Lsi слова и копирайтинг: полная инструкция как найти и использовать
Содержание:
- С чего все начиналось
- Инструменты и сервисы для LSI-копирайтинга
- [править] Основные задачи, факторы и функции LSI-копирайтинга
- Что собой представляет LSI-копирайтинг
- Чем отличается SEO от LSI
- Принцип работы LSI
- Определение LSI-копирайтинга
- Основные правила SEO-текстов в 2021 году
- Пишем Текст статьи
- Создание структуры
- Мета-теги для страниц на сайте
- Отличие LSI от SEO-копирайтинга
С чего все начиналось
В 2011 Google запустил известный алгоритм «Панда», который научился распознавать переспам в тексте, а также выявлял некачественный контент. В 2012 году появились первые пробные методики работы с LSI текстами. Ранее для успешного продвижения достаточно было заспамить текст продвигаемой страницы ключами, причем, разместить большинство из них в первых абзацах.
С выходом нового алгоритма Google поставил перед сеошниками иную задачу – добиться естественности текста и повысить качество контента.
В 2013 году после запуска алгоритма Колибри контент стал оцениваться по релевантности и соответствию запросам пользователей. Колибри научился захватывать LSI-ядро и определять тематику текста.
К примеру, ключи «мёд» и «мед» (сокращенно от «медицинский»). Раньше поисковику было сложно объяснить, чем отличаются две страницы, так как в русском языке практически утеряна буква Ё. Теперь, воспринимая тематикозадающие слова LSI, к примеру «пчелы» или, соответственно, «доктор», поисковик без труда отнесет каждую страницу к своей тематике.
Поисковые системы настолько усовершенствовали свои механизмы, что в качестве ядра-окружения воспринимают даже слова разговорной речи. Если вы введете в поисковую строку Google «купить винт ПК», он предложит вам и жесткий диск, и крепежи для корпуса системника.
Инструменты и сервисы для LSI-копирайтинга
Подбирать такие фразы вручную довольно долго. Мы попробовали несколько сервисов, которые предлагают подобрать SEO и LSI-ключевики, чтобы дело шло быстрее.
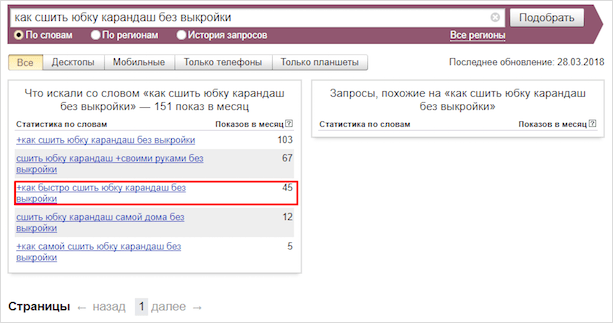
Getdirect
Сайт с подбором слов, похожий на Google или Яндекс.Вордстат. Выводит количество показов в месяц и что еще искали люди, которые вводили запрос. Регистрации не требует, капчу не выводит. Удобен как замена Вордстату без капчи.
 Панель Getdirect
Панель Getdirect
Lsigraph
Англоязычный сервис для подбора LSI-ключей. Вписываешь ключевик, сервис выводит список запросов, подходящих по теме. Регистрация не требуется.
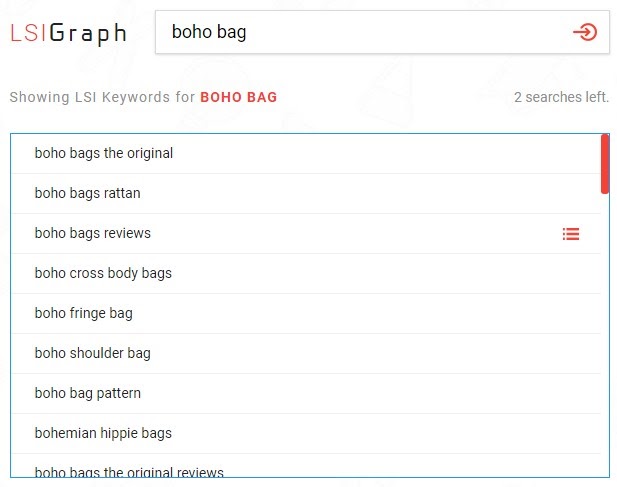 Вывод LSI-ключей
Вывод LSI-ключей
Парсинг подсветок Yandex и сбор тематических слов
Сервис анализирует топ-50 Яндекса, выдает подсветки — то, что выделено жирным в поисковой системе, и дополнительные слова, задающие тематику — те самые LSI-ключи.
