10 инструментов, которые помогут найти удалённую страницу или сайт
Содержание:
- Юридические проблемы с архивным контентом
- Блокировка Архива Интернета
- Origins, growth and storage
- Reasons for using the Wayback Downloader
- DomainTools
- Installation Method 1: The Easy Method
- archive.md
- How to Use the Wayback Machine
- Юридические проблемы с архивным контентом
- Архивы веб-страниц, постоянные
- Group 2: Software to make your own web archive
- Which Sites Are Cataloged?
- Как избавиться от рекламы WAYBACK MACHINE в Chrome/Firefox/Internet Explorer/Edge?
Юридические проблемы с архивным контентом
Против Internet Archive было возбуждено несколько дел специально за его усилия по архивированию Wayback Machine.
Саентология
В конце 2002 года Интернет-архив удалил из Wayback Machine различные сайты, критикующие Саентологию . В сообщении об ошибке говорилось, что это было ответом на «запрос владельца сайта». Позже выяснилось, что юристы Церкви Саентологии требовали удаления, а владельцы сайта не хотели, чтобы их материалы были удалены.
Healthcare Advocates, Inc.
В 2003 году компания Harding Earley Follmer & Frailey защитила клиента от спора о товарном знаке с помощью Archive’s Wayback Machine. Адвокаты смогли продемонстрировать недействительность требований истца на основании содержания их веб-сайтов за несколько лет до этого. Истец, Healthcare Advocates, затем внес поправки в свою жалобу, включив в нее Интернет-архив, обвинив организацию в нарушении авторских прав, а также в нарушениях Закона США » Об авторском праве в цифровую эпоху» и Закона о компьютерном мошенничестве и злоупотреблениях . Healthcare Advocates утверждали, что, поскольку они установили файл robots.txt на своем веб-сайте, даже если после подачи первоначального иска Архив должен был удалить все предыдущие копии веб-сайта истца с Wayback Machine, однако некоторые материалы продолжали оставаться быть общедоступным на Wayback. Иск был урегулирован во внесудебном порядке после того, как Wayback устранил проблему.
Сюзанна Шелл
Активист Suzanne Shell подал иск в декабре 2005 года, потребовав Internet Archive платить 100000 $ HER США для архивирования ее сайта profane-justice.org в период между 1999 и 2004 Internet Archive подал декларативное суждение иска в окружном суде Соединенных Штатов для северного округа Калифорнии на 20 января 2006 г., добиваясь судебного определения, что Internet Archive не нарушает авторские права Shell . Shell ответила и подала встречный иск против Internet Archive за архивирование ее сайта, что, как она утверждает, нарушает ее условия обслуживания . 13 февраля 2007 г. судья Окружного суда США округа Колорадо отклонил все встречные иски, за исключением нарушения контракта . Интернет-архив не стал отказываться от претензий Shell о нарушении авторских прав, связанных с ее копировальной деятельностью, которая также будет продолжена.
25 апреля 2007 г. Internet Archive и Сюзанна Шелл совместно объявили об урегулировании своего иска. Интернет-архив заявил, что «… не заинтересован во включении в Wayback Machine материалов лиц, которые не желают архивировать свой веб-контент. Мы признаем, что г-жа Шелл имеет действующие и подлежащие исполнению авторские права на свой веб-сайт, и мы сожалеем. что включение ее веб-сайта в Wayback Machine привело к судебному разбирательству «. Shell заявила: «Я уважаю историческую ценность цели Internet Archive. Я никогда не собирался мешать достижению этой цели или причинять ей какой-либо вред».
Даниил Давыдюк
В период с 2013 по 2016 год порнографический актер по имени Даниэль Давыдюк пытался удалить свои заархивированные изображения из архива Wayback Machine, сначала отправив несколько запросов DMCA в архив, а затем обратившись в Федеральный суд Канады .
