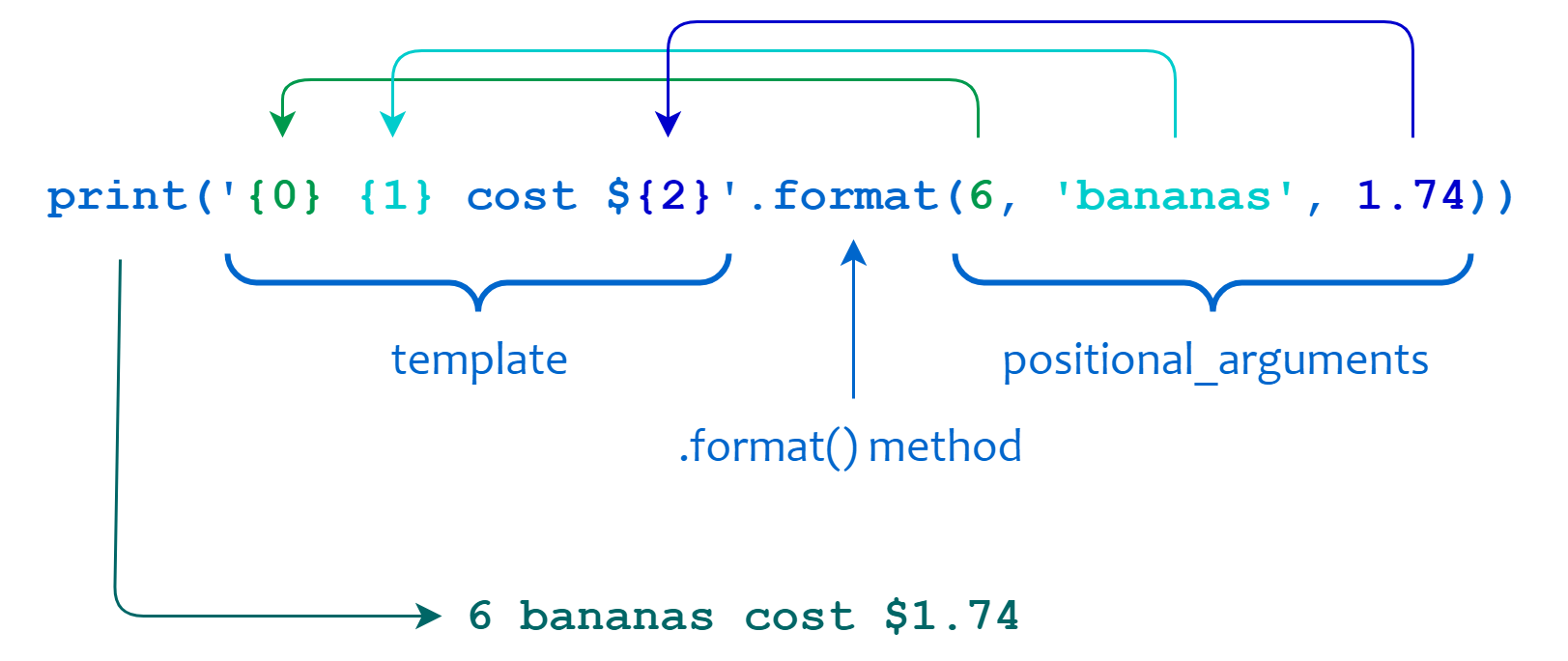
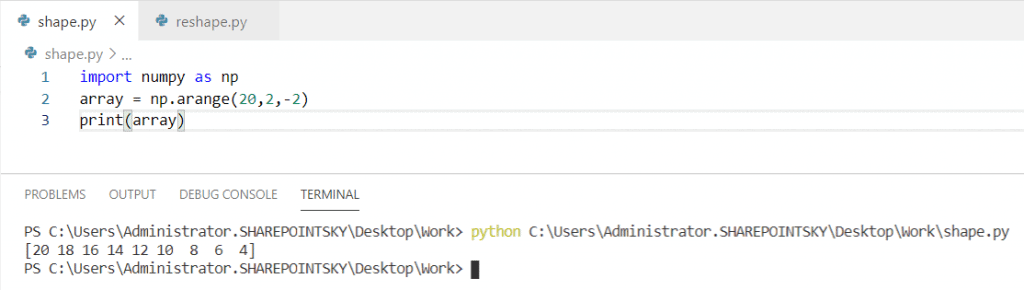
Многопоточность в python
Содержание:
- 17.1.4. RLock Objects¶
- Улучшения в производительности
- Thread Objects¶
- Изменения синтаксиса псевдонима типа
- Freezing a GUI With Long-Running Tasks
- Let’s start with Queuing in Python.
