Как собрать ключевые слова на примере интернет-магазина фототехники
Содержание:
- Введение
- Этап 2. Сбор и чистка семантического ядра в Key Collector
- Методы и алгоритмы кластеризации
- Зачем делать кластеризацию?
- Как можно доработать алгоритм
- Как провести кластеризацию запросов вручную
- Кластеризация по поисковым топам
- О чем важно помнить при группировке ключевых фраз
- Как кластеризовать семантическое ядро онлайн, быстро и недорого
- Этап 1. Сбор вариаций написания продукта и маркеров
- Сервисы для кластеризации семантического ядра вручную
- Группировка в таблице связок Yagla
- Очистка семантики от мусора и поиск минус-слов
- Лучший метод кластеризации
- Этап 3. Кластеризация (группировка) семантического ядра
Введение
В середине десятых годов году вышел говнотренинг «Реальный Директ» от «бизнес молодости», где предлагали рекламировать септики по ключам с шашлыком. Это было шикарное время! Яндекс должен радоваться и прыгать от счастья, когда тысячи молодых выпускников стали сливать свои и чужие бюджеты (попутно разогревая аукционы) в бездонную бездну Яндекс Директа. Но был и спорный момент, потому что клиенты после взаимодействия с такими «директологами» уверовали в то, что директ — дно и пылесос для сбора денег, хотя это совершенно не так.
Основным посылом тех курсов стала мантра о том, что надо собирать десятки тысяч ключевых слов. Эта легенда разбилась о скалы реальности, когда маленькие любители контекстной рекламы стали закупать мусорный трафик, сливать бюджеты и получили логичный вопрос «где результаты?» от клиентов. Как вы уже знаете, вся эпопея с десятками тысяч ключей закончилась перегрузкой серверов Яндекса и введением статуса «мало показов».
Этап 2. Сбор и чистка семантического ядра в Key Collector
Перед началом сбора семантического ядра необходимо указать регион, по которому следует собирать запросы и их частотность. Регион напрямую связан с магазином, для которого собирается семантика, то есть если ваш магазин находится в Москве, то и запросы с их частотностью нужно собирать по данному региону. Для этого в нижней части окна мы выбираем регион для сервисов Yandex.Wordstat и Яндекс Директ:

После выбора региона можно приступать к сбору семантики.
Методика
В основном меню нажимаем кнопку «Пакетный сбор слов из левой колонки Yandex.Wordstat»:

В открывшимся окне мы увидим поле, куда необходимо добавить запросы прямо из нашего файла. После их добавления в нижней правой части окна следует нажать на иконку разделения фраз по группам:

После нажатия на кнопку в правой колонке групп мы увидим, что наши группы добавлены, и во всплывающем окне появилось поле с названиями наших групп, внутри которых находятся соответствующие запросы. Далее мы можем нажимать кнопку «Начать сбор»:

Запустив парсинг левой колонки Yandex.Wordstat, мы автоматически получаем все расширения наших запросов из сервиса, и теперь не будем собирать их вручную.
Следующим шагом является сбор корректной частоты запросов. Для этого следует очистить данные общей частотности, собранной вместе с запросами из сервиса Yandex.Wordstat, нажав на заголовок столбца правой кнопкой мыши и выбрав пункт «Очистить данные в колонке»:

Для сбора частотности мы используем функционал «Сбор статистики Yandex.Direct»:

Во всплывающем окне выбираем период сбора равный году. Это необходимо потому, что спрос на товары зачастую является сезонным, и без годовой частотности мы не сможем выявить самые популярные запросы. Целью сбора выбираем «Базовую» и «Уточненную» частотность, после чего нажимаем кнопку «Получить данные»:
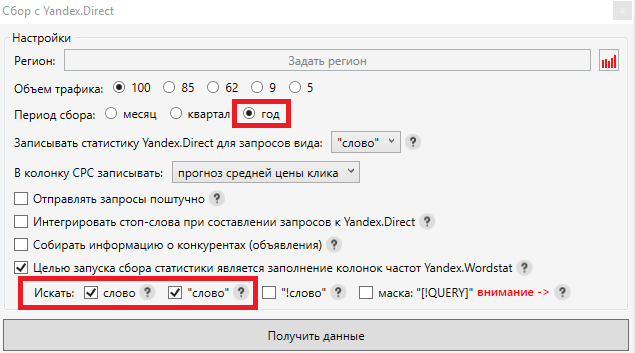
Когда частотность собралась, можно переходить к чистке семантики от мусорных фраз. Мы рекомендуем удалять запросы с «Уточненной» частотностью менее 10, так как это означает, что подобные запросы приносят меньше 1 посетителя в месяц.
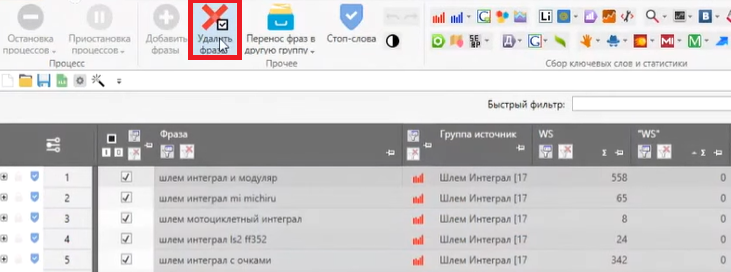
Выделяем такие запросы и нажимаем кнопку «Удалить фразы»:
Теперь можно приступить к чистке запросов по фразам.
Для этого есть несколько инструментов:
1. Инструмент фильтрации позволяет быстро отсечь часть ненужных запросов. Используя его, можно оставить в основной таблице только те фразы, которые включают в себя английские символы, цифры или состоят из 4 и более слов и т.п. для пакетного удаления.
2. Инструмент «Стоп-слова» позволяет отмечать фразы на удаление или последующий перенос в другую/новую группу по заранее загруженным в поле словам. Можно сразу выделить запросы с вхождениями городов (отличных от выбранного региона), названий компаний конкурентов, а также информационные запросы со словами «как», «почему», «отзывы», «реферат» и пр.
3. Инструмент «Анализ групп» позволяет собрать запросы в группы по различным вариантам группировки и отмечать названия групп, выделяя сразу несколько запросов для удаления или последующего переноса в другую/новую группу.
Рекомендуем пользоваться всеми инструментами, основным из которых должен стать «Анализ групп». Данный инструмент находится во вкладке «Данные»:

Во всплывающим окне можно увидеть несколько вариантов группировки, из которых мы советуем использовать метод «по отдельным словам».
В данном методе все запросы будут присутствовать в таблице и не случится того, что запрос, не попавший ни в одну группу, будет исключен из таблицы и его придется искать позже вручную в общем списке запросов.

Просматривая группы одну за другой, отмечаем их или фразы внутри них, которые явно нам не подходят. В процессе мы будем наблюдать, что, выбирая пять групп, мы уже отметили в общей таблице 9 фраз:

После того как отметим все группы и запросы в них, мы можем закрыть данное окно и нажать на кнопку «Удалить фразы».
После чего следует перейти к выгрузке запросов в Excel для последующей ручной чистки запросов и группировки семантики.
Чтобы совершить пакетную выгрузку всех запросов из разных групп, необходимо в правой колонке программы отметить все наши группы и нажать кнопку «Режим просмотра мульти-группы». После этого можно выгрузить наше семантическое ядро в Microsoft Excel:
Методы и алгоритмы кластеризации
В данный момент у большинства инструментов для кластеризации есть 2 основных алгоритма: hard и soft. У некоторых инструментов, таких как KeyAssort, есть ещё middle – нечто среднее между hard и soft, поэтому на его примере мы и будем рассматривать кластеризацию.
Чем эти методы отличаются и когда применять тот или иной алгоритм?