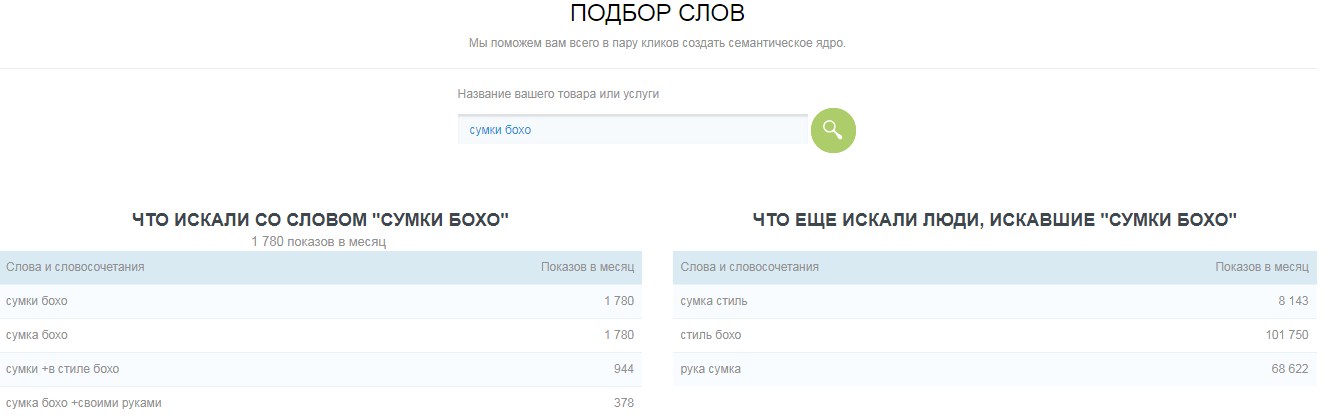
 LSI-ключи, которые сервис нашел для запроса «сумки бохо»
LSI-ключи, которые сервис нашел для запроса «сумки бохо»
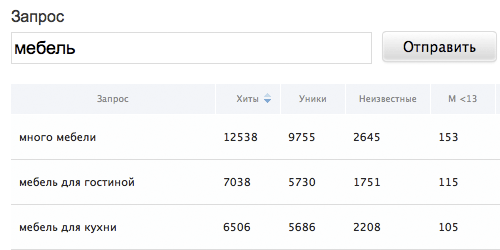
Адвего
С помощью этого сервиса можно смотреть, какие ключевики использовали успешные конкуренты, чьи статьи вышли в топ.
 Анализ статьи сервисом
Анализ статьи сервисом
Анализ контента
Инструмент поможет доработать свой материал, к примеру. оптимизировать метатеги и ускорить загрузку страницы, а еще проанализировать конкурентов из топа. Сервис выведет ключевики, посчитает релевантность каждого ключа и метатегов, а еще оценит технические характеристики: скорость загрузки сайта, вес страницы и прочее.
 Анализ ключей сервисом «Анализ контента»
Анализ ключей сервисом «Анализ контента»
Анализатор текста
Позволяет смотреть, какие ключи используют конкуренты, указывает частотность слов в тексте.
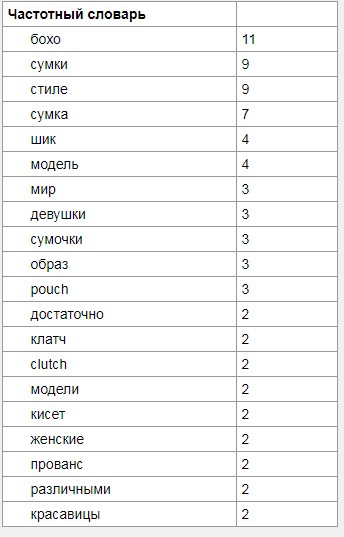 Вывод слов после анализа сайта
Вывод слов после анализа сайта
MegaIndex
Инструмент на основе топ-10 выдачи ищет наиболее употребляемые ключевики по заданной теме. Выводит только ключи из одного слова, считает релевантность.