- Сопоставление шаблонов
- Daemon vs. Non-Daemon Threads¶
- Timer Threads¶
- Практическая реализация
- Блокировки (замки)
- Determining the Current Thread¶
- A consumer-producer script
- Synchronizing Threads
- RLock Objects¶
- Объект Event
- 17.1.3. Lock Objects¶
- Subclassing Thread
- Задачи с ограничением скорости вычислений и ввода-вывода
17.1.4. RLock Objects¶
A reentrant lock is a synchronization primitive that may be acquired multiple
times by the same thread. Internally, it uses the concepts of “owning thread”
and “recursion level” in addition to the locked/unlocked state used by primitive
locks. In the locked state, some thread owns the lock; in the unlocked state,
no thread owns it.
To lock the lock, a thread calls its method; this
returns once the thread owns the lock. To unlock the lock, a thread calls
its method. /
call pairs may be nested; only the final (the
of the outermost pair) resets the lock to unlocked and
allows another thread blocked in to proceed.
Reentrant locks also support the .
Улучшения в производительности
Как и во всех последних релизах Python, с Python 3.10 придут улучшения производительности. Первое — оптимизация конструкторов str(), bytes() и bytearray(), которые должны стать примерно на 30% быстрее (фрагмент, адаптированный из примера в баг-трекере Python):
Другой более заметной оптимизацией (если вы используете аннотации типов) является то, что параметры функции и их аннотации вычисляются уже не во время исполнения, а во время компиляции. Теперь функция с аннотациями параметров создаётся примерно в два раза быстрее.
Кроме того, есть еще несколько оптимизаций в разных частях ядра языка. Подробности о них вы можете найти в этих записях баг-трекера Python: bpo-41718, bpo-42927 и bpo-43452.
Thread Objects¶
The class represents an activity that is run in a separate
thread of control. There are two ways to specify the activity: by passing a
callable object to the constructor, or by overriding the
method in a subclass. No other methods (except for the constructor) should be
overridden in a subclass. In other words, only override the
and methods of this class.
Once a thread object is created, its activity must be started by calling the
thread’s method. This invokes the
method in a separate thread of control.
Once the thread’s activity is started, the thread is considered ‘alive’. It
stops being alive when its method terminates – either
normally, or by raising an unhandled exception. The
method tests whether the thread is alive.
Other threads can call a thread’s method. This blocks
the calling thread until the thread whose method is
called is terminated.
A thread has a name. The name can be passed to the constructor, and read or
changed through the attribute.
If the method raises an exception,
is called to handle it. By default,
ignores silently .
A thread can be flagged as a “daemon thread”. The significance of this flag is
that the entire Python program exits when only daemon threads are left. The
initial value is inherited from the creating thread. The flag can be set
through the property or the daemon constructor
argument.
Note
Daemon threads are abruptly stopped at shutdown. Their resources (such
as open files, database transactions, etc.) may not be released properly.
If you want your threads to stop gracefully, make them non-daemonic and
use a suitable signalling mechanism such as an .
There is a “main thread” object; this corresponds to the initial thread of
control in the Python program. It is not a daemon thread.
There is the possibility that “dummy thread objects” are created. These are
thread objects corresponding to “alien threads”, which are threads of control
started outside the threading module, such as directly from C code. Dummy
thread objects have limited functionality; they are always considered alive and
daemonic, and cannot be ed. They are never deleted,
since it is impossible to detect the termination of alien threads.
Изменения синтаксиса псевдонима типа
В более ранних версиях Python добавлены псевдонимы типов, позволяющие создавать синонимы пользовательских классов. В Python 3.9 и более ранних версиях псевдонимы записывались так:
Здесь FileName — псевдоним базового типа строки Python. Однако, начиная с Python 3.10, синтаксис определения псевдонимов типов будет изменён:
Благодаря этому простому изменению и программистам, и инструментам проверки типа проще отличить присваивание переменной от псевдонима. Новый синтаксис обратно совместим, так что вам не нужно обновлять старый код с псевдонимами.
Кроме этих 2 изменений появилось другое улучшение модуля typing — в предложениях по улучшению номер 612 оно называется Parameter Specification Variables. Однако это не то, что вы найдете в основной массе кода на Python, поскольку эта функциональность используется для пересылки параметра типов от одного вызываемого типа к другому вызываемому типу, например, в декораторах. Если вам есть где применить эту функциональность, посмотрите её PEP.
