Utf-8 geometric shapes
Содержание:
- Какие существуют кодировки
- Range: Decimal 8192-8303. Hex 2000-206F.
- Range: Decimal 9632-9727. Hex 25A0-25FF.
- What is meta charset?
- Как установить кодировку сайта
- Указание кодировки символов документа
- Настройка кодировки сайта
- Кодирование и декодирование
- Is it a ranking factor for SEO?
- Символы UTF-8 в веб-разработке
- Разрешенные кодировки
- Атрибуты
- Типы кодировок
- Неправильная кодировка HTML страниц
Какие существуют кодировки
Перечислим несколько наиболее удобных и популярных способов кодирования:
UTF-8
Unicode Transformation Format. Восьмибитное представление Юникода. Был изобретён в 1992 году и до сих пор является золотым стандартом всего программного обеспечения в мире. Для кириллицы в Юникоде выделено два раздела: Cyrillic и Cyrillic Supplement.
Windows-1251
Создана в 1990 году специально для русификаторов операционной системы Microsoft Windows. Кириллическая восьмибитная кодировка, занимает второе место по популярности.
KOI8-R
Восьмибитный стандарт кириллического кодирования. Если убрать у каждого символа восьмой бит, мы получим транскрипцию русских букв на латиницу. Иногда его применяют в электронной почте, но на сегодняшний день в интернете встречается редко.
Range: Decimal 8192-8303. Hex 2000-206F.
If you want any of these characters displayed in HTML, you can use the HTML
entity found in the table below.
If the character does not have an HTML entity, you can use the decimal (dec)
or hexadecimal (hex) reference.
Will display as:
I will display ‰
I will display ‰
I will display ‰
Older browsers may not support all the HTML5 entities in the table below.
Chrome and Opera have good support, and IE 11+ and Firefox 35+ support all the entities.
| Char | Dec | Hex | Entity | Name |
|---|---|---|---|---|
| 8192 | 2000 | EN QUAD | ||
| 8193 | 2001 | EM QUAD | ||
| 8194 | 2002 |   | EN SPACE | |
| 8195 | 2003 |   | EM SPACE | |
| 8196 | 2004 | THREE-PER-EM SPACE | ||
| 8197 | 2005 | FOUR-PER-EM SPACE | ||
| 8198 | 2006 | SIX-PER-EM SPACE | ||
| 8199 | 2007 | FIGURE SPACE | ||
| 8200 | 2008 | PUNCTUATION SPACE | ||
| 8201 | 2009 |   | THIN SPACE | |
| 8202 | 200A | HAIR SPACE | ||
| | 8203 | 200B | ZERO WIDTH SPACE | |
| | 8204 | 200C | ‌ | ZERO WIDTH NON-JOINER |
| | 8205 | 200D | ‍ | ZERO WIDTH JOINER |
| | 8206 | 200E | ‎ | LEFT-TO-RIGHT MARK |
| | 8207 | 200F | ‏ | RIGHT-TO-LEFT MARK |
| ‐ | 8208 | 2010 | HYPHEN | |
| ‑ | 8209 | 2011 | NON-BREAKING HYPHEN | |
| ‒ | 8210 | 2012 | FIGURE DASH | |
| – | 8211 | 2013 | – | EN DASH |
| — | 8212 | 2014 | — | EM DASH |
| ― | 8213 | 2015 | HORIZONTAL BAR | |
| ‖ | 8214 | 2016 | DOUBLE VERTICAL LINE | |
| ‗ | 8215 | 2017 | DOUBLE LOW LINE | |
| ‘ | 8216 | 2018 | ‘ | LEFT SINGLE QUOTATION MARK |
| ’ | 8217 | 2019 | ’ | RIGHT SINGLE QUOTATION MARK |
| ‚ | 8218 | 201A | ‚ | SINGLE LOW-9 QUOTATION MARK |
| ‛ | 8219 | 201B | SINGLE HIGH-REVERSED-9 QUOTATION MARK | |
| “ | 8220 | 201C | “ | LEFT DOUBLE QUOTATION MARK |
| ” | 8221 | 201D | ” | RIGHT DOUBLE QUOTATION MARK |
| „ | 8222 | 201E | „ | DOUBLE LOW-9 QUOTATION MARK |
| ‟ | 8223 | 201F | DOUBLE HIGH-REVERSED-9 QUOTATION MARK | |
| † | 8224 | 2020 | † | DAGGER |
| ‡ | 8225 | 2021 | ‡ | DOUBLE DAGGER |
| • | 8226 | 2022 | • | BULLET |
| ‣ | 8227 | 2023 | TRIANGULAR BULLET | |
| ․ | 8228 | 2024 | ONE DOT LEADER | |
| ‥ | 8229 | 2025 | TWO DOT LEADER | |
| … | 8230 | 2026 | … | HORIZONTAL ELLIPSIS |
| ‧ | 8231 | 2027 | HYPHENATION POINT | |