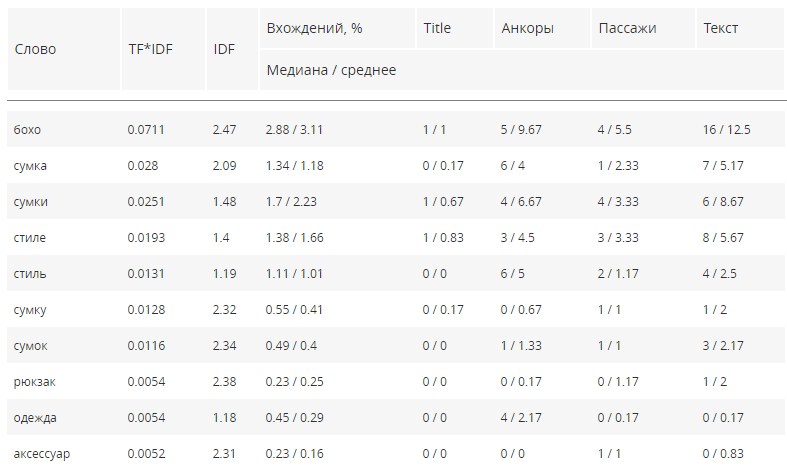 Ключевики с рассчитанными показателями
Ключевики с рассчитанными показателями
ЛеммаТоп
Сервис должен находить слова и словосочетания, которые часто используются в списке адресов, которые вы забьете в сервис. Можно было бы посмотреть, какие слова используют в своих статьях конкуренты или проверить отзывы на продукт и увидеть, что волнует покупателей. Но сервис не советуем, выводит мало слов и странно определяет частотность.
 Сервис не справляется с частотностью
Сервис не справляется с частотностью
Это не полный список сервисов, которые существуют для определения и проверки LSI-ключей, а некоторые, которые мы сами протестировали и поняли, что ими удобно пользоваться.
LSI-копирайтинг не противоречит SEO, а скорее дополняет его. Поисковикам не нужно, чтобы тексты были идеально оптимизированы для ботов, важнее всего смысловая нагрузка и полное раскрытие темы, чтобы материал был полезен аудитории. В хорошем LSI-тексте поисковые роботы смогут определить направление темы статьи и проиндексировать материал, а пользователи найдут подробные ответы на свои вопросы.
[править] Основные задачи, факторы и функции LSI-копирайтинга
Отличие LSI-копирайтинга от SEO-копирайтинга
Если для SEO-копирайтинга основой являются ключевые слова (ключевики), их плотность (частота применения и расположение) и виды вхождения в текст, то по методике LSI релевантность текстового контента напрямую зависит от вариантов использования ключевиков и слов из их окружения, соответствия контексту, уместности применения. Не меньшее значение при этом имеет качество самого текста, а также тематические предпочтения и потребности читателей. Последнее определяется по индексу отказов: после загрузки страницы читатель задерживается на ней не более 15 секунд. Это значит, что релевантность контента в большей степени зависит от содержания и смысла текста, чем от ключевых слов и фраз, вписанных в текстовый материал. (Примечание №3)
Виды LSI-ключей
Синонимичные (sLSI) – это слова-синонимы основного запроса, на которые прежде всего делают упор при оптимизации.
Релевантные (rLSI) – это слова из окружения главного ключевика, характеризующие и дополняющие его, а также другие слова и фразы, имеющие прямое отношение к теме статьи. По ним поисковый робот определяет, насколько хорошо раскрыта тема текста.
Основные требования к созданию LSI-текстов
Польза. Автор или автор текста должен знать свою целевую аудиторию, ее потребности и предпочтения, а LSI-текст во всем отвечать требованиям читателя.
Простота изложения. Простой, увлекательный, понятный текстовой материал хорошо воспринимается целевой аудиторией. С учетом этого подбираются стиль его написания и терминология.
Структура текста
Необходимо уделять внимание визуализации информации. Меткий, привлекающий внимание заголовок и подзаголовки, нумерованные и маркированные списки способствуют лучшей зрительной рецепции текста.
Ритм текста
Нужно следить за ритмом контента. Чередование коротких и длинных предложений придаст тексту динамику.