Freezing a GUI With Long-Running Tasks
Long-running tasks occupying the main thread of a GUI application and causing the application to freeze is a common issue in GUI programming that almost always results in a bad user experience. For example, consider the following GUI application:
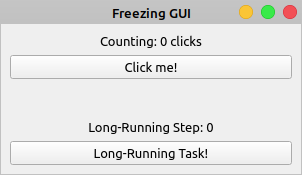
Say you need the Counting label to reflect the total number of clicks on the Click me! button. Clicking the Long-Running Task! button will launch a task that takes a lot of time to finish. Your long-running task could be a file download, a query to a large database, or any other resource-intensive operation.
Here’s a first approach to coding this application using PyQt and a single thread of execution:
In this Freezing GUI application, creates all the required graphical components for the GUI. A click on the Click me! button calls , which makes the text of the Counting label reflect the number of button clicks.
Note: PyQt was first developed to target Python 2, which has an keyword. To avoid a name conflict on those earlier versions of PyQt, an underscore was added to the end of .
Even though PyQt5 targets only Python 3, which doesn’t have an keyword, the library provides two methods to start an application’s event loop:
Both variations of the method work the same, so you can use either one in your applications.
Clicking the Long-Running Task! button calls , which performs a task that takes seconds to complete. This is a hypothetical task that you coded using , which suspends the execution of the calling thread for the given number of seconds, .
In , you also call to make the Long-Running Step label reflect the progress of the operation.
Does this application work as you intend? Run the application and check out its behavior:
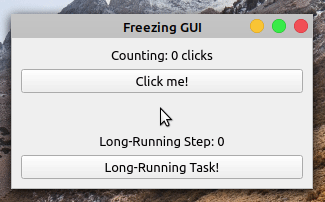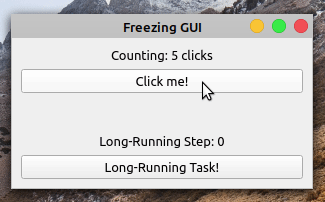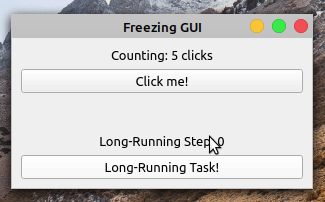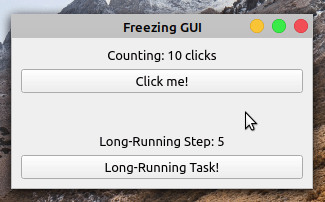
When you click the Click me! button, the label shows the number of clicks. However, if you click the Long-Running Task! button, then the application becomes frozen and unresponsive. The buttons no longer respond to clicks and the labels don’t reflect the application’s state.
After five seconds, the application’s GUI gets updated again. The Counting label shows ten clicks, reflecting five clicks that occurred while the GUI was frozen. The Long-Running Step label doesn’t reflect the progress of your long-running operation. It jumps from zero to five without showing the intermediate steps.
Note: Even though your application’s GUI freezes during the long-running task, the application still registers events such as clicks and keystrokes. It’s just unable to process them until the main thread gets released.
The application’s GUI freezes as a result of a blocked main thread. The main thread is busy processing a long-running task and doesn’t immediately respond to the user’s actions. This is an annoying behavior because the user doesn’t know for sure if the application is working correctly or if it’s crashed.
Fortunately, there are some techniques you can use to work around this issue. A commonly used solution is to run your long-running task outside of the application’s main thread using a worker thread.
Let’s start with Queuing in Python.
Before you do anything else, import Queue.
from Queue import Queue
A queue is kind of like a list:
my_list = [] my_list.append(1) my_list.append(2) my_list.append(3) print my_list.pop(0) # Outputs: 1
The above code creates a list, assigns it three values, then removes the first value in so the list now has only 2 values (which are 2 and 3).
There are only a couple differences in how queues work visually. First we set a maximum size to the queue, where 0 means infinite. It’s pretty dumb but I’m sure it’s useful somehow.
The second visual difference is the task_done() bit at the end. That tells the queue that not only have I retrieved the information from the list, but I’ve finished with it. If I don’t call task_done() then I run into trouble in threading. So let’s just say in Queues, you have to call this.
The big important point about Queues is that they work really well with threading. In fact, you just can’t use lists the way you can use queues in threading. That’s why I’m even bothering to bring them up here.