| 8232 | 2028 | LINE SEPARATOR | ||
| 8233 | 2029 | PARAGRAPH SEPARATOR | ||
| | 8234 | 202A | LEFT-TO-RIGHT EMBEDDING | |
| | 8235 | 202B | RIGHT-TO-LEFT EMBEDDING | |
| | 8236 | 202C | POP DIRECTIONAL FORMATTING | |
| | 8237 | 202D | LEFT-TO-RIGHT OVERRIDE | |
| | 8238 | 202E | RIGHT-TO-LEFT OVERRIDE | |
| 8239 | 202F | NARROW NON-BREAK SPACE | ||
| ‰ | 8240 | 2030 | ‰ | PER MILLE SIGN |
| ‱ | 8241 | 2031 | PER TEN THOUSAND SIGN | |
| ′ | 8242 | 2032 | ′ | PRIME |
| ″ | 8243 | 2033 | ″ | DOUBLE PRIME |
| ‴ | 8244 | 2034 | TRIPLE PRIME | |
| ‵ | 8245 | 2035 | REVERSED PRIME | |
| ‶ | 8246 | 2036 | REVERSED DOUBLE PRIME | |
| ‷ | 8247 | 2037 | REVERSED TRIPLE PRIME | |
| ‸ | 8248 | 2038 | CARET | |
| ‹ | 8249 | 2039 | ‹ | SINGLE LEFT-POINTING ANGLE QUOTATION MARK |
| › | 8250 | 203A | › | SINGLE RIGHT-POINTING ANGLE QUOTATION MARK |
| ※ | 8251 | 203B | REFERENCE MARK | |
| 8252 | 203C | DOUBLE EXCLAMATION MARK | ||
| ‽ | 8253 | 203D | INTERROBANG | |
| ‾ | 8254 | 203E | ‾ | OVERLINE |
| ‿ | 8255 | 203F | UNDERTIE | |
| ⁀ | 8256 | 2040 | CHARACTER TIE | |
| ⁁ | 8257 | 2041 | CARET INSERTION POINT | |
| ⁂ | 8258 | 2042 | ASTERISM | |
| ⁃ | 8259 | 2043 | HYPHEN BULLET | |
| ⁄ | 8260 | 2044 | ⁄ | FRACTION SLASH |
| ⁅ | 8261 | 2045 | LEFT SQUARE BRACKET WITH QUILL | |
| ⁆ | 8262 | 2046 | RIGHT SQUARE BRACKET WITH QUILL | |
| ⁇ | 8263 | 2047 | DOUBLE QUESTION MARK | |
| ⁈ | 8264 | 2048 | QUESTION EXCLAMATION MARK | |
| 8265 | 2049 | EXCLAMATION QUESTION MARK | ||
| ⁊ | 8266 | 204A | TIRONIAN SIGN ET | |
| ⁋ | 8267 | 204B | REVERSED PILCROW SIGN | |
| ⁌ | 8268 | 204C | BLACK LEFTWARDS BULLET | |
| ⁍ | 8269 | 204D | BLACK RIGHTWARDS BULLET | |
| ⁎ | 8270 | 204E | LOW ASTERISK | |
| ⁏ | 8271 | 204F | REVERSED SEMICOLON | |
| ⁐ | 8272 | 2050 | CLOSE UP | |
| ⁑ | 8273 | 2051 | TWO ASTERISKS ALIGNED VERTICALLY | |
| ⁒ | 8274 | 2052 | COMMERCIAL MINUS SIGN | |
| ⁓ | 8275 | 2053 | SWUNG DASH | |
| ⁔ | 8276 | 2054 | INVERTED UNDERTIE | |
| ⁕ | 8277 | 2055 | FLOWER PUNCTUATION MARK | |
| ⁖ | 8278 | 2056 | THREE DOT PUNCTUATION | |
| ⁗ | 8279 | 2057 | QUADRUPLE PRIME | |
| ⁘ | 8280 | 2058 | FOUR DOT PUNCTUATION | |
| ⁙ | 8281 | 2059 | FIVE DOT PUNCTUATION | |
| ⁚ | 8282 | 205A | TWO DOT PUNCTUATION | |
| ⁛ | 8283 | 205B | FOUR DOT MARK | |
| ⁜ | 8284 | 205C | DOTTED CROSS | |
| ⁝ | 8285 | 205D | TRICOLON | |
| ⁞ | 8286 | 205E | VERTICAL FOUR DOTS | |
| 8287 | 205F | MEDIUM MATHEMATICAL SPACE | ||
| | 8288 | 2060 | WORD JOINER | |
| | 8289 | 2061 | FUNCTION APPLICATION | |
| | 8290 | 2062 | INVISIBLE TIMES | |
| | 8291 | 2063 | INVISIBLE SEPARATOR | |
| | 8292 | 2064 | INVISIBLE PLUS | |
| | 8294 | 2066 | LEFT-TO-RIGHT ISOLATE | |
| | 8295 | 2067 | RIGHT-TO-LEFT ISOLATE | |
| | 8296 | 2068 | FIRST STRONG ISOLATE | |
| | 8297 | 2069 | POP DIRECTIONAL ISOLATE | |
| | 8298 | 206A | INHIBIT SYMMETRIC SWAPPING | |
| | 8299 | 206B | ACTIVATE SYMMETRIC SWAPPING | |
| | 8300 | 206C | INHIBIT ARABIC FORM SHAPING | |
| | 8301 | 206D | ACTIVATE ARABIC FORM SHAPING | |
| | 8302 | 206E | NATIONAL DIGIT SHAPES | |
| | 8303 | 206F | NOMINAL DIGIT SHAPES |
❮ Previous
Next ❯
Range: Decimal 9632-9727. Hex 25A0-25FF.
If you want any of these characters displayed in HTML, you can use the HTML
entity found in the table below.
If the character does not have an HTML entity, you can use the decimal (dec)
or hexadecimal (hex) reference.
Will display as:
I will display ►
I will display ►
Older browsers may not support all the HTML5 entities in the table below.