Все методы кластеризации используют один и тот же алгоритм – для каждой фразы собирают топ поисковой системы и сравнивают url всех фраз между собой. Но отличия всё же есть в методах сравнения.
Soft кластеризация
При этом методе сравниваются url у всех фраз между собой. У запроса А может быть общий набор url с запросом Б, а у запроса Б – общий набор url с запросом В. При этом запрос А и В могут не иметь общих URL. Такой метод подходит для информационных сайтов с низким уровнем конкуренции в тематике.
Middle кластеризация
При этом методе берётся один центральный запрос А и с ним сравниваются остальные фразы на предмет совпадения URL. Этот метод подходит для информационных сайтов с высоким уровнем конкуренции либо для коммерческих сайтов с низким уровнем конкуренции.
Hard кластеризация
При этом методе фразы будут объединены в группу только при совпадении общего для всех фраз набора URL. Метод характеризуется высокой точностью и подходит коммерческим сайтам с высоким уровнем конкуренции.
Зачем делать кластеризацию?
Почему тренд кластеризации на рынке уже около полутора лет? Почему это важно и как это поможет?
Экономия времени. Кластеризация — замечательная технология, которая поможет сократить рутину при работе с группировкой семантического ядра. Если обычный специалист по семантическому ядру разбирает 100 000 ключевых слов, отделяя их на группы, порядка 2-3 недель (а то и больше, если сложная семантика), то кластеризатор может это разделить в порядке очереди примерно за час.
Позволяет избежать ошибки продвигать разные запросы на одну страницу. В Яндексе есть классификаторы, которые оценивают коммерческие запросы. Например, выдача по информационным запросам и коммерческим — совершенно разная. Запросы «блеск для губ» и «купить блеск для губ» никогда не получится продвинуть на одну страницу.
1) По первому запросу («блеск для губ») стоят сайты информационной тематики (irecommend, Википедия). Под этот запрос нужна информационная страница.
То есть под разные запросы нужны разные типы страниц. Частая ошибка отимизатора — когда он продвигает все вместе на одну страницу. Получается так, что половина семантического ядра выходит в ТОП-10, а вторая половина никак не может туда попасть. Кластеризатор позволяет избежать таких ошибок.
Для того чтобы так не происходило, нужно изначально правильно сгруппировать запросы по типам страниц по выдаче.
Как можно доработать алгоритм
Выбирать перестановки по частотности
Например, запросы «купить кроссовки в москве» и «кроссовки в москве купить» – это, по сути, перестановка одних и тех же слов. В таком случае можно было бы говорить о том, что это один и тот же запрос, который встречается 2 раза. И в итоговом списке отдавать самую частотную перестановку.
Недописанные запросы
В любой базе ключевых слов встречаются запросы, с которыми SEO-специалист не работает. Например, запрос «блеск для губ от». Их легко выделить, потому что они заканчиваются предлогом или союзом.