Here’s an example of a simple program that uses Queues:
It outputs 0-19. In like the most complicated way possible to output 0-19.
Notice how do_stuff() is just whipping through the whole queue. That’s nice. But what if it was trying to do a big task, or a task that required a lot of waiting (like pulling data from APIs)? Assume for example that do_stuff() takes 30 second to run each time and it’s just waiting on stupid APIs to return something. The function would take 30 seconds every time it ran, and it would run 20 times so it would take 10 minutes to get through just 20 items. That’s really shitty.
Сопоставление шаблонов
Одна масштабная фича, о которой вы, конечно, слышали, — это структурное сопоставление шаблонов, добавляющее оператор известное выражение case из других языков. Мы знаем, как работать с case, но посмотрите на вариацию в Python это не просто switch/case, но также несколько мощных особенностей, которые мы должны исследовать.
Простое сопоставление шаблонов состоит из ключевого слова match, за которым следует выражение, а его результат проверяется на соответствие шаблонам, указанным в последовательных операторах case:
В этом простом примере мы воспользовались переменной day как выражением, которое затем сравнивается с конкретными строками в case. Кроме строк, вы также можете заметить case с маской _ — это эквивалент ключевого слова default в других языках. Хотя этот оператор можно опустить, в этом случае может произойти no-op, по существу это означает, что вернётся None.
Еще один момент, на который стоит обратить внимание в коде выше, это оператор |, позволяющий комбинировать несколько литералов | (другой его вариант — or). Как я уже упоминал, новое сопоставление шаблонов не заканчивается на базовом синтаксисе, напротив — оно привносит дополнительные возможности, например сопоставление сложных шаблонов:
Как я уже упоминал, новое сопоставление шаблонов не заканчивается на базовом синтаксисе, напротив — оно привносит дополнительные возможности, например сопоставление сложных шаблонов:
Во фрагменте выше мы воспользовались кортежем как выражением сопоставления. Однако мы не ограничены кортежами: работать будет любой итерируемый тип. Также выше видно, что маска (wildcard) _ может применяться внутри сложных шаблонов и не только сама по себе, как в предыдущих примерах. Простые кортежи или списки — не всегда лучший подход, поэтому, если вы предпочитаете классы, код можно переписать так:
Здесь видно, что с шаблонами, написанными в стиле конструкторов, можно сопоставить атрибуты класса. При использовании этого подхода отдельные атрибуты также попадают в переменные (как и в показанные ранее кортежи), с которыми затем можно работать в соответствующем операторе case.
Выше мы можем увидеть другие особенности сопоставления шаблонов: во-первых выражение в case — это гард, который также является условием в if. Это полезно, когда сопоставления по значению не достаточно и вам нужны дополнительные проверки. Посмотрите на оставшееся выражение case: видно, что и ключевые слова, (name-name) и позиционные аргументы работают с синтаксисом, похожим на синтаксис конструкторов; то же самое верно для маски _ (или отбрасываемой переменной).
Сопоставление шаблонов также позволяет работать с вложенными шаблонами. Вложенные шаблоны могут использовать любой итерируемый тип: и конструируемый объект, и несколько таких объектов, которые возможно итерировать:
В таких сложных шаблонах для дальнейшей обработки может быть полезно записать подшаблон в переменную. Это можно сделать с помощью ключевого слова as, как показано выше, во втором case.
Daemon vs. Non-Daemon Threads¶
Up to this point, the example programs have implicitly waited to exit
until all threads have completed their work. Sometimes programs spawn
a thread as a daemon that runs without blocking the main program
from exiting. Using daemon threads is useful for services where there
may not be an easy way to interrupt the thread, or where letting the
thread die in the middle of its work does not lose or corrupt data
(for example, a thread that generates “heart beats” for a service
monitoring tool). To mark a thread as a daemon, pass
when constructing it or call its method with
. The default is for threads to not be daemons.
threading_daemon.py
import threading
import time
import logging
def daemon():
logging.debug('Starting')
time.sleep(0.2)
logging.debug('Exiting')
def non_daemon():
logging.debug('Starting')
logging.debug('Exiting')
logging.basicConfig(
level=logging.DEBUG,
format='(%(threadName)-10s) %(message)s',
)
d = threading.Thread(name='daemon', target=daemon, daemon=True)
t = threading.Thread(name='non-daemon', target=non_daemon)
d.start()
t.start()
The output does not include the message from the daemon
thread, since all of the non-daemon threads (including the main
thread) exit before the daemon thread wakes up from the
call.