Блокировка Архива Интернета
В России
| Внешние изображения |
|---|
В октябре 2014 года Роскомнадзор заблокировал на территории РФ доступ к некоторым страницам Архива Интернета за видеоролик «Звон мечей» экстремистской группировки «Исламское государство Ирака и Леванта» (нынешнее название — «Исламское государство»). Ранее блокировались только ссылки на отдельные материалы в архиве, однако 24 октября 2014 года в реестр запрещённых сайтов временно был включён сам домен и его IP-адрес.
16 июня 2015 года на основании статьи 15.3 закона «Об информации, информационных технологиях и о защите информации» генпрокуратура РФ приняла решение о блокировке страницы «Одиночный джихад в России», содержащей, по её мнению, «призывы к массовым беспорядкам, осуществлению экстремистской деятельности, участию в массовых мероприятиях, проводимых с нарушением установленного порядка», в действительности на территории России был заблокирован доступ ко всему сайту, кроме .
С апреля 2016 года Роскомнадзор решил убрать сайт из блокировок, и он доступен в России.
По состоянию на 22 августа 2019 года в Мосгорсуде находятся на рассмотрении иски Ассоциации по защите авторских прав в интернете (АЗАПИ), в которых заявлено требование о блокировке интернет-портала archive.org на территории России в связи с нарушениями авторских прав.
В других странах СНГ
Архив Интернета был заблокирован на территории Казахстана в 2015 году (по состоянию на 25 февраля 2021 года сайт остаётся недоступным для казахстанцев).
Также в 2017 году сообщалось о блокировках Архива Интернета в Киргизии.
archive.org также заблокирован на территории Таджикистана[источник не указан 92 дня].
В Индии
В Индии Архив был частично заблокирован судебным решением в августе 2017 года. Решение Madras High Court перечисляло 2,6 тыс. адресов в сети Интернет, которые способствовали пиратскому распространению ряда фильмов двух местных кинокомпаний. Представители проекта безуспешно пытались связаться с министерствами.
Origins, growth and storage
Snapshots usually become available more than 6 months after they are archived, or in some cases, even later, 24 months or longer. The frequency of snapshots is variable, so not all tracked web site updates are recorded. Intervals of several weeks or years sometimes occur.
In 2011 a new, improved version of the Wayback Machine, with an updated interface and fresher index of archived content, was made available for public testing.
In March 2011 it was said on the Wayback Machine forum that «The Beta of the new Wayback Machine has a more complete and up-to-date index of all crawled materials into 2010, and will continue to be updated regularly. The index driving the classic Wayback Machine only has a little bit of material past 2008, and no further index updates are planned, as it will be phased out this year.»
Reasons for using the Wayback Downloader
What possible reasons can you have to download sites from the Wayback Machine?
- Missed hosting payments. Let’s say you’re super responsible webmaster. You always update and keep fresh content. You do security updates. You’re on top of things. But one day, you visit your website and all your content is gone! It’s in this moment that you remember that you forgot to change that credit card that was linked to your hosting account. Now all your content is gone! Dashed away by one false move..or is it? Enter our web Archive download bot. With a few simple clicks, you can be on your way to restoring a whole website — exactly like it used to be.
- Nostalgia. Maybe you played a computer game as a teenager or you used to frequently visit some hobby website. Many of these websites change or go offline, but with an archive.org download order, you can recover all your nostalgic memories.Simply go to our wayback machine download site and create your own web.archive.org download. This includes your whole website, up to 10 levels deep, which means all pages that are 10 clicks away from the front page.
- Your site was hacked. What if a more sinister plot involving a hacker compromising the security of your site arises? He’s hijacked your site, and now all your content has been deleted and replaced with ads for his own benefit. Not to worry! We have you covered with a nice Wayback machine download of your website, as it was before disaster struck.
- Legal evidence. Should you ever find yourself embroiled in a legal battle over whatever the issue may be, The Wayback Downloader can help here too. Make a copy of the web archive data for use as evidence in lawsuits. For example, patent law and evidence of prior art. The Wayback Machine accepts removal requests, so it’s a good idea to have your own copy in case the website disappears from the web archive.