Выбор языка
Когда мы говорим про парсинг выдачи Google, то мы, конечно, помним, что это мультиязычный поиск, он работает во всех странах.
Если так, тогда мы можем использовать этот алгоритм для того, чтобы собрать кластер запросов на чужом языке, например французском.
Как провести кластеризацию запросов вручную
Для ручной кластеризации семантического ядра сайта достаточно самостоятельно проанализировать ключевики и разделить их на группы. Эту работу можно облегчить с помощью инструментов Excel, LibreOffice, OpenOffice. Эти приложения позволяют работать с таблицами данных, выполнять сортировку и фильтрование по определенным параметрам.
Представленные инструменты имеют ряд достоинств:
- Универсальность — производят группировку с учетом множества разных критериев;
- Высокая точность обработки;
- LibreOffice, OpenOffice — бесплатные.
В числе их недостатков:
- Необходимость периодических бекапов;
- Низкая скорость обработки;
- Лицензионный Excel — платный.
Ручная кластеризация семантического ядра сайта более сложная и длительная по сравнению с автоматизированной. Зато можно лично проконтролировать весь процесс
Если этому уделить должное внимание, то результат качественно превзойдет автоматическую кластеризацию ся
Кластеризация по поисковым топам
Наиболее популярный метод группировки запросов – по принципу сходства поисковых выдач «Яндекса» или Google в автоматическом режиме. Данный метод, помимо главных преимуществ – скорости и экономии времени, обладает важным свойством. При кластеризации в одну группу не попадут запросы, по которым не получится продвинуть страницу.
К недостаткам можно отнести снижение качества кластеризации при недостаточно высоком качестве результатов выдачи по конкретному запросу или по выбранной нише в целом и сложность самостоятельной реализации метода вследствие необходимости применения многоступенчатого алгоритма и сбора большого количества данных из выдачи.
О чем важно помнить при группировке ключевых фраз
-
Группировать фразы нужно по базовому свойству. Оно должно точно определять продукт, тогда мы сможем указать его в заголовках и текстах объявлений.
-
Лучше использовать ручную или комбинированную группировку в зависимости от задач и количества ключей.
-
В зависимости от базисов кластеризовать ключевые фразы можно не по одному, а по нескольким признакам — например, гео + площадка.
-
Не стоит создавать группы с низкочастотными ключевыми фразами, по которым меньше 20 показов. В Директе такая группа может получить статус «Мало показов», а в Google Ads — рекомендацию удалить ключевое слово.
Как кластеризовать семантическое ядро онлайн, быстро и недорого
Пошаговая инструкция по работе с кластеризатором Click.ru:
Шаг 1. Зарегистрируйтесь в системе и перейдите на страницу инструмента.