$ python3 threading_daemon.py (daemon ) Starting (non-daemon) Starting (non-daemon) Exiting
To wait until a daemon thread has completed its work, use the
method.
threading_daemon_join.py
import threading
import time
import logging
def daemon():
logging.debug('Starting')
time.sleep(0.2)
logging.debug('Exiting')
def non_daemon():
logging.debug('Starting')
logging.debug('Exiting')
logging.basicConfig(
level=logging.DEBUG,
format='(%(threadName)-10s) %(message)s',
)
d = threading.Thread(name='daemon', target=daemon, daemon=True)
t = threading.Thread(name='non-daemon', target=non_daemon)
d.start()
t.start()
d.join()
t.join()
Waiting for the daemon thread to exit using means it
has a chance to produce its message.
$ python3 threading_daemon_join.py (daemon ) Starting (non-daemon) Starting (non-daemon) Exiting (daemon ) Exiting
By default, blocks indefinitely. It is also possible to
pass a float value representing the number of seconds to wait for the
thread to become inactive. If the thread does not complete within the
timeout period, returns anyway.
threading_daemon_join_timeout.py
import threading
import time
import logging
def daemon():
logging.debug('Starting')
time.sleep(0.2)
logging.debug('Exiting')
def non_daemon():
logging.debug('Starting')
logging.debug('Exiting')
logging.basicConfig(
level=logging.DEBUG,
format='(%(threadName)-10s) %(message)s',
)
d = threading.Thread(name='daemon', target=daemon, daemon=True)
t = threading.Thread(name='non-daemon', target=non_daemon)
d.start()
t.start()
d.join(0.1)
print('d.isAlive()', d.isAlive())
t.join()
Since the timeout passed is less than the amount of time the daemon
thread sleeps, the thread is still “alive” after
returns.
Timer Threads¶
One example of a reason to subclass is provided by
, also included in . A
starts its work after a delay, and can be canceled at any point within
that delay time period.
threading_timer.py
import threading
import time
import logging
def delayed():
logging.debug('worker running')
logging.basicConfig(
level=logging.DEBUG,
format='(%(threadName)-10s) %(message)s',
)
t1 = threading.Timer(0.3, delayed)
t1.setName('t1')
t2 = threading.Timer(0.3, delayed)
t2.setName('t2')
logging.debug('starting timers')
t1.start()
t2.start()
logging.debug('waiting before canceling %s', t2.getName())
time.sleep(0.2)
logging.debug('canceling %s', t2.getName())
t2.cancel()
logging.debug('done')
The second timer in this example is never run, and the first timer
appears to run after the rest of the main program is done. Since it is
not a daemon thread, it is joined implicitly when the main thread is
done.
Практическая реализация
В этих примерах на Python будет использоваться модуль потоковой передачи, который является частью стандартной библиотеки.
import threading
Чтобы проиллюстрировать мощь потоков, давайте сначала создадим два потока, A и B.
Мы заставим поток A выполнить короткое вычисление, в то время как поток B будет пытаться отслеживать общий ресурс.
Если для этого ресурса установлено значение , мы заставим поток B предупреждать пользователя о статусе.
import threading
import time
# Set the resource to False initially
shared_resource = False
# A lock for the shared resource
lock = threading.Lock()
def perform_computation():
# Thread A will call this function and manipulate the resource
print(f'Thread {threading.currentThread().name} - performing some computation....')
shared_resource = True
print(f'Thread {threading.currentThread().name} - set shared_resource to True!')
print(f'Thread {threading.currentThread().name} - Finished!')
time.sleep(1)
def monitor_resource():
# Thread B will monitor the shared resource
while shared_resource == False:
time.sleep(1)
print(f'Thread {threading.currentThread().name} - Detected shared_resource = False')
time.sleep(1)
print(f'Thread {threading.currentThread().name} - Finished!')
if __name__ == '__main__':
a = threading.Thread(target=perform_computation, name='A')
b = threading.Thread(target=monitor_resource, name='B')
# Now start both threads
a.start()
b.start()
Здесь поток A установит в , а поток B будет ждать, пока этот ресурс не станет True.
Выход
Thread A - performing some computation.... Thread A - set shared_resource to True! Thread A - Finished! Thread B - Detected shared_resource = False Thread B - Finished!