- Take content from bankrupt competitor. What if one of your biggest competitors has gone out of business, and with their exit from the business they also took down their website? Remember the URL? Voila! You’ve got yourself a ton of useable information to populate your new site with one less competitor to worry about. Basically, this can be for any site in your industry that was taken offline.
- For recovering expired content. Sometimes you have good expired content — perhaps you found it with our service or with software like the Expired Article Hunter. Let’s say you have a good PBN domain with high metrics, and you have another domain with good expired content. Now you can merge the two domains and rebuilding the expired content on the domain with high metrics. It’s one of the quickest and best methods to build a PBN
- Use it as an alternative to httrack. Httrack is software to scrape live websites, but it doesn’t do a very good job at scraping the internet archive. We rebuild websites as they once were, while httrack simply copies a complete site, including all the headers and archive URLs.
DomainTools
If you want to find out Whois information or are looking for Wayback Machine alternative then you need to give a try to DomainTools screenshots lookup. As the name of this website suggests, it is going to provide you information about a domain name for free and screenshot history as well.
This website is famous for finding out domain owner and registration information etc. However, you can also find out details such as domain history, how the website looked some time ago using Domain Tools.
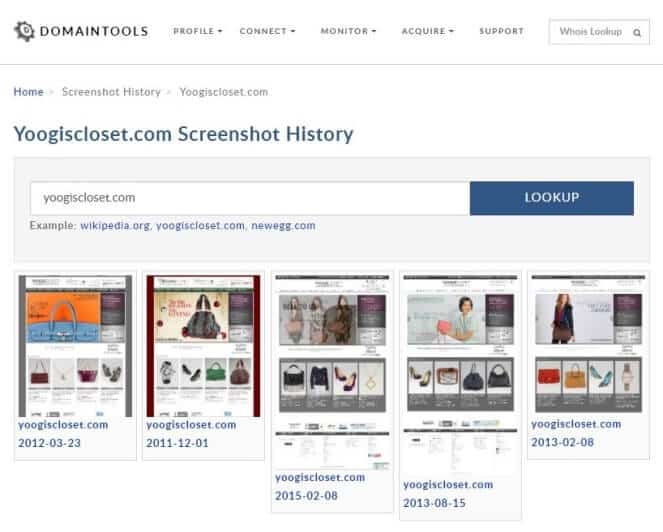
The functioning of Domain tools is similar to Screenshots.com as you just have to enter the URL of the website in the search bar and it will list you all the screenshots which are available for that particular website. The database of DomainTools is updated from time to time which makes it a worthy Internet Wayback Machine alternative.
Installation Method 1: The Easy Method
- 1. Register the domain with your hosting company. If you have registered the domain elsewhere, then create an add-on domain in the cPanel of your hosting company. Here is a tutorial from GoDaddy, that explains how to create an add-on domain.
- 2. Login to cPanel and go to «File Manager», as shown in the picture below:
- 3. Browse to the root folder of your domain. Normally this is /public_html/example.com, as shown below. For this tutorial, we used the domain buy-searchengine.com. Then click on «Upload»:
- 4. Then upload the ZIP file, as shown in the picture below. This assumes that you have already downloaded the ZIP file from waybackmachinedownloader.com.
- 5. Extract the ZIP file:
- 6. That’s it! If you purchased the domain and the hosting from different companies, then you still have to change the name servers at your domain registrar, and change them with the name servers from your hosting company.
- 7. If you want to edit the front page, then go to the File Manager and edit the index.html file, using a text editor. You might find it easier to copy part of that file and edit it with an online HTML editor.
WordPress installation instructions
If you also ordered the WordPress conversion, then wait until one of our developers sends you a ZIP file with WordPress files. This might take up to 48 hours after the scraping has finished.
It might sound strange, but you can not use a «Managed WordPress» hosting package. It doesn’t provide enough rights to edit the database. However, any cheap shared hosting package works, as long as it uses Apache. You can get this from providers such as Godaddy or Hostgator. We recommend Namecheap because it’s good enough and costs only $35/year.
