык.
- Загружаем файл.
- Подтверждаем, что мы не робот.
- Кликаем по кнопке «Extract».
Ожидаем минутку и появляется возможность скопировать текст с картинки онлайн на свой компьютер в одном из форматов по кнопке «Download».
OCR от Яндекс
Его назначение — перевод текста из подгруженного изображения, но с задачей сканировать текст с фотографии онлайн он успешно справляется. Работает без регистрации и каких-либо ограничений.

Вот таким не хитрым способом, используя яндекс переводчик не по назначению нам удалось скопировать текст с картинки онлайн.
Преимущества и недостатки
Преимущества использования таких сервисов очевидны.
Основное из них – это существенная экономия времени на обработку материала.
И хотя текст, получаемый на выходе, может иметь даже очень низкое качество, редактирование его все равно займет, в большинстве случаев, меньше времени, нежели перепечатка «с нуля».
Какие же преимущества и недостатки имеют такие программы?
Позитив:
- Значительная экономия времени, уходящего на автоматическую перепечатку текста;
- Избежание ошибок в формулах и сложных символьных построениях, которые могут быть при ручной перепечатке материала (справедливо только в случае, если используется качественный софт, способный достоверно распознавать сложные символьные комбинации);
- Распознавание и перенесение текста, который вы не можете напечатать на своей клавиатуре (например, текст с арабской вязью, иероглифами и другими символами, которые отсутствуют на традиционной русско-английской клавиатуры).
- Хотя, строго говоря, преимуществ в использовании таких программ достаточно мало, они завоевывают все новых и новых поклонников, так как помогают экономить время (или создают иллюзию экономии, так как фактически на редактуру некачественно обработанного софтом текста уходит времени больше, чем на его изначальную перепечатку).
Негатив:
- Ограниченность базы языков – то есть, определенная программа рассчитана на распознавание определенных символов, и часто, это могут быть символы только какого-нибудь одного языка. В других программах в базу может быть занесено несколько алфавитов, но, обычно, такой софт ограничивается 1-3 языками;
- Большие сложности бывают при работе с текстом смещенного типа, то есть таким, который содержит как русские, так и английские символы. Вы можете выбрать только один язык текста и алфавит для распознавания, что ведет к тому, что все, напечатанное другим алфавитом распознаваться не будет. В зависимости от типа, сложности и качества софта эта проблема может быть выражена в большей или меньшей степени;
- Потеря форматирования либо неспособность распознать особенности изначального оформления текста – выходной файл часто представляет собой почти файл Блокнота по оформлению;
- Просто низкое качество распознавания, связанное с неверной настройкой или некачественной проработкой самого софта, когда буквы распознаются ошибочно;
- Ошибки распознавания, связанные с изначальным низким качеством фото. Не любой софт работает с фото плохого качества и тщательно его обрабатывает;
- Серьезные проблемы с распознаванием возникают в случаях, когда текст расположен блоками, распределенными по фото неравномерно или даже в две колонки – лучше всего этот софт распознает сплошной текст;
- Качество распознавания может падать по мере добавления все новых и новых фото за один сеанс;
- Иногда процесс обработки изображения может идти очень долго, так как его скорость падает по мере увеличения длительности нагрузки на программу;
- Стандартное для почти всех программ, очень низкое качество распознавания «сложных» алфавитов, например, иероглифов или арабской вязи. Ошибки, причем достаточно крупные, в этом случае неизбежны;
- Неверное распознавание символьных групп – ситуация, при которой две, расположенные рядом, буквы ошибочно распознаются программой как одна. Причем, при возникновении такой ошибки могут смешиваться символы различных алфавитов, и изначальное корректное сочетание иногда бывает сложно угадать. Встречается такая ошибка очень часто.
На самом деле, в настоящее время практически не существует таких программ, работающих действительно качественно. Тексту, полученному после обработки фото в таком редакторе, все равно нужна тщательная редактура. И такая редактура порой может занимать не меньше времени, чем изначальная перепечатка. Это не все недостатки такого подхода, но резюмируя, можно сказать, что наиболее серьезной проблемой считается низкое качество распознавания текста в целом. Так как именно из-за него приходится производить длительную вычитку и редактуру материала.