Теперь давайте сделаем поток B потоком демона. Посмотрим, что теперь будет. Для этого мы можем установить его как параметр в методе .
import threading
import time
shared_resource = False # Set the resource to False initially
lock = threading.Lock() # A lock for the shared resource
def perform_computation():
# Thread A will call this function and manipulate the resource
print(f'Thread {threading.currentThread().name} - performing some computation....')
shared_resource = True
print(f'Thread {threading.currentThread().name} - set shared_resource to True!')
print(f'Thread {threading.currentThread().name} - Finished!')
time.sleep(1)
def monitor_resource():
# Thread B will monitor the shared resource
while shared_resource == False:
time.sleep(1)
print(f'Daemon Thread {threading.currentThread().name} - Detected shared_resource = False')
time.sleep(1)
print(f'Daemon Thread {threading.currentThread().name} - Finished!')
if __name__ == '__main__':
a = threading.Thread(target=perform_computation, name='A')
b = threading.Thread(target=monitor_resource, name='B', daemon=True) # Make thread B as a daemon thread
# Now start both threads
a.start()
b.start()
Выход
Thread A - performing some computation.... Thread A - set shared_resource to True! Thread A - Finished! Daemon Thread B - Detected shared_resource = False
Обратите внимание, что Daemon Thread не завершается. Это потому, что он будет автоматически убит основным потоком
Неблокирующая природа потоков делает их очень полезными для многих приложений Python.
Блокировки (замки)
Блокировки – это фундаментальный механизм синхронизации, который предоставлен модулем threading Python. Замок может удерживаться одним потоком в любое время, или без потока вообще. Если поток попытается удержать один замок, который уже удерживается другим потоком, выполнение первого потока будет остановлена, пока не будет снята блокировка. Замки обычно используются для синхронизации доступа к общим ресурсам. Для каждого такого источника создается объект Lock. Когда вам нужно получить доступ к ресурсу, вызовите acquire для того, чтобы поставить блок, после чего вызовете release:
Python
lock = Lock()
lock.acquire() # Выполнит блокировку данного участка кода
… доступ к общим ресурсам
lock.release()
|
1 2 3 4 5 |
lock=Lock() lock.acquire()# Выполнит блокировку данного участка кода …доступкобщимресурсам lock.release() |
Для корректной работы важно снять блок, даже если что-то идет не так при доступе к ресурсу. Вы можете использовать try-finally для этой цели:. Python
lock.acquire()
try:
..
доступ к общим ресурсам
finally:
lock.release() # освобождаем блокировку независимо от результата
Python
lock.acquire()
try:
… доступ к общим ресурсам
finally:
lock.release() # освобождаем блокировку независимо от результата
|
1 2 3 4 5 |
lock.acquire() try …доступкобщимресурсам finally lock.release()# освобождаем блокировку независимо от результата |
В Python 2.5 и в поздних версиях, вы можете также использовать оператор with. В работе с блоком, данный оператор автоматически получает доступ к замку перед входом в блок, и отпускает его после выхода из блока:
Python
from __future__ import with_statement # 2.5 версия!!!
with lock:
… доступ к общим ресурсам
|
1 2 3 4 |
from__future__importwith_statement# 2.5 версия!!! withlock …доступкобщимресурсам |
Метод acquire принимает опциональный флаг ожидания, который может быть использоваться для того, чтобы обойти блокировку, если замок удерживается той или иной частью кода. Если вы укажите False, то метод не будет блокироваться, но вернет False, если замок уже висит:
Python
if not lock.acquire(False):
… не удалось заблокировать ресурс
else:
try:
… доступ к ресурсам
finally:
lock.release()
|
1 2 3 4 5 6 7 |
ifnotlock.acquire(False) …неудалосьзаблокироватьресурс else try …доступкресурсам finally lock.release() |
Вы можете использовать метод locked, чтобы проверить, работает ли замок
Обратите внимание на то, что вы не можете использовать этот метод, чтобы определить, блокируется вызов к acquire или нет. Какой-либо другой поток может получить доступ к замку между вызовом метода и следующим оператором
Python
if not lock.locked():
# Другой поток может выполниться прежде чем
# мы выполним следующею строку
lock.acquire() # может заблокировать все равно
|
1 2 3 4 |
ifnotlock.locked() # Другой поток может выполниться прежде чем # мы выполним следующею строку lock.acquire()# может заблокировать все равно |
Determining the Current Thread¶
Using arguments to identify or name the thread is cumbersome, and
unnecessary. Each Thread instance has a name with a default
value that can be changed as the thread is created. Naming threads is
useful in server processes with multiple service threads handling
different operations.
import threading
import time
def worker():
print threading.currentThread().getName(), 'Starting'
time.sleep(2)
print threading.currentThread().getName(), 'Exiting'
def my_service():
print threading.currentThread().getName(), 'Starting'
time.sleep(3)
print threading.currentThread().getName(), 'Exiting'
t = threading.Thread(name='my_service', target=my_service)
w = threading.Thread(name='worker', target=worker)
w2 = threading.Thread(target=worker) # use default name
w.start()
w2.start()
t.start()
The debug output includes the name of the current thread on each
line. The lines with "Thread-1" in the thread name column
correspond to the unnamed thread w2.