Chrome and Opera have good support, and IE 11+ and Firefox 35+ support all the entities.
| Char | Dec | Hex | Entity | Name |
|---|---|---|---|---|
| ■ | 9632 | 25A0 | BLACK SQUARE | |
| □ | 9633 | 25A1 | WHITE SQUARE | |
| ▢ | 9634 | 25A2 | WHITE SQUARE WITH ROUNDED CORNERS | |
| ▣ | 9635 | 25A3 | WHITE SQUARE CONTAINING BLACK SMALL SQUARE | |
| ▤ | 9636 | 25A4 | SQUARE WITH HORIZONTAL FILL | |
| ▥ | 9637 | 25A5 | SQUARE WITH VERTICAL FILL | |
| ▦ | 9638 | 25A6 | SQUARE WITH ORTHOGONAL CROSSHATCH FILL | |
| ▧ | 9639 | 25A7 | SQUARE WITH UPPER LEFT TO LOWER RIGHT FILL | |
| ▨ | 9640 | 25A8 | SQUARE WITH UPPER RIGHT TO LOWER LEFT FILL | |
| ▩ | 9641 | 25A9 | SQUARE WITH DIAGONAL CROSSHATCH FILL | |
| 9642 | 25AA | BLACK SMALL SQUARE | ||
| 9643 | 25AB | WHITE SMALL SQUARE | ||
| ▬ | 9644 | 25AC | BLACK RECTANGLE | |
| ▭ | 9645 | 25AD | WHITE RECTANGLE | |
| ▮ | 9646 | 25AE | BLACK VERTICAL RECTANGLE | |
| ▯ | 9647 | 25AF | WHITE VERTICAL RECTANGLE | |
| ▰ | 9648 | 25B0 | BLACK PARALLELOGRAM | |
| ▱ | 9649 | 25B1 | WHITE PARALLELOGRAM | |
| ▲ | 9650 | 25B2 | BLACK UP-POINTING TRIANGLE | |
| △ | 9651 | 25B3 | WHITE UP-POINTING TRIANGLE | |
| ▴ | 9652 | 25B4 | BLACK UP-POINTING SMALL TRIANGLE | |
| ▵ | 9653 | 25B5 | WHITE UP-POINTING SMALL TRIANGLE | |
| 9654 | 25B6 | BLACK RIGHT-POINTING TRIANGLE | ||
| ▷ | 9655 | 25B7 | WHITE RIGHT-POINTING TRIANGLE | |
| ▸ | 9656 | 25B8 | BLACK RIGHT-POINTING SMALL TRIANGLE | |
| ▹ | 9657 | 25B9 | WHITE RIGHT-POINTING SMALL TRIANGLE | |
| ► | 9658 | 25BA | BLACK RIGHT-POINTING POINTER | |
| ▻ | 9659 | 25BB | WHITE RIGHT-POINTING POINTER | |
| ▼ | 9660 | 25BC | BLACK DOWN-POINTING TRIANGLE | |
| ▽ | 9661 | 25BD | WHITE DOWN-POINTING TRIANGLE | |
| ▾ | 9662 | 25BE | BLACK DOWN-POINTING SMALL TRIANGLE | |
| ▿ | 9663 | 25BF | WHITE DOWN-POINTING SMALL TRIANGLE | |
| 9664 | 25C0 | BLACK LEFT-POINTING TRIANGLE | ||
| ◁ | 9665 | 25C1 | WHITE LEFT-POINTING TRIANGLE | |
| ◂ | 9666 | 25C2 | BLACK LEFT-POINTING SMALL TRIANGLE | |
| ◃ | 9667 | 25C3 | WHITE LEFT-POINTING SMALL TRIANGLE | |
| ◄ | 9668 | 25C4 | BLACK LEFT-POINTING POINTER | |
| ◅ | 9669 | 25C5 | WHITE LEFT-POINTING POINTER | |
| ◆ | 9670 | 25C6 | BLACK DIAMOND | |
| ◇ | 9671 | 25C7 | WHITE DIAMOND | |
| ◈ | 9672 | 25C8 | WHITE DIAMOND CONTAINING BLACK SMALL DIAMOND | |
| ◉ | 9673 | 25C9 | FISHEYE | |
| ◊ | 9674 | 25CA | ◊ | LOZENGE |
| ○ | 9675 | 25CB | WHITE CIRCLE | |
| ◌ | 9676 | 25CC | DOTTED CIRCLE | |
| ◍ | 9677 | 25CD | CIRCLE WITH VERTICAL FILL | |
| ◎ | 9678 | 25CE | BULLSEYE | |
| ● | 9679 | 25CF | BLACK CIRCLE | |
| ◐ | 9680 | 25D0 | CIRCLE WITH LEFT HALF BLACK | |
| ◑ | 9681 | 25D1 | CIRCLE WITH RIGHT HALF BLACK | |
| ◒ | 9682 | 25D2 | CIRCLE WITH LOWER HALF BLACK | |
| ◓ | 9683 | 25D3 | CIRCLE WITH UPPER HALF BLACK | |
| ◔ | 9684 | 25D4 | CIRCLE WITH UPPER RIGHT QUADRANT BLACK | |
| ◕ | 9685 | 25D5 | CIRCLE WITH ALL BUT UPPER LEFT QUADRANT BLACK | |
| ◖ | 9686 | 25D6 | LEFT HALF BLACK CIRCLE | |
| ◗ | 9687 | 25D7 | RIGHT HALF BLACK CIRCLE | |
| ◘ | 9688 | 25D8 | INVERSE BULLET | |
| ◙ | 9689 | 25D9 | INVERSE WHITE CIRCLE | |
| ◚ | 9690 | 25DA | UPPER HALF INVERSE WHITE CIRCLE | |
| ◛ | 9691 | 25DB | LOWER HALF INVERSE WHITE CIRCLE | |
| ◜ | 9692 | 25DC | UPPER LEFT QUADRANT CIRCULAR ARC | |
| ◝ | 9693 | 25DD | UPPER RIGHT QUADRANT CIRCULAR ARC | |
| ◞ | 9694 | 25DE | LOWER RIGHT QUADRANT CIRCULAR ARC | |
| ◟ | 9695 | 25DF | LOWER LEFT QUADRANT CIRCULAR ARC | |