<Рис. 4 Методы>
Советы по распознаванию рукописного текста
Те, кто только начал использовать электронные технологи распознавания и форматирования текстов, часто совершают типичные ошибки. Из-за этого рукописные документы неправильно интерпретируются программами и у людей получаются плохие, некорректные презультаты. Для решения это проблемы нужно придерживаться следующих советов. Распознавая текст по технологии OCR нужно помнить о том, что не всегда программы будут считывать текст без ошибок. Иногда нужно провести повторное сканирование, также нужно проверить отсканированный текст на наличие ошибок.
Формат
Для лучшего распознавания текста следует узнать, какой формат та или иная программа лучше поддерживает. К примеру, иногда лучше предоставить программе PDF формат, чем изображение.
Сканирование текста с фотографии
Если нужно отсканировать текст с фотографии, то нужно добиться максимального качества изображения. Сфотографировать лист нужно так, чтобы текст не был размыт, лист был полностью виден. Еще лучшим решением окажется не фотографирование текста, а оцифровка сканером. Это улучшит качество распознавания ввода.
Почерк

Рукописные тексты можно считывать с помощью мобильных приложений
При распознавании текста на результат сильно влияет четкость почерка. Документы с большим количеством помарок, «грязным» и некрасивым почерком будут распознаваться хуже. Программы распознают почерк большинства людей, но здесь нужно сделать оговорку о том, что почерк разных людей будет распознаваться с разным результатом, т.к не каждый из них понимается программой хорошо. Программы для распознавания рукописных текстов могут понадобится каждому человеку. Существует немало приложений, которые обладают такой функцией, и человек, который впервые узнает о технологии OCR может растеряться. Чтобы этого не случилось нужно знать, какая программа будет лучше работать в конкретной ситуации.
Интересное видео о том как включить распознавание рукописного текста в Gmail. Гугл нам в помощь.
Преобразование графического файла
- Откройте страницу drive.google.com на компьютере.
- Нажмите на нужный файл правой кнопкой мыши.
- Выберите Открыть с помощью Google Документы.
- Графический файл будет преобразован в документ Google. При этом некоторые параметры форматирования могут не сохраниться.
- Тип, начертание (полужирный, курсив) и размер шрифта, а также переносы строк обычно сохраняются.
- Списки, таблицы, столбцы, обычные и концевые сноски, скорее всего, не сохранятся.
Поддерживаемые языки
- Ачехский
- Ачоли
- Адангме
- Африкаанс
- Акан
- Албанский
- Алгонкинский
- Амхарский
- Древнегреческий
- Арабский (современный стандартный)
- Арауканский/мапуче
- Армянский
- Ассамский
- Астурийский
- Атабаскский
- Аймара
- Азербайджанский
- Азербайджанский (дореформенная кириллица)
- Балийский
- Бамбара
- Банту
- Башкирский
- Баскский
- Батак
- Белорусский
- Бемба
- Бенгальский
- Бикольский
- Бислама
- Боснийский
- Бретонский
- Болгарский
- Бирманский
- Каталанский
- Себуанский
- Чеченский
- Чероки
- Китайский (мандаринский, Гонконг)
- Китайский (упрощенный, мандаринский)
- Китайский (традиционный, мандаринский)
- Чоктавский
- Чувашский
- Кри
- Крикский
- Крымско-татарский
- Хорватский
- Чешский
- Дакота
- Датский
- Дивехи
- Дуала
- Нидерландский
- Дзонг-кэ
- Эфик
- Английский (США)
- Английский (Великобритания)
- Эсперанто
- Эстонский
- Эве
- Фарерский
- Фиджийский
- Филиппинский
- Финский
- Фон
- Французский (Канада)
- Французский (Европа)
- Фула
- Га
- Галисийский
- Ганда
- Гайо
- Грузинский
- Немецкий
- Кирибати
- Готский
- Греческий
- Гуарани
- Гуджарати
- Гаитянский креольский