$ python -u threading_names.py worker Thread-1 Starting my_service Starting Starting Thread-1worker Exiting Exiting my_service Exiting
Most programs do not use print to debug. The
module supports embedding the thread name in every log
message using the formatter code %(threadName)s. Including thread
names in log messages makes it easier to trace those messages back to
their source.
import logging
import threading
import time
logging.basicConfig(level=logging.DEBUG,
format=' (%(threadName)-10s) %(message)s',
)
def worker():
logging.debug('Starting')
time.sleep(2)
logging.debug('Exiting')
def my_service():
logging.debug('Starting')
time.sleep(3)
logging.debug('Exiting')
t = threading.Thread(name='my_service', target=my_service)
w = threading.Thread(name='worker', target=worker)
w2 = threading.Thread(target=worker) # use default name
w.start()
w2.start()
t.start()
is also thread-safe, so messages from different threads
are kept distinct in the output.
A consumer-producer script
The whole code
import threading
import time
import queue
import random
import string
def consumer(id, size, in_q):
count = 0
while True:
log_msg = in_q.get()
if log_msg is None:
break
print("{0}%\t{1}".format(round(count/size*100,2), log_msg))
count += 1
print("Consumer #{0} shutting down".format(id))
def producer(id, in_q, out_q):
while True:
item = in_q.get()
if item is None:
out_q.put(None)
break
out_q.put("#{0}\tThis string is long {1} characters".format(id, len(item)))
print("Producer #{0} shutting down".format(id))
string_q = queue.Queue()
log_q = queue.Queue()
n_of_strings = 200000
for i in range(n_of_strings):
string_q.put(''.join(random.choices(string.ascii_uppercase + string.digits, k=random.randint(0, 150))))
start = time.time()
producers = []
n_of_producers = 2
logger = threading.Thread(target=consumer, args=(0, n_of_strings, log_q,))
logger.start()
for thid in range(n_of_producers):
producers.append(threading.Thread(target=producer, args=(thid, string_q, log_q)))
producers.start()
string_q.put(None)
for thread in producers:
thread.join()
logger.join()
print("It took " + str(time.time()-start) + " seconds")
A quick explanation
In this script, the producer function consumes a queue containing strings and finds the length of each. It then puts a log of each result into another queue, which the consumer then accesses. Since the number of strings is fixed, the consumer can calculate the percentage over the total.
We used the and libraries to generate random strings, on-line 31. However, this is not important for our python threading tutorial. Instead, just see that when the producer finishes, it also tells the consumer that it has finished by adding a item (sentinel) to the output queue.
This script may require some clarification. It performs calculation over calculation and doesn’t do waiting like the scripts we used before. Since the threads of the same process are bound to the same core in the PC, adding more threads won’t increase performance because the limiting factor is the CPU itself, not a waiting the script must do.
Synchronizing Threads
The threading module provided with Python includes a simple-to-implement locking mechanism that allows you to synchronize threads. A new lock is created by calling the Lock() method, which returns the new lock.
The acquire(blocking) method of the new lock object is used to force threads to run synchronously. The optional blocking parameter enables you to control whether the thread waits to acquire the lock.
If blocking is set to 0, the thread returns immediately with a 0 value if the lock cannot be acquired and with a 1 if the lock was acquired. If blocking is set to 1, the thread blocks and wait for the lock to be released.
The release() method of the new lock object is used to release the lock when it is no longer required.