Распределение и плотность ключевых слов
Это важно не только для SEO-продвижения, но и для LSI-копирайтинга.
Достоверность информации. Раскрывать тему текста на уровне эксперта, а не любителя.
Недопустимость ошибок
Грамматика, синтаксис и структура предложений должны соответствовать нормам и правилам того языка, на котором пишется LSI-текст.
Лишь при выполнении всех перечисленных требований в их совокупности можно создавать тексты с высокой релевантностью.
Будущее LSI-копирайтинга
- повышать релевантность текстов поисковым запросам;
- улучшать ранжирование;
- увеличивать посещаемость;
- повышать привлекательность сниппета;
- опережать конкурентов.
Эффективность LSI-текстов согласно результатам эксперимента, проведенного канадским маркетинговым агентством New Media Sources. (Примечание №2)
Что собой представляет LSI-копирайтинг
В начале 2000-х годов «Яндекс», Google и другие поисковики работали по иным принципам, нежели сегодня. Релевантность запросу высчитывалась по количеству вхождений ключей на страницу. SEO-специалисты использовали это и наполняли свои тексты ключевыми словами до предела, а для дополнительной убедительности выделяли каждое такое словосочетание полужирным шрифтом. Читателю сложно было продираться сквозь такие тексты, однако благодаря им сайты выходили в топ.
Альтернативный подход принят в LSI-копирайтинге. Не нужно максимально насыщать контент ключевыми фразами, глубже раскрывайте их смысл, чтобы текст был интересен и увлекателен для читателя. Ключи, как инструмент СЕО, отходят на второй план и играют вспомогательную роль. Главными становятся слова и словосочетания, по смыслу связанные с темой текста.

Метод обработки контента на естественных языках называется латентным семантическим анализом (LSA) и заключается в установлении взаимосвязей между подборками документов и присутствующими в них терминами. Сопоставление ведётся на основе тематики. В результате выявляются смысловые и ассоциативные связи, включая неочевидные.
На этом методе построено латентное семантическое индексирование (LSI, latent semantic indexing), применяемое поисковыми системами. LSA помогает программе понять, о чём текст, каково его содержание и смысл. При ранжировании сайтов “вес” синонимов уравнивается, что позволяет структурировать запросы по смысловой близости, а не по написанию.
LSI строится на анализе терм-документной матрицы (LSA). Данная матрица – это таблица, где сведены документы и семантические единицы (“термы”), в качестве которых выступают отдельные слова, термины и целые фразы. Документы сгруппированы в строках, а слова – в столбцах. Интерес представляет количество их пересечений.
Важно! Некоторые удачные примеры LSI-копирайтинга – статьи, качественно написанные и грамотно оптимизированные, но без точных вхождений ключевого слова – попадают на самые верхние позиции в выдаче. Специалисту, которому заказали LSI-копирайтинг (написание текста, оптимизированного под LSI-алгоритм), желательно удерживаться от употребления редкой терминологии, известной только небольшому кругу профессионалов
И стараться избегать длинных сложноподчинённых предложений. Всё-таки их будет анализировать не живой человек, а искусственный интеллект, пока не являющийся слишком продвинутым
Специалисту, которому заказали LSI-копирайтинг (написание текста, оптимизированного под LSI-алгоритм), желательно удерживаться от употребления редкой терминологии, известной только небольшому кругу профессионалов. И стараться избегать длинных сложноподчинённых предложений. Всё-таки их будет анализировать не живой человек, а искусственный интеллект, пока не являющийся слишком продвинутым.
Чем отличается SEO от LSI
Чтобы освоить LSI-копирайтинг, нужно понимать, чем он отличается от привычной оптимизации
Давайте вспомним, на что мы обращаем внимание при работе с SEO-текстами:
- список ключей для прямого и разбавленного вхождения, их количество;
- уровень тошнотности и воды;
- уникальность;
- наращивание ссылочной массы;
- перелинковка.
Как выглядят тексты SEO и LSI в анализе?
Я решила проверить, какие статьи находятся в топ-10 Гугла по запросу “купить одежду для новорожденного”. На первой странице выдачи мне попалась SEO-статья, перенасыщенная ключами. Только представьте, на 2 000 символов пришлось 8–12 ключевых фраз. К тому же много воды, сложноподчиненных и сложносочиненных предложений, которые затрудняют восприятие информации.
