Как посмотреть кэшированную версию сайта
Содержание:
- Сайт студента-программиста
- Смотрим, как выглядела страница раньше
- Что предшествовало возникновению первого в мире сайта
- Все про archive.org: как пользоваться сервисом и как достать сайт из веб-архива
- Как посмотреть сайт в прошлом
- archive.md
- Сайт клуба программистов Новосибирского Государственного Университета Octopus
- Возможности использования веб-архивов
- Как посмотреть удаленную страницу в веб-архиве
- Кто такой Тим Бернерс Ли
- Потеря исходных файлов
- GetLeft
- Респект за пост! Спасибо за работу!
- Twitter (март 2006): привет из девяностых
- Как архивировать фото, видео и Истории
Сайт студента-программиста
Домашние страницы «Я Миша, я живу в Нью-Йорке, у меня есть кот» — основа русскоязычного интернета тех лет. Такие сайты создали эмигранты, которые искали общения с бывшими соотечественниками. До 1997 года личных страниц именно жителей России было еще мало.
Например, 22-летний Юрий Блажевич из МФТИ выкладывал на сайте свое резюме и написанные им программы для создания 3D-графики. Там же он рассказывал о своих интересах и собирал ссылки на полезные интернет-сайты.
Через несколько лет парень смог сделать хорошую карьеру и стал ведущим программистом в популярной игре «Блицкриг 2». Но, к сожалению, ушел из жизни в 2007 году.
Сохраненная страница: 7 октября 1997 года.
Смотрим, как выглядела страница раньше
Первым делом нужно отметить, что просмотр ранней копии страницы, будь то действующий или уже удаленный аккаунт пользователя, возможен лишь тогда, когда настройки приватности не ограничивают работу поисковых систем. В противном случае сторонние сайты, включая сами поисковики, не могут кэшировать данные для дальнейшей демонстрации.
Подробнее: Как открыть стену ВК
Способ 1: Поиск Google
Наиболее известные поисковые системы, имея доступ к определенным страницам ВКонтакте, способны сохранять копию анкеты в своей базе данных. При этом срок жизни последней копии сильно ограничен, вплоть до момента повторного сканирования профиля.
- Воспользуйтесь одной из наших инструкций, чтобы найти нужного пользователя в системе Google.
Подробнее: Поиск без регистрации ВК
Среди представленных результатов отыщите нужный и кликните по иконке с изображением стрелочки, расположенной под основной ссылкой.
Из раскрывшегося списка выберите пункт «Сохраненная копия».
После этого вы будете перенаправлены на страницу человека, выглядящую в полном соответствии с последним сканированием.
Даже при наличии активной авторизации ВКонтакте в браузере, при просмотре сохраненной копии вы будете анонимным пользователем. В случае попытки авторизации вы столкнитесь с ошибкой или же система вас автоматически перенаправит на оригинальный сайт.
Допускается просмотр только той информации, что загружается вместе со страницей. То есть, например, посмотреть подписчиков или фотографии у вас не получится, в том числе из-за отсутствия возможности авторизации.
Использование этого метода нецелесообразно в случаях, когда необходимо найти сохраненную копию страницы очень популярного пользователя. Связано это с тем, что подобные аккаунты часто посещаются сторонними людьми и потому гораздо активнее обновляются поисковыми системами.
Способ 2: Internet Archive
В отличие от поисковых систем, веб-архив не ставит требований перед пользовательской страницей и ее настройками. Однако на данном ресурсе сохраняются далеко не все страницы, а только те, что были добавлены в базу данных вручную.
Главным отрицательным фактором способа является то, что любая информация на странице, за исключением вручную введенных данных, представлена на английском языке. Избежать этой проблемы можно, прибегнув к следующему сервису.
Способ 3: Web Archive
Данный сайт является менее популярным аналогом предыдущего ресурса, но со своей задачей справляется более чем хорошо. Кроме того, вы всегда можете воспользоваться этим веб-архивом, если ранее рассмотренный сайт по каким-либо причинам оказался временно недоступен.