Example
#!/usr/bin/python
import threading
import time
class myThread (threading.Thread):
def __init__(self, threadID, name, counter):
threading.Thread.__init__(self)
self.threadID = threadID
self.name = name
self.counter = counter
def run(self):
print "Starting " + self.name
# Get lock to synchronize threads
threadLock.acquire()
print_time(self.name, self.counter, 3)
# Free lock to release next thread
threadLock.release()
def print_time(threadName, delay, counter):
while counter:
time.sleep(delay)
print "%s: %s" % (threadName, time.ctime(time.time()))
counter -= 1
threadLock = threading.Lock()
threads = []
# Create new threads
thread1 = myThread(1, "Thread-1", 1)
thread2 = myThread(2, "Thread-2", 2)
# Start new Threads
thread1.start()
thread2.start()
# Add threads to thread list
threads.append(thread1)
threads.append(thread2)
# Wait for all threads to complete
for t in threads:
t.join()
print "Exiting Main Thread"
When the above code is executed, it produces the following result −
Starting Thread-1 Starting Thread-2 Thread-1: Thu Mar 21 09:11:28 2013 Thread-1: Thu Mar 21 09:11:29 2013 Thread-1: Thu Mar 21 09:11:30 2013 Thread-2: Thu Mar 21 09:11:32 2013 Thread-2: Thu Mar 21 09:11:34 2013 Thread-2: Thu Mar 21 09:11:36 2013 Exiting Main Thread
RLock Objects¶
A reentrant lock is a synchronization primitive that may be acquired multiple
times by the same thread. Internally, it uses the concepts of “owning thread”
and “recursion level” in addition to the locked/unlocked state used by primitive
locks. In the locked state, some thread owns the lock; in the unlocked state,
no thread owns it.
To lock the lock, a thread calls its method; this
returns once the thread owns the lock. To unlock the lock, a thread calls
its method. /
call pairs may be nested; only the final (the
of the outermost pair) resets the lock to unlocked and
allows another thread blocked in to proceed.
Reentrant locks also support the .
Объект Event
Объект event – это простой объект синхронизации. Он представляет собой внутренний флаг, так что все потоки могут ожидать, пока флаг будет установлен, задавать, или убирать его.
Python
import threading
event = threading.Event()
# поток-клиент ожидает установки флага
event.wait()
# поток-сервер может установить флаг или снять его.
event.set()
event.clear()
|
1 2 3 4 5 6 7 8 9 10 |
importthreading event=threading.Event() event.wait() event.set() event.clear() |
Если флаг был задан, метод wait не будет делать ничего. Если флаг был убран, wait будет блокировать, пока его снова не установят. Любое количество потоков может дожидаться одного и того же объекта event.
17.1.3. Lock Objects¶
A primitive lock is a synchronization primitive that is not owned by a
particular thread when locked. In Python, it is currently the lowest level
synchronization primitive available, implemented directly by the
extension module.
A primitive lock is in one of two states, “locked” or “unlocked”. It is created
in the unlocked state. It has two basic methods, and
. When the state is unlocked,
changes the state to locked and returns immediately. When the state is locked,
blocks until a call to in another
thread changes it to unlocked, then the call resets it
to locked and returns. The method should only be
called in the locked state; it changes the state to unlocked and returns
immediately. If an attempt is made to release an unlocked lock, a
will be raised.
Locks also support the .
When more than one thread is blocked in waiting for the
state to turn to unlocked, only one thread proceeds when a
call resets the state to unlocked; which one of the waiting threads proceeds
is not defined, and may vary across implementations.
All methods are executed atomically.
Subclassing Thread
It is also possible to start a thread by subclassing threading.Thread. Depending on the design of your application, you may prefer this approach. Here, you extend threading.Thread and provide the implementation of your task in the run() method.
import threading
import random, time
class MyTask(threading.Thread):
def __init__(self, sleepFor):
self.secs = sleepFor
threading.Thread.__init__(self)
def run(self):
print self, 'begin sleep(', self.secs, ')'
time.sleep(self.secs)
print self, 'end sleep(', self.secs, ')'
And here is the usage of the class defined above.
tasks = []
for x in xrange(0, 5):
t = MyTask(random.randint(1, 10))
tasks.append(t)
t.start()
print 'joining ..'
while threading.active_count() > 1:
for t in tasks:
t.join()
print t, 'is done.'
print 'all done.'
Задачи с ограничением скорости вычислений и ввода-вывода
Время выполнения задач, ограниченных скоростью вычислений, полностью зависит от производительности процессора, тогда как в задачах I/O Bound скорость выполнения процесса ограничена скоростью системы ввода-вывода.
В задачах с ограничением скорости вычислений программа расходует большую часть времени на использование центрального процессора, то есть на выполнение вычислений. К таким задачам можно отнести программы, занимающиеся исключительно перемалыванием чисел и проведением расчётов.
В задачах, ограниченных скоростью ввода-вывода, программы обрабатывают большие объёмы данных с диска в сравнении с необходимым объёмом вычислений. К таким задачам можно отнести, например, подсчёт количества строк в файле.