- 8. Upload and extract this ZIP file as described above in step 2-6, in the same way as you would do with a zip file with HTML files. In the ZIP file there is also a folder called «database». If you want to save some time, you can remove this folder from the ZIP file, because you do not need to upload it. You will need the folder later though.
- 9. Go to your cPanel and open «MySQL Databases». Create a new database. You can name it anything, but in our example we use the name of our domain. You will need this name later, so pick something easy.
- 10. Create a new user and password. The name can be anything, but you’ll need it later.
- 11. Add this user to the database. Give your new user access to all privileges.
- 12. On your own computer, unzip the folder called «database». For example, unzip this to your desktop.
- 13. Go to your cPanel and open «phpMyAdmin».
- 14. First select your database on the left panel, by clicking on it. Then click «import» and import the database. This is the .sql file in the folder called «database».
- 15. Go to File Manager and find the file called «wp-config.php». Open this file in a text editor.
-
16. In wp-config.php, edit the database name, database user name and database password. Use the values that you created in step 9 and 10.
With some hosts you also have to change the hostname, but with 95%+ of hosting companies, you can leave this as «localhost». For example with iPage it is «UsernameOfYourAccount.ipagemysql.com» - 17. That’s it! Your WordPress website should now work.
archive.md
Адреса данного Архива Интернета:
На главной странице говорящие за себя поля:
- Архивировать страницу, которая сейчас онлайн
- Искать сохранённые страницы
Для поиска по сохранённым страницам можно как указывать конкретный URL, так и домены, например:
- microsoft.com покажет снимки с хоста microsoft.com
- *.microsoft.com покажет снимки с хоста microsoft.com и всех его субдоменов (например, www.microsoft.com)
- покажет архив данного url (поиск чувствителен к регистру)
- поиск архивных url начинающихся с http://twitter.com/burg
Данный сервис сохраняет следующие части страницы:
- Текстовое содержимое веб страницы
- Изображения
- Содержимое фреймов
- Контент и изображения загруженные или сгенерированные с помощью Javascript на сайтах Web 2.0
- Скриншоты размером 1024×768 пикселей.
Не сохраняются следующие части веб-страниц:
- Flash и загружаемый им контент
- Видео и звуки
- RSS и другие XML-страницы сохраняются ненадёжно. Большинство из них не сохраняются, или сохраняются как пустые страницы.
Архивируемая страница и все изображения должны быть менее 50 Мегабайт.
Для каждой архивированной страницы создаётся ссылка вида http://archive.is/XXXXX, где XXXXX это уникальный идентификатор страницы. Также к любой сохранённой странице можно получить доступ следующим образом:
- http://archive.is/2013/http://www.google.de/ — самый новый снимок в 2013 году.
- http://archive.is/201301/http://www.google.de/ — самый новый снимок в январе 2013.
- http://archive.is/20130101/http://www.google.de/ — самый новый снимок в течение дня 1 января 2013.
Дату можно продолжить далее, указав часы, минуты и секунды:
- http://archive.is/2013010103/http://www.google.de/
- http://archive.is/201301010313/http://www.google.de/
- http://archive.is/20130101031355/http://www.google.de/
Для улучшения читаемости, год, месяц, день, часы, минуты и секунды могут быть разделены точками, тире или двоеточиями:
- http://archive.is/2013-04-17/http://blog.bo.lt/
- http://archive.is/2013.04.17-12:08:20/http://blog.bo.lt/
Также возможно обратиться ко всем снимкам указанного URL:
http://archive.is/http://www.google.de/
Все сохранённые страницы домена:
http://archive.is/www.google.de
Все сохранённые страницы всех субдоменов
http://archive.is/*.google.de
Чтобы обратиться к самой последней версии страницы в архиве или к самой старой, поддерживаются адреса вида:
- http://archive.is/newest/http://reddit.com/
- http://archive.is/oldest/http://reddit.com/
Чтобы обратиться к определённой части длинной страницы имеется две опции:
В доменах поддерживаются национальные символы:
- http://archive.is/www.maroñas.com.uy
- http://archive.is/*.测试
Обратите внимание, что при создании архивной копии страницы архивируемому сайту отправляется IP адрес человека, создающего снимок страницы. Это делается через заголовок X-Forwarded-For для правильного определения вашего региона и показа соответствующего содержимого.