| ◠ | 9696 | 25E0 | UPPER HALF CIRCLE | |
| ◡ | 9697 | 25E1 | LOWER HALF CIRCLE | |
| ◢ | 9698 | 25E2 | BLACK LOWER RIGHT TRIANGLE | |
| ◣ | 9699 | 25E3 | BLACK LOWER LEFT TRIANGLE | |
| ◤ | 9700 | 25E4 | BLACK UPPER LEFT TRIANGLE | |
| ◥ | 9701 | 25E5 | BLACK UPPER RIGHT TRIANGLE | |
| ◦ | 9702 | 25E6 | WHITE BULLET | |
| ◧ | 9703 | 25E7 | SQUARE WITH LEFT HALF BLACK | |
| ◨ | 9704 | 25E8 | SQUARE WITH RIGHT HALF BLACK | |
| ◩ | 9705 | 25E9 | SQUARE WITH UPPER LEFT DIAGONAL HALF BLACK | |
| ◪ | 9706 | 25EA | SQUARE WITH LOWER RIGHT DIAGONAL HALF BLACK | |
| ◫ | 9707 | 25EB | WHITE SQUARE WITH VERTICAL BISECTING LINE | |
| ◬ | 9708 | 25EC | WHITE UP-POINTING TRIANGLE WITH DOT | |
| ◭ | 9709 | 25ED | UP-POINTING TRIANGLE WITH LEFT HALF BLACK | |
| ◮ | 9710 | 25EE | UP-POINTING TRIANGLE WITH RIGHT HALF BLACK | |
| ◯ | 9711 | 25EF | LARGE CIRCLE | |
| ◰ | 9712 | 25F0 | WHITE SQUARE WITH UPPER LEFT QUADRANT | |
| ◱ | 9713 | 25F1 | WHITE SQUARE WITH LOWER LEFT QUADRANT | |
| ◲ | 9714 | 25F2 | WHITE SQUARE WITH LOWER RIGHT QUADRANT | |
| ◳ | 9715 | 25F3 | WHITE SQUARE WITH UPPER RIGHT QUADRANT | |
| ◴ | 9716 | 25F4 | WHITE CIRCLE WITH UPPER LEFT QUADRANT | |
| ◵ | 9717 | 25F5 | WHITE CIRCLE WITH LOWER LEFT QUADRANT | |
| ◶ | 9718 | 25F6 | WHITE CIRCLE WITH LOWER RIGHT QUADRANT | |
| ◷ | 9719 | 25F7 | WHITE CIRCLE WITH UPPER RIGHT QUADRANT | |
| ◸ | 9720 | 25F8 | UPPER LEFT TRIANGLE | |
| ◹ | 9721 | 25F9 | UPPER RIGHT TRIANGLE | |
| ◺ | 9722 | 25FA | LOWER LEFT TRIANGLE | |
| 9723 | 25FB | WHITE MEDIUM SQUARE | ||
| 9724 | 25FC | BLACK MEDIUM SQUARE | ||
| 9725 | 25FD | WHITE MEDIUM SMALL SQUARE | ||
| 9726 | 25FE | BLACK MEDIUM SMALL SQUARE | ||
| ◿ | 9727 | 25FF | LOWER RIGHT TRIANGLE |
❮ Previous
Next ❯
What is meta charset?
A charset or character set in full is essentially a set of characters recognized by the computer the same way the calculator can identify numbers. Each of these characters is represented by a number known as code point and this creates a communication channel for encoding and decoding content.
A character set, therefore, contains characters that serve a specific or particular purpose. The computer stores the characters as one or more bytes. An example is the ASCII character set which represents all English characters and special control characters with numbers from 0-127.
However, most character sets only work for specific languages and recognize limited characters and this makes the coding and encoding difficult or impossible. In modern times, however, the Unicode is the most reliable and universally accepted character set due to its ability to translate codes and numbers easily.
You can see the meta charset in the header of your html code
Как установить кодировку сайта
Вы открыли сайт, но вместо текста видите непонятные закорючки, иностранные символы или цифры. Чтобы привести страницу к обычному виду, нужно вручную задать используемую кодировку.
- Mozilla Firefox
- Заходим в меню – три горизонтальные полосы справа.
- Выбираем категорию «Еще».
- Далее раздел «Кодировка текста».
- Выбираем необходимую опцию.
Opera
- Заходим настройки.
- Выбираем «Веб-сайты».
- Переходим в блок «Отображение».
- Далее – «Настроить шрифты».
- В конце выбираете кодировку.
Google Chrome
- Перейдите в меню – три точки справа вверху.
- Выберите пункт «Дополнительные инструменты».
- Откройте раздел «Кодировка».
- Откроется окно с выбором различных кодировок.