Анализ провела с помощью TextAnalyzer.
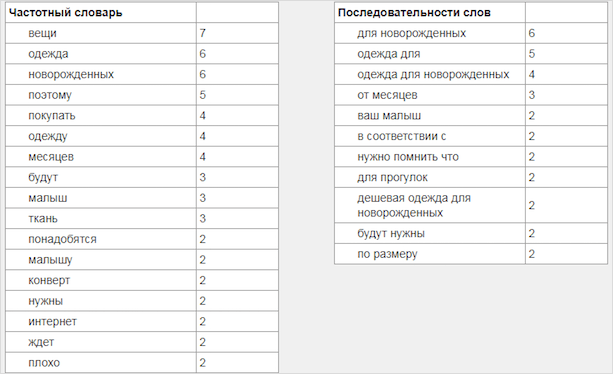
Затем я решила прошерстить выдачу по запросу “что такое SEO”. В первой десятке нашла неплохую статью. Встречаются тематические слова, синонимы, плотность вхождений выглядит естественно. Объем – 10 000 знаков.
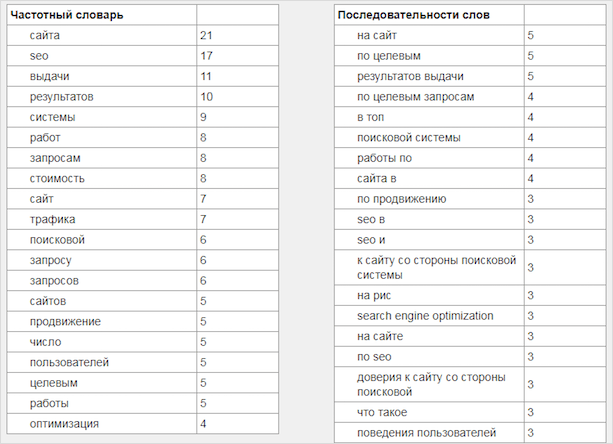
Посмотрите, на первых позициях у ЛСИ-текста стоят тематические слова, их количество умеренно. В случае с SEO-текстом заметна жесткая переоптимизация. SEO-статья пока в топе, но держится она там непрочно.
Что нового в LSI:
- Цена. Компаниям и вебмастерам придется раскошелиться. Минимальный объем LSI-статей – 10 000 знаков, стоимость за килознак в 2-3 раза выше привычного SEO-копирайтинга. Требуются опытные специалисты, время, хорошие программы. Дешевый рерайт не прокатит.
- Упрощенный сбор ТЗ. Специалистам по продвижению не придется ломать голову над ключами, анализировать плотность вхождений. Главная задача – четко и естественно ответить на вопрос пользователя. Технические аспекты на втором месте.
- Характер работы с ключами. Специалистам необходимо искать синонимы, тематические слова вручную, так как нет совершенных алгоритмов кроме матрицы и программных модулей, но они слишком сложные. Если в тексте тематических слов мало – качество низкое. Детальное ТЗ может содержать список обязательных к употреблению синонимов. Подбор ключей ведется с точки зрения релевантности теме, а не частотности. То есть насколько хорошо ключ соответствует теме.
- Качество. Статья должна содержать примеры, изображения, таблицы, а не просто быть объемной.
- Ценность для читателя. Пользователь не должен покидать страницу в течение 15 секунд. Если люди быстро уходят – поисковики будут считать контент бесполезным.
Можно ли назвать просто естественный текст LSI-копирайтингом? Нет.
Каждый смотрит на тему под своим углом, не видя полной картины. А читать статью будут тысячи людей, и у всех свой взгляд на вещи. Статистика от Яндекса и Google помогает собрать список ключей, которые будут важны потенциальной аудитории, оценить степень релевантности каждого к статье.
Принцип работы LSI
Компьютеры глупы.
Они не понимают словесные отношения, которое понятно людям. Например, очень большой и огромный — два разных слова, которые значат одно и то же. И все помнят, что Джон Леннон играл в Битлз.
Но у машины таких знаний нет. Проблема в том, что компьютеру невозможно рассказать все — на это уйдет слишком много времени и сил. LSi решает как раз эту проблему: технология использует математические формулы для получения связей между словами и фразами из набора документов.