- Открыв главную страницу сайта, заполните основную поисковую строку ссылкой на профиль и нажмите кнопку «Найти».
После этого под формой поиска появится поле «Результаты», где будут представлены все найденные копии страницы.
В списке «Другие даты» выберите колонку с нужным годом и кликните по наименованию месяца.
С помощью календаря кликните по одному из найденных чисел.
По завершении загрузки вам будет представлена анкета пользователя, соответствующая выбранной дате.
Как и в прошлом методе, все возможности сайта, кроме непосредственного просмотра информации, будут блокированы. Однако на сей раз содержимое полностью переведено на русский язык.
Вы также можете прибегнуть к еще одной статье на нашем сайте, рассказывающей о возможности просмотра удаленных страниц. Мы же завершаем данный способ и статью, так как изложенного материала более чем достаточно для просмотра ранней версии страницы ВКонтакте.
Опишите, что у вас не получилось.
Наши специалисты постараются ответить максимально быстро.
Что предшествовало возникновению первого в мире сайта
Прежде чем создать и запустить свой первый сайт, задолго до этого Тим Бернерс-Ли трудился над разработкой других, не менее важных инструментов о которых мы упоминали ранее. Только после создания интернета, разработки самого первого в мире гипертекстового браузера под названием WorldWideWeb или WWW, сервера запрограммированного на базе NeXTcube, без которого сайт ни каким образом не мог быть запущенным, а также технологии веба HTTP, был создан и запущен этот судьбоносный для всего человечества, сайт.
Плюсом новоиспеченного браузера, известного как WWW, было то, что он открывал возможность для свободного доступа пользователей к внутренним документам находящимся в сети, а также к вложенным в сайты страницам. То есть посредством этого браузера, пользователи могли посетить практически любые, интересующие их страницы в интернете. Поэтому в самые короткие сроки, именно браузер WWW стал считаться стандартным для выхода пользователей во всемирную интернет-паутину.
Конечно, на первых порах, практически все программное обеспечение было очень ограничено в плане функционала, а что касается панели первого веб-редактора, то она и вовсе состояла из нескольких командных кнопок. Интересно, что уже через пару месяцев после запуска первого сайта, стали очень широко использоваться статичные веб-страницы, которые являлись своеобразными информационными носителями о том или ином продукте, услуге.
Прошло много времени и на сегодняшний день, ни один из продуктов который разработал Тим Бернерс-Ли, не используется в оригинале. Все они потерпели изменения, реструктуризацию, которая помогла им приспособиться к современному обществу и его запросам, хотя при этом остались в основе программного софта. Но если говорить об основной концепции создания интернета и сайта в целом, то все осталось неизменным. Так как и задумывал разработчик, интернет используется для сбора и хранения информации, а сайты являются своеобразными «папками», которые собирают и хранят информацию различной направленности.
Все про archive.org: как пользоваться сервисом и как достать сайт из веб-архива
Брюстер Кайл создал сервис Internet Archive Wayback Machine, без которого невозможно представить работу современного интернет-маркетинга. Посмотреть историю любого портала, увидеть, как выглядели определенные страницы раньше, восстановить свой старый веб-ресурс или найти нужный и интересный контент — все это можно сделать с помощью Webarchive.
Как на archive.org посмотреть историю сайта
Благодаря веб-сканеру, в библиотеке веб-архива, хранится большая часть интернет-площадок со всеми их страницами. Также, он сохраняет все его изменения. Таким образом, можно просмотреть историю любого веб-ресурса, даже если его уже давно не существует.