How to Use the Wayback Machine
There are two methods you can use to start archiving websites. Fortunately, both of them are super-easy and don’t require any special know-how. Start by placing your cursor in front of the URL in your browser’s address bar. Type and hit Enter. A dialog box should appear on your screen informing you that the Wayback Machine is saving the page.
The second way to archive a webpage is to use the Wayback Machine archive website. First, navigate to a webpage you want to save and copy the URL. With that done, head to the Wayback Machine archive website. On the right side of this page you will see a header that reads “Save Page Now.” Paste the URL of the webpage you want to save into the text box and click the “Save Page” button.
Regardless of which method you use, the result is the same. Be aware that saving the page can take a while, so be patient and let it do its thing.
Юридические проблемы с архивным контентом
Против Internet Archive было возбуждено несколько дел специально за его усилия по архивированию Wayback Machine.
Саентология
В конце 2002 года Интернет-архив удалил из Wayback Machine различные сайты, критикующие Саентологию . В сообщении об ошибке говорилось, что это было ответом на «запрос владельца сайта». Позже выяснилось, что юристы Церкви Саентологии требовали удаления, а владельцы сайта не хотели, чтобы их материалы были удалены.
Healthcare Advocates, Inc.
В 2003 году компания Harding Earley Follmer & Frailey защитила клиента от спора о товарном знаке с помощью Archive’s Wayback Machine. Адвокаты смогли продемонстрировать недействительность требований истца на основании содержания их веб-сайтов за несколько лет до этого. Истец, Healthcare Advocates, затем внес поправки в свою жалобу, включив в нее Интернет-архив, обвинив организацию в нарушении авторских прав, а также в нарушениях Закона США » Об авторском праве в цифровую эпоху» и Закона о компьютерном мошенничестве и злоупотреблениях . Healthcare Advocates утверждали, что, поскольку они установили файл robots.txt на своем веб-сайте, даже если после подачи первоначального иска Архив должен был удалить все предыдущие копии веб-сайта истца с Wayback Machine, однако некоторые материалы продолжали оставаться быть общедоступным на Wayback. Иск был урегулирован во внесудебном порядке после того, как Wayback устранил проблему.
Сюзанна Шелл
Активист Suzanne Shell подал иск в декабре 2005 года, потребовав Internet Archive платить 100000 $ HER США для архивирования ее сайта profane-justice.org в период между 1999 и 2004 Internet Archive подал декларативное суждение иска в окружном суде Соединенных Штатов для северного округа Калифорнии на 20 января 2006 г., добиваясь судебного определения, что Internet Archive не нарушает авторские права Shell . Shell ответила и подала встречный иск против Internet Archive за архивирование ее сайта, что, как она утверждает, нарушает ее условия обслуживания . 13 февраля 2007 г. судья Окружного суда США округа Колорадо отклонил все встречные иски, за исключением нарушения контракта . Интернет-архив не стал отказываться от претензий Shell о нарушении авторских прав, связанных с ее копировальной деятельностью, которая также будет продолжена.
25 апреля 2007 г. Internet Archive и Сюзанна Шелл совместно объявили об урегулировании своего иска. Интернет-архив заявил, что «… не заинтересован во включении в Wayback Machine материалов лиц, которые не желают архивировать свой веб-контент. Мы признаем, что г-жа Шелл имеет действующие и подлежащие исполнению авторские права на свой веб-сайт, и мы сожалеем. что включение ее веб-сайта в Wayback Machine привело к судебному разбирательству «. Shell заявила: «Я уважаю историческую ценность цели Internet Archive. Я никогда не собирался мешать достижению этой цели или причинять ей какой-либо вред».