- Хауса
- Гавайский
- Иврит
- Гереро
- Хилигайнон
Хинди - Венгерский
- Ибанский
- Исландский
- Игбо
- Илоканский
- Индонезийский
- Ирландский
- Итальянский
- Японский
- Яванский
- Кабильский
- Качинский
- Гренландский
- Камба
- Каннада
- Канури
- Каракалпакский
- Казахский
- Кхаси
- Кхмерский
- Кикуйю
- Киньярванда
- Киргизский
- Коми
- Конго
- Корейский
- Косяэ
- Куаньяма
- Лаосский
- Латынь
- Латышский
- Лингала
- Литовский
- Нижненемецкий
- Лози
- Луба-катанга
- Луо
- Македонский
- Мадурский
- Малагасийский
- Малайский
- Малаялам
- Мальтийский
- Мандинго
- Мэнский
- Маори
- Маратхи
- Маршалльский
- Менде
- Среднеанглийский
- Средневерхненемецкий
- Минангкабау
- Могаукский
- Монго
- Монгольский
- Науатль
- Навахо
- Ндонга
- Непальский
- Ниуэ
- Северный ндебеле
- Северный сото
- Норвежский (букмол)
- Ньянджа
- Ньянколе
- Тонга (Ньяса)
- Нзима
- Окситанский
- Оджибве
- Древнеанглийский
- Старофранцузский
- Древневерхненемецкий
- Древнескандинавский
- Старопровансальский
- Ория
- Осетинский
- Пампанга
- Пангасинанский
- Папьяменто
- Пушту
- Персидский
- Польский
- Португальский (Бразилия)
- Португальский (Европа)
- Панджаби (гурмукхи)
- Кечуа
- Румынский
- Романшский
- Цыганский
- Рунди
- Русский
- Русский (дореформенный)
- Якутский
- Самоанский
- Санго
- Санскрит
- Шотландский
- Шотландский (гэльский)
- Сербский (кириллица)
- Сербский (латиница)
- Шона
- Сингальский
- Словацкий
- Словенский
- Сонгай
- Южный сото
- Испанский (Европа)
- Испанский (Латинская Америка)
- Сунданский
- Суахили
- Свати
- Шведский
- Таитянский
- Таджикский
- Тамильский
- Татарский
- Телугу
- Темне
- Тайский
- Тибетский
- Тигринья
- Тонганский
- Тсонга
- Тсвана
- Турецкий
- Туркменский
- Удмуртский
- Урду
- Узбекский
- Узбекский (дореформенная кириллица)
- Венда
- Вьетнамский
- Водский
- Валлийский
- Фризский (западный диалект)
- Волоф
- Коса
- Идиш
- Йоруба
- Сапотекский
- Зулу
Mobile OCR Free – распознание текста на Android
Те приложения, которые мы уже описали, позволяют получить лишь изображение документа в виде файла формата PDF или JPG. Текст, к сожалению, также остается лишь частью картинки без возможности его редактирования в текстовом редакторе.
Этот вопрос предлагается решить следующим образом: зарегистрировать аккаунт в Google Drive и отправлять все «сканы» на сервер. При этом в настройках загрузки Google Drive должна быть включена опция «преобразовывать текст из файлов PDF и изображений». В результате хорошо читаемые документы будут преобразованы в обычный текст, который можно скопировать в любой редактор.
Но можно пойти и другим путем: установить приложение, позволяющее распознать текст сфотографированной страницы. В качестве примера мы решили рассмотреть Mobile OCR Free.
Слово «Free» в названии говорит о том, что данная версия бесплатна и некоторые ее возможности ограничены. В данном случае ограничение касается количества поддерживаемых языков, здесь их всего четыре. Русского языка нет, но есть английский, что позволит проверить работоспособность программы.
Для работы приложения необходимо подключение к интернету. В качестве исходного материала мы взяли страницу учебника по английскому языку и надпись на коробке от маршрутизатора. Освещение – лампы дневного света, расстояние до объекта примерно 30-35 см.
Результат, как видно из примеров, получился вполне приемлемым, хотя в первом случае небольшое редактирование все же не будет лишним. Тем не менее, на наш взгляд, в некоторых случаях быстрое распознавание способно значительно сэкономить временные затраты. Остается лишь соблюдать два условия: хорошее освещение и подключение к интернету.