Шаг 2. Укажите название проекта (для удобства) и адрес сайта. Можно оставить URL пустым, если сайт пока в разработке или он работает, но вам не нужен список рекомендованных целевых страниц.
 Добавление нового проекта
Добавление нового проекта
Шаг 3. Загрузите семантику одним из двух способов: списком в соответствующее поле через копировать-вставить или с помощью файла Excel.
В последнем случае надо учесть, что запросы берутся с каждой заполненной ячейки первого листа. Лишних символов – комментариев, заголовков, частотностей – быть не должно.
 Процесс загрузки поисковых запросов для последующей кластеризации
Процесс загрузки поисковых запросов для последующей кластеризации
Шаг 4. Установите точность кластеризации – количество совпадений URL в результатах поиска, при котором ключ добавляется в кластер.
Чтобы быстро кластеризовать семантическое ядро и не возиться с настройками, лучше указать точность сравнения топов в диапазоне 3–5. Если поставить цифру от 1 до 3, получатся слишком большие кластеры. При кластеризации с точностью от 6, наоборот, произойдет излишнее дробление семантики. Кстати, в профессиональном режиме можно сделать точность более гибкой, указать максимальный размер кластеров.
Шаг 5. Укажите поисковые системы и регионы, в которых нужно проанализировать топ-10 результатов поиска. Запустите кластеризацию.
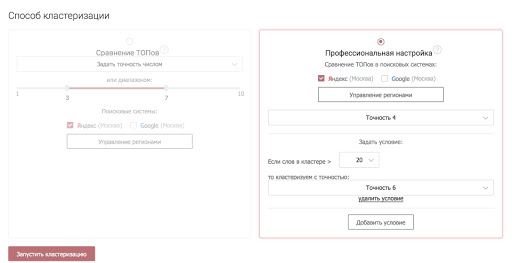 Последний шаг настройки кластеризации
Последний шаг настройки кластеризации
Оптимизировать сайт сразу под две поисковые системы не получится: нужно выбрать, что приоритетнее для вашего бизнеса. Если в России оба поисковика примерно одинаково популярны, то Украина, Казахстан и Европа преимущественно используют Google. Также гугл-поиск преобладает среди пользователей Android.
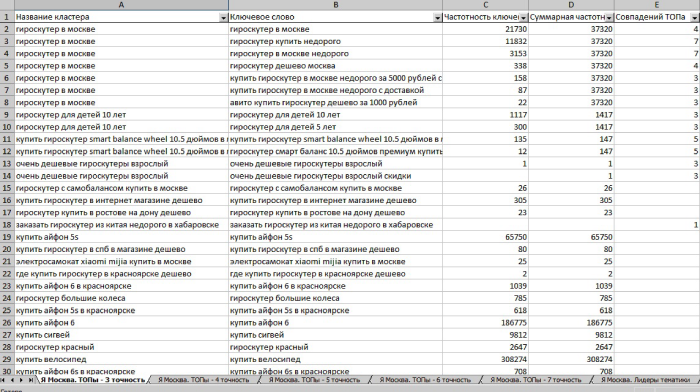 Пример готового отчета
Пример готового отчета
Стоимость кластеризации зависит от общего числа запросов, выбранных поисковых систем и количества регионов.
Группировка 1 ключа по 1 региону в 1 поисковике обойдется в 1 ТЗ – это внутренняя валюта инструментов Click.ru. Чем больше семантическое ядро, тем дешевле будет стоить кластеризация одного поискового запроса.
| ТЗ < 1 000 | ТЗ < 3 000 | ТЗ < 5 000 | ТЗ < 10 000 | ТЗ > 10 000 | |
| Цена, руб. | 0,09 | 0,08 | 0,07 | 0,06 | 0,05 |
Кстати, не нужно сразу платить деньги, если сначала хочется протестировать, как работает кластеризатор Click.ru. Новый пользователь получает в подарок 50 ТЗ при регистрации в системе. Этого хватит на кластеризацию небольшого семантического ядра.
Этап 1. Сбор вариаций написания продукта и маркеров
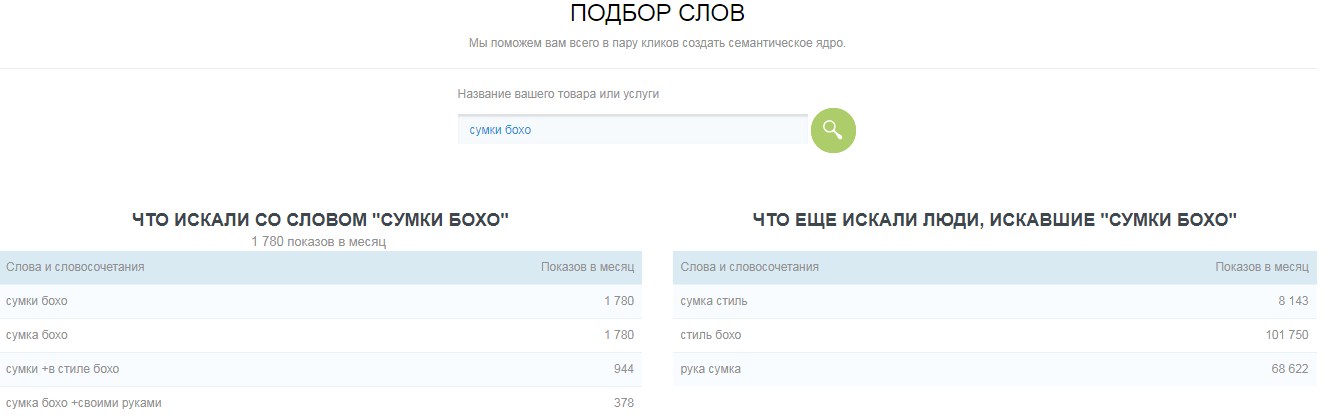
Перед сбором запросов необходимо выявить все возможные варианты написания продвигаемого продукта, а также маркеры (свойства). Для этого мы используем сервис подбора слов Яндекса.
Методика
Вписываем название нашего продукта в поисковую строку и нажимаем кнопку «Подобрать».