Даниил Давыдюк
В период с 2013 по 2016 год порнографический актер по имени Даниэль Давыдюк пытался удалить свои заархивированные изображения из архива Wayback Machine, сначала отправив несколько запросов DMCA в архив, а затем обратившись в Федеральный суд Канады .
Архивы веб-страниц, постоянные
Если вы хотите сохранять текстовый контент, то для этих целей рекомендуются Pocket и Instapaper. Вы можете сохранять страницы через электронную почту, расширения для браузеров или через приложения. Эти сервисы извлекают текстовый контент из веб-страниц и делают его доступным на всех ваших устройствах. Но вы не можете загрузить сохраненные статьи, а только прочитать их на сайте Pocket или через мобильное приложение сервиса. Дальше мы расскажем, как полностью скопировать страницу сайта.
Evernote и OneNote — это инструменты для архивирования контента в подборки. Они предоставляют в распоряжение пользователей веб-клипперы (или расширения), которые позволяют легко сохранять полные веб-страницы в один клик.
Захваченные веб-страницы могут быть доступны с любого устройства, сохраняется оригинальный дизайн и возможность поиска по странице. Эти сервисы могут даже выполнять оптическое распознавание, чтобы найти текст на фотографиях. Evernote также позволяет экспортировать сохраненные страницы как HTML-файлы, которые можно загрузить в другом месте.
Если нужен быстрый и простой доступ к веб-страницам, то сохраняйте их в виде PDF-файлов. Перед тем, как скопировать страницу сайта в виде картинки, выберите правильный инструмент.
Google Chrome имеет встроенный PDF-конвертер. Также можно использовать Google Cloud Print. На сервис добавлен новый виртуальный принтер «Сохранить в Google Drive«. В следующий раз, когда вы будете печатать страницу на компьютере или мобильном устройстве через Cloud Print, вы сможете сохранить ее PDF-копию в Google Drive. Но это не лучший вариант сохранения страниц со сложным форматированием.
Когда важно сохранить дизайн, то лучше всего использовать скриншотер. Выбор подобных программ довольно велик, но я бы рекомендовал официальное дополнение Chrome от
Оно не только захватывает полные скриншоты веб-страниц, но также загружает полученное изображение на Google Drive. Дополнение может сохранять веб-страницы в формате веб-архива (MHT), который поддерживается в IE и Firefox.
Wayback Machine на Internet Archive — это идеальное место для поиска предыдущих версий веб-страницы. Но этот же инструмент можно использовать, чтобы скопировать страницу сайта и сохранить ее. Перейдите на archive.org/web и введите URL-адрес любой веб-страницы. Архиватор скачает на сервер ее полную копию, включая все изображения. Сервис создаст постоянный архив страницы, который выглядит так же, как оригинал. Он останется на сервере, даже если исходная страница была переведена в автономный режим.
Internet Archive не предоставляет возможности загрузки сохраненных страниц, но для этого можно использовать Archive.Is. Этот сервис очень похож на archive.org в том, что вы вводите URL-адрес страницы, и он создает на своем сервере точный ее снимок. Страница будет сохранена навсегда, но здесь есть возможность загрузить сохраненную страницу в виде ZIP-архива. Сервис также позволяет создавать архивы по дате. Благодаря чему вы можете получить несколько снимков одной и той же страницы для разных дат.
Все популярные браузеры предоставляют возможность загрузить полную версию веб-страницы на компьютер. Они загружают на ПК HTML страницы, а также связанные с ней изображения, CSS и JavaScript. Поэтому вы сможете прочитать ее позже в автономном режиме.
Теперь разберемся, как полностью скопировать страницу сайта на электронную читалку. Владельцы eReader могут использовать dotEPUB, чтобы загрузить любую веб-страницу в формате EPUB или MOBI. Данные форматы совместимы с большинством моделей электронных книг. Amazon также предлагает дополнение, с помощью которого можно сохранить любую веб-страницу на своем Kindle-устройстве, но этот инструмент в основном предназначен для архивирования текстового контента.