Проще говоря, если применить метод к документам про смену времен года, компьютер сможет выяснить несколько моментов.
Например, что слова fall и autumn — синонимы:

Второе: слова «сезон», «лето», «зима», «весна» — синонимически схожи, потому что используются для описания одного процесса — смены времен года.

В-третьих, слово fall синонимически связано с двумя разными наборами слов:

Затем поисковые системы могут использовать информацию, чтобы выйти за рамки точного соответствия и предоставить более релевантные результаты поиска.

Определение LSI-копирайтинга
LSI, латентное семантическое индексирование, основано на технологии LSA, латентном семантическом анализе. Эта методика используется для автоматической индексации текста и проверки семантической структуры на наличие логических связей.
LSA задействует обновленные алгоритмы обработки данных с целью обнаружить в тексте не просто шквал ключевых слов, соответствующих поисковому запросу пользователя, а уловить общий смысл материала. С помощью LSA Яндекс, Google и другие поисковые машины могут находить для людей релевантный и полезный контент.
Подробнее о LSA
Ключевая задача LSA как метода – выявить логические связи в тексте. Поисковые боты используют эту методику для анализа естественного языка и формирования общей идеи текста, чтобы выдать статью в результатах поиска при вводе соответствующего запроса (в тот же Google или Яндекс).
Механизм LSA представляет собой систему сопоставления запроса с встречающимися в статьях терминами, а также модель анализа часто встречающихся в тексте слов с их определениями (проверка на соответствие фразы конкретной теме). Этот процесс позволяет «понять» тематику материала и оценить его качество без оглядки на плотность используемых ключевых слов.
Кратакая история индексации статей в интернете (появление тематического ядра)
В нулевых поиск работал примерно следующим образом:
-
Вы вводите какой-то поисковой запрос. Например, «купить гитара Москва недорого».
-
Получаете на первой странице десятки статей, которые идеально подогнаны под SEO благодаря огромному количеству ключей в тексте. Но смысла и пользы в этих статьях никакой.
На ранжирование влияли именно ключи. Они вставлялись даже в том случае, если не вписывались в текст логически и визуально. Тексты трудно было читать, они не несли внятной смысловой нагрузки, но все равно были в топ-10 статей по запросу.
С появлением новых алгоритмов (после 2011 года) поисковики научились анализировать содержимое текстов и фильтровать некачественные материалы, содержащие избыток ключей в груде исковерканного текста.
В ход пошли синонимы, ассоциации, гиперонимы, любые связанные текстовые элементы. В общем, некое тематическое ядро, напрямую не зависящее от выбранных ключевых слов. Именно тематическое ядро стало главным критерием при определении релевантности и качества текстов.
Пример тематического ядра
Блогер Koma Live в своей публикации на Medium описал наглядный пример использования тематического ядра и его влияния на результаты поиска.
Представим себе часто используемый поисковой запрос – «гольф». И вы взялись писать текст на эту тему, используя только одно ключевое слово. Основываясь только на нем, поисковик не сможет понять, о чем ваша статья. Об игре? Об автомобиле? Или о длинных носках? Поэтому робот будет пытаться проанализировать контекст (то самое тематическое ядро).
По этой причине копирайтерам в ТЗ часто указывают не только основные ключевые запросы, но и дополнительные слова, которые нужно использовать, чтобы сыграть на LSI-факторе (помимо SEO).
Проблема ключевых слов с длинным хвостом
Любой запрос в интернете, даже самый длинный, является ключом. Даже что-то в духе «обзор на лучшие ноутбуки 2020 года для программистов: HP, Lenovo, MSI, Samsung». Такие фразы не видны при поиске в подсказках Google, но они существуют и могут быть использованы для оптимизации.
Проблема таких ключей заключается в их избыточном количестве. И оптимизировать текст под каждый из них не получится. Отсюда возникает вопрос: оптимизировать текст под длинные ключи или просто упомянуть эти слова в контексте всего материала? На практике, при прочих равных, лучше работает второй метод.
LSI-копирайтинг на том и построен, что автор текста без определенных намерений адаптирует текст под бесконечное множество «хвостатых ключей», создавая тематическое ядро, которое поможет поисковику найти статью и закинуть ее в топ. Главное, чтобы сам материал оставался качественным.