Детально просматриваем запросы из правой колонки полученных результатов и выявляем синонимы или иные варианты нашего запроса.

Переносим все найденные варианты названия продукта в отдельный файл.

На следующем шаге следует собрать маркеры, то есть свойства, определяющие продукт. Данные маркеры можно объединить по типам схожих свойств, например, Цвет, Бренд, Тип и иных.
Для выявления маркеров есть два пути:
1.Сбор и последующая чистка всей семантики по названию продукта, например, «Мотошлем».
1.1. Плюс: Сбор всех существующих в спросе маркеров;
1.2. Минус: Долгий и трудозатратный процесс.
2. Поиск и анализ страниц конкурентов в ТОП 10, которые уже имеют страницы с нашим продуктом.
2.1. Плюс: Быстрый процесс;
2.2. Минус: Неполный сбор свойств, если они отсутствуют у конкурентов.
Используя второй вариант, находим сайты конкурентов по запросам названия продукта, взяв страницы из ТОП 10
Это возможно сделать вводом основного запроса прямо в поисковую систему или же воспользоваться инструментом полноценного поиска конкурентов по видимости их сайтов, как было рассказано в 4 пункте первого этапа данной статьи.
На странице конкурента, нужно обратить внимание на структуру категории, то есть существуют ли подкатегории, или посмотреть функционал фильтрации товаров. В нем уже присутствуют группы свойств, внутри которых мы можем увидеть маркеры

Копируем подкатегории и/или маркеры, которые нас интересуют, то есть то, что действительно есть у продвигаемого сайта в ассортименте, и выносим в наш файл:
Следующим шагом сцепляем все варианты написания нашего продукта с маркерами, чтобы получить различные запросы для последующего сбора семантического ядра уже по ним. Рекомендуем использовать функцию «СЦЕПИТЬ» в Microsoft Excel. В результате получим таблицу, аналогичную представленной ниже:

Для пакетной (разовой) загрузки всех ключевых слов в KeyCollector следует опять воспользоваться функцией «СЦЕПИТЬ» (формируем запросы в формате «Группа:Ключ»). Таким образом мы сможем разом добавить все запросы в единое поле программы, которая в свою очередь создаст необходимые группы и добавит в них соответствующие запросы для расширения ядра. Итоговый список запросов в необходимом формате:

Сервисы для кластеризации семантического ядра вручную
Excel, LibreOffice, OpenOffice
Это самые простые и точные инструменты для качественной кластеризации. С ними думаю все понятно, берем и разносим все ключики вручную.
Плюсы:
- высокая точность обработки, т.к. разносится все руками;
- можно учесть много различных параметров при группировке;
Минусы:
- низкая производительность при больших объемах информации;
- необходимо постоянно сохраняться, ведь мало ли что, свет отключат, собака провод перегрызет и т. д.
LibreOffice, OpenOffice — бесплатны.
Microsoft Office Excel 2016 — платный (в среднем 9000 рублей), но мы-то знаем, что можно и дешевле…
Google документы
Плюсы:
- опять же хорошая точность;
- сервис работает в онлайн-режиме и сохраняет каждое изменение, не нужно уже бояться собак;
- бесплатен.
Минусы:
все ручками, отсюда низкая скорость работы.
Kg.ppc-panel
Сервис работает в режиме онлайн:
- Закидываем список ключевых фраз.
- Отсортировываем.
- Выделяем нужные нам группы.
Плюсы:
- интуитивно понятный интерфейс;
- высокая скорость работы;
- бесплатен.
Минусы:
- нельзя сохранить то, с чем работали;
- нет возможности загрузить частотность;
- скорость работы быстрее, чем в предыдущих сервисах, но ненамного;
Группировка в таблице связок Yagla
Чтобы сгруппировать фразы, выделите чек-бокс напротив нужных фраз, затем нажмите «Сгруппировать».
* все скриншоты кликабельные – жмите, чтобы увеличить изображение

Рядом с кнопками «Сгруппировать» и «Разгруппировать» будет указано, сколько чек-боксов вы выбрали. Вы всегда знаете, сколько фраз будет сгруппировано или разгруппировано, без необходимости пересчитывать их вручную.
Это позволяет не пропустить нужные фразы и не прихватить лишние в процессе группировки.