Большинство перечисленных инструментов позволяют загружать одну страницу, но если вы хотите сохранить набор URL-адресов, решением может стать Wget. Также существует Google Script для автоматической загрузки веб-страниц в Google Drive, но таким образом можно сохранить только HTML-контент.
Group 2: Software to make your own web archive
Online providers that allow you to create your own internet archive.
You may wonder why creating your own Wayback Machine alternative is necessary. After all, if the archive services listed above crawl the web and archive screenshots, code and other meaningful data, why would you need to create your own service?
Essentially it comes down to the value of the data being archived and the level of control you have over it. And while each of the above sites has its own benefits, each has its limitations too. If you want to monitor changes as your online presence evolves, having the facility to look back through screenshots, social media campaigns, data files (Media files, PDF’s, HTML etc.) at any particular time is clearly very useful.
Having access to your own archive means have more control, so you can be sure that your entire domain will be fully scraped at regular intervals. And if you use it to keep a record of someone else’s domain, you have the added benefit of not having to worry about take down requests: the Internet Archive does accept take down requests, so your competitor has the power to wipe out all the historic evidence on the Internet Archive.
But a more pressing concern perhaps is an increase in the need for companies to keep comprehensive records of social media and blog activity. Government departments and the financial sector are acutely aware of the need for such stringent record keeping – they’re required by law to meet a range of regulations. And the threat of litigation around the use, or misuse, of a company’s social media campaign reinforces the message that good record keeping is good practice.
Actively archiving your website – where your data is archived as updates are made – is a growth industry with a few high profile players leading the market. Essentially, you hand over the task of collecting and collating your data, they store it securely and you access it whenever you need to. Social media movements are captured in real time and should you require playback of video or audio, it’s all stored and playable just as it was on the day it was captured. Pagefreezer, Actiance and Socialware all offer archiving services that comply with the relevant regulations although they all vary in their level of provision.
Although it’s tempting to believe your company would never find itself taking legal action for copyright infringement against a competitor, or on the receiving end of a complaint or lawsuit because of an employee’s post on your company’s Facebook page, it has happened and continues to happen. A company’s need to access evidence to prosecute or defend is easily managed if all relevant data is archived.
Clearly, the nature of your business and sector will determine whether your company would benefit from this type of archiving service. It’s essential for some but merely desirable for others. Many online businesses view it as an insurance policy. And like the old insurance motto says: you never think you’ll need an insurance – until you do.
Which Sites Are Cataloged?
Many popular websites are automatically archived by the Wayback Machine. However, you can use the Wayback Machine to manually archive virtually any page. Websites are often abandoned or changed completely, so the Wayback machine acts as a way to preserve the culture of the Internet by keeping a digital “hard copy” of a website. Be aware that text and images are left intact; however, some outbound links and embedded items (e.g. videos) are not.
It is important to note that The Wayback Machine only scans and archives public sites. This means that password protected sites or ones located on private servers cannot be archived. In addition, if a website prohibits search engines from including it in search results, Wayback Machine will not be able to archive it.
Как избавиться от рекламы WAYBACK MACHINE в Chrome/Firefox/Internet Explorer/Edge?
Я на этом деле конечно уже собаку съел, так что трудностей не возникло. Но прежде, чем закидывать вас инструкциями, давайте повторим сами себе, с чем имеем дело.
Это обычный рекламный вирус, коих стало пруд пруди. И имен у него много: может быть просто WAYBACK MACHINE, а может с дописанной строкой после имени домена WAYBACK MACHINE. В любом случае вирус закидывает вас рекламой, и про ваше любимое казино Вулкан не забывает. До кучи он заражает и свойства ярлыков браузеров.
Кроме того, вирус обожает создавать расписания для запуска самого себя, чтоб жизнь медом не казалась. В результате его деятельности вы вполне можете случайно кликнуть на нежелательную ссылку и скачать себе что-нибудь более серьезное.
Поэтому данный рекламный вирус следует удалять как можно быстрее. Ниже я приведу инструкции по избавлению от вируса WAYBACK MACHINE, но рекомендую использовать автоматизированный вариант.