Указание кодировки символов документа
Есть несколько способов указать, какая кодировка символов используется в документе. Во-первых, веб-сервер может включать кодировку символов или » » в заголовок протокола передачи гипертекста (HTTP) , который обычно выглядит следующим образом:
Content-Type: text/html; charset=utf-8
Этот метод дает HTTP-серверу удобный способ изменить кодировку документа в соответствии с согласованием содержимого ; определенное программное обеспечение HTTP-сервера может это сделать, например Apache с модулем .
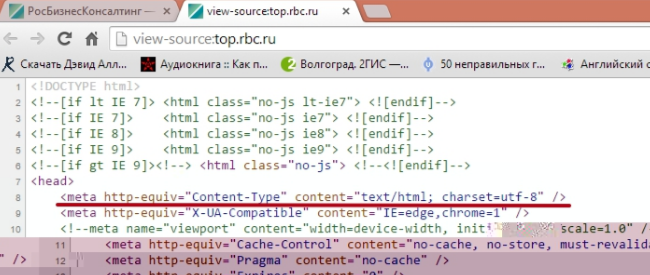
Для HTML можно включить эту информацию внутри элемента в верхней части документа:
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
HTML5 также позволяет следующему синтаксису означать то же самое:
<meta charset="utf-8">
У документов XHTML есть третий вариант: выразить кодировку символов через объявление XML следующим образом:
<?xml version="1.0" encoding="ISO-8859-1"?>
Поскольку кодировка символов не может быть известна до тех пор, пока это объявление не будет проанализировано, может возникнуть проблема, зная, какая кодировка используется для самого объявления. Главный принцип заключается в том, что объявление должно быть закодировано в чистом ASCII, и поэтому (если объявление находится внутри файла) кодировка должна быть расширением ASCII . Для того чтобы кодировки не были обратно совместимы с ASCII, браузеры должны иметь возможность анализировать объявления в таких кодировках. Примеры таких кодировок — UTF-16BE и UTF-16LE .
Начиная с HTML5, рекомендуемая кодировка — UTF-8 . В спецификации определен «алгоритм сниффинга кодирования» для определения кодировки символов документа на основе нескольких источников ввода, включая:
- Явная инструкция пользователя
- Явный метатег в первых 1024 байтах документа.
- Отметка порядка байтов в течение первых трех байтов документа
- HTTP Content-Type или другая информация транспортного уровня
- Анализ байтов документа в поисках определенных последовательностей или диапазонов значений байтов и другие механизмы предварительного обнаружения.
Для ASCII-совместимых кодировок символов следствием неправильного выбора является то, что символы за пределами печатаемого диапазона ASCII (от 32 до 126) обычно отображаются неправильно. Это создает несколько проблем для английских -speaking пользователей, но и другие языки регулярно , в некоторых случаях, всегда требуют-символы за пределами этого диапазона. В средах CJK, где используется несколько различных многобайтовых кодировок, также часто используется автоматическое обнаружение. Наконец, браузеры обычно позволяют пользователю вручную переопределить неправильную метку кодировки.
Для многоязычных веб-сайтов и веб-сайтов на незападных языках все чаще используется UTF-8 , который позволяет использовать одну и ту же кодировку для всех языков. UTF-16 или UTF-32 , которые также могут использоваться для всех языков, менее широко используются, потому что их может быть труднее обрабатывать в языках программирования, которые предполагают байтовую кодировку расширенного набора ASCII, и они менее эффективны для текста с высокая частота символов ASCII, что обычно характерно для документов HTML.
Успешный просмотр страницы не обязательно означает, что ее кодировка указана правильно. Если создатель страницы и читатель оба предполагают некоторую кодировку символов, зависящую от платформы, и сервер не отправляет никакой идентифицирующей информации, то читатель, тем не менее, будет видеть страницу так, как задумал создатель, но другие читатели на разных платформах или с разными родными языками не увидит страницу должным образом.
Настройка кодировки сайта
Если вы владелец проблемного сайта, на который жалуются посетители за неправильно работающую кодировку, стоит заново настроить портал для правильной работы по следующим пунктам. Главное правило, которое должно действовать для всего проекта – единая кодировка файлов, скриптов, баз данных и сервера.
- Сохраните все файлы сайта в единой кодировке. При необходимости измените её с помощью специальных программ, например Notepad++.
- Установите в html кодетеги кодировок. Для UTF8 кодировки это будет.
- Задайте кодировку серверных заголовков по умолчанию. Без этого браузер будет игнорировать даже метатеги.
- Отредактируйте файл httpd.conf. Найдите параметр AddDefaultCharset и установите необходимое значение.
- Если у вас нет доступа к корневым настройкам веб-сервера, отредактируйте файл .htaccess в папке ресурса. Укажите вручную параметр AddDefaultCharset с вашей кодировкой сайта.
- Существует возможность отправки заголовков средствами скриптов. Например, в PHP-скриптах достаточно добавить header(«Content-type: text/html; Charset=utf-8»). Отправка заголовков – приоритетная задача, и она должна выполняться в первую очередь перед выводом контента.
Придется вручную установить верную кодировку соединения для подключаемых модулей. Приведем пример конфигурации для популярной БД MySQL:
- Откройте на сервере конфиг my.cnf.
- В области добавьте блок default-character-set=utf8.
- В области добавьте блок character_set_server=utf8 и
collation_server=utf8_unicode_ci. - Задайте принудительную кодировку при каждом обращении в PHP.
- mysqli_query(‘SET NAMES utf8 COLLATE utf8_general_ci’).