Основные правила SEO-текстов в 2021 году
Приведем еще раз краткие характеристики хорошего оптимизированного материала:
Статья должна быть интересна для читателя: давать новые знания, помогать выбрать товар или знакомить с компанией.
Имеются 1-2 ключа в естественном виде на каждые 500-700 символов.
Показатели тошнотности и водности не превышают рекомендованных значений (проводить семантический анализ seo-текста удобнее на advego.com).
Информационные тексты объемные, содержат достаточно слов, характеризующих тему.
Материал разбит на абзацы, состоит из коротких и длинных предложений, имеет списки и визуальный контент.
Каждые 3-7 абзацев разделены подзаголовками H2.
Заголовок H1 не содержит основных ключевых фраз, привлекает внимание и отражает суть статьи.
Правильный SEO-текст — это уже не набор ключевых фраз. Благодаря тому, что поисковики «топят» за качество, копирайтинг вышел на новый уровень. Постепенно интернет очищается от мусорных текстов. Бизнес разворачивается лицом к покупателю и начинает использовать человеческий подход к контенту. От этого выигрывают и владельцы сайтов, и посетители.
Пишем Текст статьи
Если для подготовки seo тэгов количество фраз не очень большое, то для текстов мы находим огромное разнообразие вариантов и они в полной мере определяют тематику. Можно воспринимать весь набор собранных расширенных фраз как план статьи. Автору необходимо раскрыть тему используя предложенные варианты в точном или разбавленном виде.
При сохранении человечности текста (текст читается легко и раскрывает тему группы запросов), за этим следят проверки тошнотностей, большинство lsi фраз должны иметь зеленый оттенок. Т.е. при беглом осмотре визуально зеленый оттенок должен преобладать. Но желательно, что бы и желтые фразы встречались в списке, но если их много то рекомендуем провести более тщательный анализ, вчитываясь и пытаясь понять как можно употребить в тексте. Может понадобиться дописать абзац или полнее раскрыть подтему.
Приступая к работе над текстом мы открываем окно подробного анализа и изучаем предлагаемые системой фразы определяющие тему статьи, формируем предварительный ее план, какие темы будем раскрывать. Дальше изучаем не известные нам моменты, и пишем текст для людей, не обращая внимания на фразы и слова, просто раскрываем тематику и следим за логичностью структуры.
После полного раскрытия подтем и общей темы запросов значительная часть ключей уже перейдет в зеленую зону. Останется только финишная доводка текста и на этом этапе возможно всплывут не увиденные в начале подтемы. Так же раскройте их (а если не понятно что писать то необходимо изучить вопрос) например добавив дополнительные абзацы или дописав имеющиеся. В результате в итоговой работе большая часть lsi фраз примет зеленый оттенок и визуально во всем массиве цветов будет преобладать зеленый оттенок.
Пример итоговой окраски быстрого блока для проверки текста раскрывающего тематику:
и во всплывающем окне подробного анализа:
Попробовать бесплатно
Войти
Инструмент проверки текста анти Баден Баден от Яндекс
Проверка текста на переспам и воду, как не попасть под действие пессимизации Баден Бадена или Панды. Рассмотрим какие инструменты, предоставляет сервис, для создания качественного контента на сайт.
читать далее…
Командная работа над ТЗ
От слаженности команды порой сильно зависит конечный результат, как правильно организовать отделы и назначить ключевых сотрудников на различные этапы подготовки и выкладки статьи на сайт.
читать далее…
Адаптивная тема для wordpress
Условно бесплатная адаптивная тема на bootstrap, для создания заглушек новых статейных сайтов. При хорошем качестве контента и его должном оформлении показывает малое количество отказов, большую глубину просмотров и как следствие хорошие ПФ.
читать далее…
Одиночная работа и поиск копирайтеров
Система предоставляет визуальную систему контроля качества приготовления контента на сайт, но он был бы не полным без поддержки кооперативного режима работы с авторами. Подробно рассмотрим аспекты приготовления хорошей статьи используя инструментарий сервиса.
читать далее…
Какие статьи выкладывать на сайт первыми
Поисковые системы наращивают свою интеллектуальную мощь, усложняют алгоритмы и используют машинное обучение для улучшения своей выдачи перед конкурентами. Вебмастера постоянно отслеживают тенденции и меняют свои стратегии, но есть и базовые алгоритмы, рассмотрим один из них.