Визуально отличить одну группу от другой просто, так как они выделяются разными оттенками цвета:

Итак, механика группировки простая: когда вы выделяете фразы и нажимаете «Сгруппировать», они образуют отдельную группу:


Чтобы к готовой группе присоединить еще ключевые фразы, выделите эту группу целиком, затем – ключи, которые хотите дополнительно добавить, и нажмите «Сгруппировать»:



Чек-бокс прямо в шапке группировки позволяет быстро выделить все ключевые фразы:

Обратите внимание: эффект достигается не за счет «тупой» подмены «запрос = заголовок», а благодаря человекопонятному ценностному предложению для каждой группы запросов, то есть для каждой потребности. Также группировка необходима для оптимизации A/B тестов
Оставлять отдельные фразы (особенно низкочастотные) ни к чему, поскольку на низком трафике тест затянется намного дольше. Чем больше группа, тем больше по ней будет трафика и быстрее завершится тест
Также группировка необходима для оптимизации A/B тестов. Оставлять отдельные фразы (особенно низкочастотные) ни к чему, поскольку на низком трафике тест затянется намного дольше. Чем больше группа, тем больше по ней будет трафика и быстрее завершится тест.
Важно! После группировки фраз в рекламной кампании всё остается без изменений. Группы объявлений как работали, так и продолжают работать
Фильтрация
Чтобы группировать ключевые фразы было удобнее, используйте поиск по ключевой фразе. С помощью него можно быстро отобразить на странице все фразы с нужным значением или словом. Рассмотрим на примере.
Заходим в «Фильтр и сортировка»:

В строке поиска пишем «Срочно» и нажимаем «Отобразить»:

Теперь все ключевые фразы со значением «Срочно» можно в пару кликов объединить в одну группу:

Это очень удобно, так как нам не пришлось искать все эти фразы на странице по отдельности.
Очистить фильтр можно нажатием на крестик около надписи «Выбран 1 фильтр»:

Обратите внимание на следующие нюансы:
1) Если вы группируете две фразы или группы фраз, и у них уже прописаны по одному варианту подменяемых элементов (Вариант B), у полученной новой группы, будет два варианта подмен (Вариант B от первой группы и Вариант C от второй группы), и показываться они будут для этой группы поочередно.
Учитывайте это и при необходимости своевременно убирайте лишние варианты.
2) Если вы отделяете фразы от большой группы, в которой прописан текст к подменяемым элементам, текст остается у той группы, где ключевых фраз больше. Для группы, которая получается пустой (без текста) придется заново прописать подмены.
Очистка семантики от мусора и поиск минус-слов
Это отдельный инструмент, который помогает очистить первичный список ключевых слов и сразу получить список минус-слов для рекламной кампании.
Внимание: инструмент работает только для зарегистрированных пользователей. Он простой и быстрый:
Он простой и быстрый:
-
Вставляем весь список ключевых слов и нажимаем «Начать работу».
-
У вас появляется рабочая область, где вы, кликая по нерелевантным словам, выделяете все фразы с ними, слева автоматически будет создаваться список минус-слов.
-
После нажатия на кнопку «Получить список рабочих слов» система выведет все слова за исключением тех, что содержат в себе минус-слова.
В итоге вы можете быстро очистить свои ключевые слова от мусора, скопировать очищенный список в рабочий документ и перейти к группировке ключевых слов. А собранные минус-слова позже добавить в качестве минус-слов на уровне кампании, группы объявлений или аккаунта.
Также есть удобная функция «Найти словоформы выбранных слов». C ее помощью в загруженной семантике можно найти выбранные минус-слова в других падежах, множественном и единственном числах
Для Google Ads важно прописывать минус-слова во всех числах и склонениях
Лучший метод кластеризации
С точки зрения нашего многолетнего опыта наилучшими вариантами являются:
- кластеризация по ТОПу с последующим объединением по интенту;
- кластеризация по ТОПу с последующей разбивкой по интенту.
Автоматизация первого этапа (кластеризация по ТОПу, с использованием одного из сервисов или программных решений) позволяет ускорить процесс на больших массивах данных, выполняя роль первичной группировки. Дальнейший ручной этап помогает сформировать наиболее конкурентоспособные группы и создать соответствующую структуру сайта.
В большинстве случаев эти два подхода – объединение и разбивка – по сути не делятся на отдельные операции. На ручном этапе SEO-специалист принимает решение о необходимости объединения или разнесения запросов по страницам с учетом особенностей конкретного проекта и конкуренции в тематике.
Этап 3. Кластеризация (группировка) семантического ядра
Полученный список запросов нам нужно разбить на кластеры для последующей проработки посадочных страниц. Чтобы корректно выполнить эту задачу, нужно использовать сервисы кластеризации запросов, работающие на основе выдачи поисковых систем. Именно такой формат анализа, возможности продвижения тех или иных запросов на одной или разных страницах дает 70% успеха при дальнейшем продвижении сайта.
Популярные программные продукты:
1. KeyAssort – программа для кластеризации и структуризации семантического ядра.
2. Key Collector – функционал «Анализ групп» с типом группировки «По поисковой выдаче»).
Популярные онлайн-сервисы:
1. Engine Seointellect
2. Tools PixelPlus
3. Rush Analytics
Рассмотрим методику группировки запросов с помощью сервиса Engine Seointellect.
Методика
Полученный список запросов, который мы выгрузили из программы Key Collector, содержит столбец с названием «Группа». Нам необходимо по очереди добавлять все запросы из каждой группы в кластеризатор.
Заходим в сервис и выбираем в меню слева пункт «Кластеризация запросов». В открывшемся блоке мы видим кнопку «Новая группировка».
Нажимаем на данную кнопку. На экране появятся следующие поля для заполнения:
1. Добавить запросы – в данный блок мы добавляем все запросы из первой анализируемой группы.
2. Вид группировки включает в себя три вида жесткости кластеризации:
2.1.«Hard» – жесткая группировка.
2.2.«Balance» – группировка средней жесткости.
2.3.«Soft» – группировка низкой жесткости.
Подробнее про различие работы методов группировки можно посмотреть в данном видео:
При группировке коммерческих запросов, как в нашем случае, следует изначально выбирать метод группировки «Hard», если запросы информационные, то рекомендуем пользоваться только методом «Soft».
3. Регион выбираем соответствующий регион продвижения.
4. Мой сайт не нужно указывать, так как эта функция нужна для определения запросов по уже существующим посадочным страницам указанного сайта.
- Нажав «Запустить группировку», необходимо дождаться окончания процесса сбора данных. При завершении анализа в правой части созданного задания вместо отображения процесса появится иконка «Глаз», на которую необходимо нажать.
- Мы попадаем на страницу результата группировки и можем проанализировать данные:
1. Мы видим, что все наши запросы, кроме одного, попали в одну группу (отмечено зеленым), а значит их можно продвигать вместе на одной посадочной странице.
2. Также присутствует нераспределенный запрос (отмечено синим), это значит, что по данному запросу результаты выдачи сильно отличаются от результатов других запросов. В таком случае следует сделать вывод, что под этот запрос нужно создавать отдельную посадочную страницу бренда Ataki.
3. Справа от группы есть функционал «Показать список URL», нажав на который откроется блок со ссылками на страницы из ТОП 10, по которым была проведена кластеризация.
- Если бы мы добавили большее количество запросов в кластеризатор, то в нераспределенных могли оказаться фразы, которые можно продвигать в готовых группах. Можно просто увидеть эти запросы и перенести в нужную группу, но если фраз много, то их следует отправить на группировку по методу «Soft». Полученные группы по методу группировки «Soft» соединить с группами, полученными ранее по методу «Hard».
- Проведя данные действия с каждой группой из нашего файла, мы получим готовый список разделенных запросов, для последующей проработки страниц.