Неверная настройка кодировки сайта может навредить вашим посетителям, за счёт чего вы потеряете посещаемость и доход. Заходя на сайт, аудитория увидит непонятные отталкивающие наборы несвязанных символов. Никто не станет настраивать все вручную, чтобы поменять кодировку сайта на правильную, 95% пользователей просто уйдут со страницы. Подходите к этой проблеме с максимальной ответственностью. От правильного выбора кодировки зависит дальнейшая работа всего проекта.
Кодирование и декодирование
Кодирование— это процесс формирования определенного представления информации,переход от одной формы представления информации к другой, более удобной для хранения, передачи или обработки.То есть любой символ, который мы видим или вводим, для компьютера в реальности — всего лишь набор битов (набор нулей и единиц). Именно эти биты и перегоняются от устройства к устройству. А чтобы показать результат этих перегонок человеку, компьютер преобразует с помощью таблицы (той самой кодировки) код символа в соответствующий внешний вид.
UTF-32LE в UTF-8
Схемой можете воспользоваться при кодировании и раскодировании.
Эта схема сделана так, чтобы вы видели какие биты куда попадают как при кодировании, так и раскодировании.
По ней видно что при этих обоих процессах просто нужные биты выставляются на нужные позиции при нужных значениях контрольных бит.
Можно заметить что компоновка в больших байтовых последовательностях осуществляется по 6 бит (в так называемых лидирующих байтах).
При этом старшие биты предусматриваемого кода будут в первых байтах (схоже с порядком Big-Endian).

Кодирование
Порядок действий такой:
- Каждый символ превращаем в Unicode.
- Проверяем из какого диапазона символ.
- Если код символа меньше 128, то к результату добавляем его в неизменном виде.
- Если код символа меньше 2048, то берем последние 6 бит и первые 5 бит кода символа. К первым 5 битам добавляем 0xC0 и получаем первый байт последовательности, а к последним 6 битам добавляем 0x80 и получаем второй байт. Конкатенируем и добавляем к результату.
- Похожим образом можем продолжить и для больших кодов, но если символ за пределами U+FFFF придется иметь дело с UTF-16 суррогатами.
Function EncodeUTF8(s)
Dim i, c, utfc, b1, b2, b3
For i=1 to Len(s)
c = ToLong(AscW(Mid(s,i,1)))
If c < 128 Then
utfc = chr( c)
ElseIf c < 2048 Then
b1 = c Mod &h40
b2 = (c - b1) &h40
utfc = chr(&hC0 + b2) & chr(&h80 + b1)
ElseIf c < 65536 And (c < 55296 Or c > 57343) Then
b1 = c Mod &h40
b2 = ((c - b1) &h40) Mod &h40
b3 = (c - b1 - (&h40 * b2)) &h1000
utfc = chr(&hE0 + b3) & chr(&h80 + b2) & chr(&h80 + b1)
Else
' Младший или старший суррогат UTF-16
utfc = Chr(&hEF) & Chr(&hBF) & Chr(&hBD)
End If
EncodeUTF8 = EncodeUTF8 + utfc
Next
End Function
Function ToLong(intVal)
If intVal < Then
ToLong = CLng(intVal) + &H10000
Else
ToLong = CLng(intVal)
End If
End Function
Декодирование
Декодирование — преобразование зашифрованной информации в понятный, пригодный для непосредственного использования вид.
- Ищем первый символ вида 11xxxxxx
- Считаем все последующие байты вида 10xxxxxx
- Если последовательность из двух байт и первый байт вида 110xxxxx, то отсекаем приставки и складываем, умножив первый байт на 0x40.
- Аналогично для более длинных последовательностей.
- Заменяем всю последовательность на нужный символ Unicode.
Function DecodeUTF8(s)
Dim i, c, n, b1, b2, b3
i = 1
Do While i <= len(s)
c = asc(mid(s,i,1))
If (c and &hC0) = &hC0 Then
n = 1
Do While i + n <= len(s)
If (asc(mid(s,i+n,1)) and &hC0) <> &h80 Then
Exit Do
End If
n = n + 1
Loop
If n = 2 and ((c and &hE0) = &hC0) Then
b1 = asc(mid(s,i+1,1)) and &h3F
b2 = c and &h1F
c = b1 + b2 * &h40
Elseif n = 3 and ((c and &hF0) = &hE0) Then
b1 = asc(mid(s,i+2,1)) and &h3F
b2 = asc(mid(s,i+1,1)) and &h3F
b3 = c and &h0F
c = b3 * &H1000 + b2 * &H40 + b1
Else
' Символ больше U+FFFF или неправильная последовательность
c = &hFFFD
End if
s = left(s,i-1) + chrw( c) + mid(s,i+n)
Elseif (c and &hC0) = &h80 then
' Неожидаемый продолжающий байт
s = left(s,i-1) + chrw(&hFFFD) + mid(s,i+1)
End If
i = i + 1
Loop
DecodeUTF8 = s
End Function
Is it a ranking factor for SEO?
The character set is not a ranking factor for search engine optimization. Most search engines focus on the important goal of delivering relevant, useful content to those who seek it and as such does not consider other outside factors that do not contribute to that goal.
So your character set matters because of how you transmit information but search engines are not interested in it. Using other charsets apart from Utf-8 will not decrease your SEO ranking because to a large extent it doesn’t matter what character encoding you use as long as the search engine is able to get information to the end users.
Символы UTF-8 в веб-разработке
UTF-8 – наиболее распространенный метод кодирования символов, используемый сегодня в Интернете, и набор символов по умолчанию для HTML5. Таким образом хранятся персонажи более 95% всех веб-сайтов, в том числе и ваш собственный. Кроме того, распространенные методы передачи данных через Интернет, такие как XML и JSON, кодируются стандартами UTF-8.