читать далее…
Вся конкуренция за несколько кликов
Конкуренция и частотность ключей определяет порядок выбора групп на написание статей. Чем менее конкурентные и более частотные статьи будут выписаны первыми тем больше вероятность быстрее получить посетителей на ваш сайт.
читать далее…
Создание структуры
Скелет любой статьи — структура. Именно она позволяет с первого взгляда оценить качество. Текст должен иметь иерархию и подчиняться внутренней логике. Части статьи не должны противоречить друг другу.
- Статья должна содержать заголовки и подзаголовки, маркированные списки и таблицы. Если это страница сайта, то стоит предусмотреть расположение отдельных элементов: кнопок, форм заказа, фотографий.
- Заголовок должен отражать основную идею материала, заголовки второго уровня — развивать тему в различных аспектах. Подзаголовки и заголовки третьего уровня указывают на частности или какие-то подробности.
- Заголовок и абзацы образуют, так называемые блоки. В каждом блоке может быть несколько абзацев. Абзац содержит от трех до шести строк и раскрывает одну определенную мысль. Короткие абзацы создают ощущение легкого, динамичного текста.
- Иерархию заголовков можно создать, опираясь на ключевые слова. Их нужно сгруппировать по смыслу. В статье идите от общего к частному — получится четкое и логичное повествование.
Обычно высокочастотные запросы касаются общей информации. Группа среднечастотников даст возможность глубже раскрыть тему. А низкочастотники позволят охватить нюансы, которые интересны пользователям.
Мета-теги для страниц на сайте
Хотя SEO-тексты постепенно отходят в прошлое, их наличие на сайтах может помочь в улучшении его позиций в поисковой выдаче
При этом важно не только хорошо написать сам текст, но и правильно проработать мета-теги. Для них действуют следующие правила:
- Ключевое слово должно быть в <Title>.
- Уникальный, «продающий» <Description> с ключевым словом.
- Правильная структура страницы: H1 – единственный, использование H2, H3, H4 для подзаголовков.
- Ключевые слова в alt и title картинок.
Все эти пункты может прописать как SEO-специалист, так и автор статьи, если он знаком с основами продвижения сайтов. Делать это необходимо основываясь на изучении страниц конкурентов. При этом не нужно как-то выделять ключевые слова. Это даже вредно, так как может привести к попаданию под фильтры поисковых систем. При этом использование средств для выделения в тексте не является запретным. Просто лучше курсивом или полужирным выделять какие-то термины или важные мысли, а не отдельные ключевые слова и фразы.
https://youtube.com/watch?v=hG1Tn2RkHMg
Отличие LSI от SEO-копирайтинга
Для удобства используем сравнительную таблицу
Отличия
SEO-тексты
LSI-тексты
Цель
Написать текст с нужными ключевыми словами и определенным числом вхождений
Полностью удовлетворить запрос пользователя
Задача
Вписать ключевые слова с определенной плотностью и расположением
Охватить весь спектр ассоциативных связей, рассмотреть проблему со всех сторон
Нахождение ключевых слов в тексте
В заголовках, в первом абзаце, выше по тексту
Не важно
Оформление статьи
Непринципиально
Необходимо
Способы оценки качества текста
Техническая уникальность, плотность вхождений, частота использования слов на определенный объем текста
Смысловая уникальность, полезность, удовлетворенность пользователя
Объем текста
От 2000 знаков с пробелами
Столько, сколько нужно для раскрытия темы. На практике 5000–10 000 знаков и больше.. Как видим, основное отличие — отход от чисто технических параметров текста к здравому смыслу: пользе, удобству читаемости
Можно сказать, что это эволюция SEO-копирайтинга — материалы создаются для людей, а не для роботов
Как видим, основное отличие — отход от чисто технических параметров текста к здравому смыслу: пользе, удобству читаемости. Можно сказать, что это эволюция SEO-копирайтинга — материалы создаются для людей, а не для роботов.
Это результат того, что теперь поисковые машины оценивают релевантность контента по смыслу. Учитывается контекст, уместность, семантические варианты запросов и их окружение. Вкупе с поведенческими факторами это позволяет оценивать качество текста и потребности читателей.