Поскольку теперь это стандартный метод кодирования текста в Интернете, все страницы вашего сайта и базы данных должны использовать UTF-8. Система управления контентом или конструктор веб-сайтов по умолчанию сохранят ваши файлы в формате UTF-8, но все же рекомендуется убедиться, что вы придерживаетесь этой передовой практики.
Текстовые файлы, закодированные с помощью UTF-8, должны указывать на это программному обеспечению, обрабатывающему их. В противном случае программа не сможет должным образом преобразовать двоичный код обратно в символы. В файлах HTML вы можете увидеть строку кода, подобную следующей, вверху:
Это сообщает браузеру, что файл HTML закодирован в UTF-8, чтобы браузер мог преобразовать его обратно в разборчивый текст.
Разрешенные кодировки
WHATWG Encoding Standard, на который ссылается последними стандарты HTML (текущий WHATWG HTML Living Standard, а также ранее конкурирующий W3C HTML 5.0 и 5.1) определяет список кодировок , которые должны поддерживать браузеры. Стандарты HTML запрещают поддержку других кодировок. Стандарт кодирования также предусматривает, что новые форматы, новые протоколы (даже когда используются существующие форматы) и авторы новых документов должны использовать исключительно UTF-8 .
Помимо UTF-8, следующие кодировки явно перечислены в самом стандарте HTML со ссылкой на стандарт кодирования:
- ISO-8859-2
- ISO-8859-7
- ISO-8859-8
- Окна-874
- Окна-1250
- Окна-1251
- Окна-1252
- Окна-1254
- Окна-1255
- Окна-1256
- Окна-1257
- Окна-1258
- GB18030
- Big5
- Shift JIS
- ISO-2022-JP
- EUC-KR
- UTF-16BE
- UTF-16LE
- x-определяемый пользователем
Следующие дополнительные кодировки перечислены в Стандарте кодирования, и поэтому также требуется их поддержка:
- Кодовая страница 866
- ISO-8859-3
- ISO-8859-4
- ISO-8859-5
- ISO-8859-6
- ISO-8859-8- I
- ISO-8859-10
- ISO-8859-13
- ISO-8859-14
- ISO-8859-15
- ISO-8859-16
- КОИ8-Р
- КОИ8-У / КОИ8-РУ
- Mac OS Роман
- Окна-1253
- Mac OS кириллица
- ГБК
- EUC-JP
Следующие кодировки указаны как явные примеры запрещенных кодировок:
- ЦЭСУ-8
- UTF-7
- BOCU-1
- ГКГУ
- EBCDIC
- UTF-32
Стандарт также определяет «замещающий» декодер, который отображает весь контент, помеченный как определенные кодировки, на заменяющий символ ( ), вообще отказываясь его обрабатывать. Это предназначено для предотвращения атак (например, межсайтовых сценариев ), которые могут использовать разницу между клиентом и сервером в поддерживаемых кодировках, чтобы замаскировать вредоносный контент. Хотя та же проблема безопасности относится к ISO-2022-JP и UTF-16 , которые также позволяют по-разному интерпретировать последовательности байтов ASCII, этот подход не рассматривался для них как выполнимый, поскольку они сравнительно чаще используются в развернутом контенте. Следующие кодировки обрабатываются так:
- ISO-2022-KR
- ISO-2022-CN
- ISO-2022-CN-EXT
- HZ-GB-2312
Атрибуты
- charsetHTML5
- Указывает кодировку символов для текущего HTML-документа. Авторам рекомендуется использовать значение UTF-8.
Тег <meta> с атрибутом charset лучше всего располагать в качестве первого дочернего элемента внутри элемента <head>. Чтобы текст на странице отображался корректно, кодировка, указанная в значении атрибута должна совпадать с кодировкой самого документа. - content
- Устанавливает значение атрибута, заданного с помощью name или http-equiv.
- http-equiv
- Контролирует действия браузера на данной веб-странице (эквивалент HTTP заголовков). При отображении страницы браузер будет следовать инструкциям, заданным в атрибуте: — указывает предпочтительный стиль для использования на странице. Атрибут content должен содержать идентификатор элемента <link>, который ссылается на таблицу стилей CSS, или идентификатор элемента <style>, содержащего таблицу стилей. — указывает время в секундах до перезагрузки страницы или время до перенаправления на другую страницу, если в атрибуте content после указания времени идет строка «url=адрес_страницы».
Автоматическая перезагрузка страницы через заданный промежуток времени, в данном примере, через 30 секунд:
Если необходимо сразу перебросить посетителя на другую страницу, то можно указать URL-адрес в параметре url: - name
-
Обеспечивает дополнительное описание тега. Если этот атрибут опущен, он считается эквивалентным атрибуту . Не должен использоваться в случае, если для элемента уже заданы атрибуты , или . — указывает название веб-приложения, используемого на странице. — используется для указания имени автора веб-страницы:
— является описанием страницы, оно чаще всего используется поисковыми системами для определения, чему та посвящена, например:
— указывает один из пакетов программного обеспечения, используемого для создания документа, например:
— содержит список ключевых слов, разделенных запятыми, соответствующих содержимому страницы, например:— предотвращает кэширование страницы браузером, например:
— может быть использован для указания того, когда у страницы должен истечь срок актуальности (и она
должна быть удалена из кэша), например:
— показывает, должны ли поисковые системы включать данную страницу в результаты поиска. Например, значение устанавливает, что поисковые системы могут включать данную страницу в результаты поиска, но не должны показывать страницы, на которые ведут ссылки с нее:— позволяет разработчикам управлять размером исходной области просмотра на различных устройствах:
width=device-width — указывает браузеру задать ширину области просмотра равную ширине экрана устройства какой бы она ни была;initial-scale=1.0 — устанавливает начальный уровень масштабирования при первой загрузке страницы браузером. - scheme
- Указывает полезную информацию о схеме или названии самой схемы, которая должна быть использована для уточнения значения свойства атрибута content.
Элемент поддерживает глобальные атрибуты и события.
Типы кодировок
Существует несколько типов кодировок:
- ASCII – первая кодировка, которая была признана Американским национальным институтом мировых стандартов. Для ее использования задействуется 7 бит, где первые 128 значений включают в себя весь английский алфавит, числа, знаки и символы. Такая кодировка ранее использовалась на англоязычных ресурсах.
- Кириллица – вариант российской кодировки, используемый на русскоязычных сайтах и блогах.
- КОИ8 (код обмена информацией 8-битный) – была разработана для кодирования букв кириллических алфавитов. Распространена в Unix-подобных ОС и электронной почте. Постепенно исчезает в связи с приходом Юникода.
- Windows 1250-1258 – 8-битные кодировки, зародившиеся после появления операционной системы Windows. Например, 1250 – все языки центральной Европы, 1251 – кириллица. В ней присутствуют все буквы русского алфавита, а также символы (за исключением знака ударения).
- UTF-8 – наиболее используемый тип кодировок, работающий практически со всеми языками мира. Символы занимают от 1 до 4 байт, что дает возможность создавать мультиязычные веб-сайты. Помимо UTF-8, есть такие варианты, как UTF-16 и UTF-32, однако предпочтение отдается первому типу.
Существуют и другие типы кодировок, но они используются в меньшей степени либо не используются вообще.
Неправильная кодировка HTML страниц
Создадим тестовый файлик:
sudo gedit /var/www/html/encoding.html
Скопируем в него следующий HTML код, в котором отсутствует указание кодировки и посмотрим, какие проблемы могут с ним возникнуть и как их решить:
<html>
<head>
<title>Проверка кодировки</title>
</head>
<body>
<h1>Тестовый файл для проверки кодировки</h1>
</body>
</html>
Откроем этот файл в браузере http://localhost/encoding.html
Как можно видеть, кодировка браузером определена неправильно:
Имеется несколько способов исправить эту ситуацию. Начнём с самого простого – явно указать кодировку для веб-страницы. Это делается метатегом, который должен быть расположен внутри тэга head:
<meta http-equiv="content-type" content="text/html; charset=utf-8" />
Добавим эту строку к нашему тестовому файлику, чтобы получилось так:
<html>
<head>
<title>Проверка кодировки</title>
<meta http-equiv="content-type" content="text/html; charset=utf-8" />
</head>
<body>
<h1>Тестовый файл для проверки кодировки</h1>
</body>
</html>
Как мы можем убедиться на следующем скриншоте, проблема решена:
Если кодировка вашего файла отличается от UTF-8, то вместо неё поставьте windows-1251 или ту, которая соответствует кодировке веб-страницы. Чтобы научиться определять кодировку файлов, посмотрите эту инструкцию.
Это был самый простой способ исправления проблемы с кодировкой – без изменения настроек сервера.
Вернём наш тестовый файл в исходное состояние и продолжим изучение способов указания кодировки.
Если файлы .htaccess включены настройками Apache, то эти файлы можно использовать чтобы указывать кодировку отправляемых веб-сервером страниц. Чтобы включить поддержку файлов .htaccess в конфигурационном файле Apache ( /etc/apache2/apache2.conf ) найдите группу строк
<Directory /var/www/> Options Indexes FollowSymLinks AllowOverride None Require all granted </Directory>
И в ней замените
AllowOverride None
на
AllowOverride All
После этого сервер нужно перезапустить.
sudo systemctl restart apache2.service
Файл .htaccess должен быть размещён в той же директории, что и сайт. Мой сайт размещён в корневой директории веб-сервера. Если у вас также, то теперь в папке /var/www/html/ создайте файл .htaccess и добавьте в него директиву AddDefaultCharset после которой укажите желаемую кодировку. Примеры
AddDefaultCharset UTF-8
ИЛИ
AddDefaultCharset windows-1251
Можно указать кодировку, которая будет применена только к файлам определённого формата:
AddCharset utf-8 .atom .css .js .json .rss .vtt .xml
Набор файлов может быть любым, например:
AddCharset utf-8 .html .css .php .txt .js
Следующий вариант является альтернативным и также позволяет устанавливать кодировку для файлов определённого типа, для него нужно, чтобы был включён mod_headers:
<Files ~ "\.html?$">
Header set Content-Type "text/html; charset=utf-8"
</Files>
Ещё один вариант, который также можно использовать в файле .htaccess для установки кодировки UTF-8:
IndexOptions +Charset=utf-8
Если сайт на PHP, то дополнительно может понадобиться продублировать кодировку с php_value default_charset:
AddDefaultCharset windows-1251 php_value default_charset "cp1251"
Можно вместо создания файла .htaccess установить кодировку в конфигурационном файле веб-сервера. Для Apache CentOS/Fedora это файл httpd.conf, а на Debian/Ubuntu это файл apache2.conf. Добавьте следующую строку для установки кодировки и перезапустите веб-сервер, чтобы изменения вступили в силу:
AddDefaultCharset UTF-8