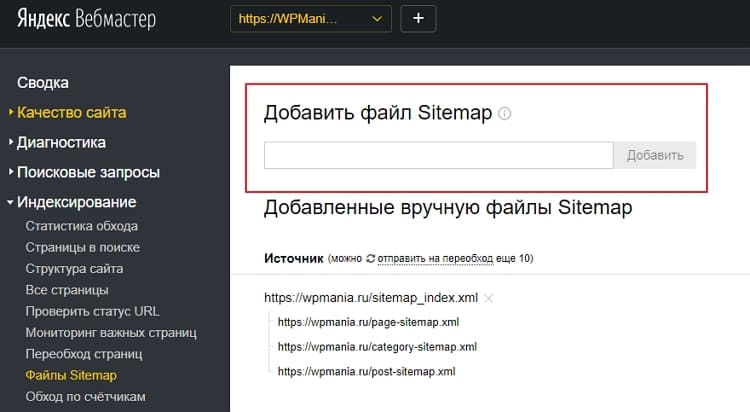
Для этого, необходимо зайти на https://web.archive.org/ и в поисковой строке ввести адрес веб-ресурса.
После, некоторого времени, веб-архив выдаст календарь с датами изменений данной страницы и информацию о его создании и количестве изменений за весь период.
Далее, с помощью календаря со стрелками, в самом верху экрана, можно перелистывать страницы, по хронологии их изменений, чтобы отследить, как изменялся внешний вид и их содержание.
Таким образом, можно нырнуть в прошлое и увидеть все его перемены, которые с ним происходили за все время его существования.
Почему вы можете не узнать на Webarchive, как выглядел сайт раньше
Случается такое, что веб-площадка не может быть найден с помощью сервиса Internet Archive Wayback Machine. И происходит это по нескольким причинам:
- правообладатель решил удалить все копии;
- веб-ресурс закрыли, согласно закону о защите интеллектуальной собственности;
- в корневую директорию интернет-площадки, внесен запрет через файл robots.txt
Для того, чтобы сайт в любой момент был в веб-архиве, рекомендуется принимать меры предосторожности и самостоятельно сохранять его в библиотеке Webarchive. Для этого в разделе Save Page Now введите адрес веб-ресурса, который нужно заархивировать, нажмите кнопку Save Page
Таким образом, для безопасности и сохранности всей информации, необходимо такую процедуру повторять с каждым изменением. Это даст 100% гарантию сохранения ваших страниц на долгое время.
Как недействующий сайт восстановить из веб-архива
Бывают разные ситуации, когда браузер выдает, что такого-то веб-сервиса больше нет. Но данные нужно извлечь. Поможет Webarchive.
И для этого существует два варианта. Первый подходит для старых площадок небольшого размера и хорошо проиндексированных. Просто извлеките данные нужной версии. Далее просматривается код страницы и дошлифовываются вручную ссылки. Процесс несколько трудозатратный по времени и действиям. Поэтому существует другой, более оптимальный способ.
Второй вариант идеален для тех, кто хочет сэкономить время и решить вопрос скачивания, максимально быстро и легко. Для этого нужно открыть сервис восстановления сайта из Webarchive – RoboTools. Ввести доменное имя интересующего портала и указать дату сохраненной его версии. Через некоторое время, задача будет выполнена в полном объеме, с наполнением всех страниц.
Как найти контент из веб-архива
Webarchive является замечательным источником для наполнения полноценными текстами веб-ресурсов. Есть множество площадок, которые по ряду причин прекратили свое существование, но содержат в себе полезную и нужную информацию. Которая не попадает в индексы поисковых систем, и по сути есть неповторяющейся.
Так, существует свободные домены, которые хранят много интересного материала. Все что нужно, это найти подходящее содержание, и проверить его уникальность. Это очень выгодно, как финансово – ведь не нужно будет оплачивать работу авторов, так и по времени – ведь весь контент уже написан.
Как сделать так, чтобы сайт не попал в библиотеку веб-архива
Случаются такие ситуации, когда владелец интернет-площадки дорожит информацией, размещенной на его портале, и он не хочет, чтобы она стала доступной широкому кругу. В таких ситуациях есть один простой выход – в файле robots.txt, прописать запретную директиву для Webarchive. После этого изменения в настройках, веб-машина больше не будет создавать копии такого веб-ресурса.
Как посмотреть сайт в прошлом
Есть несколько сервисов, в которых можно посмотреть, как менялось визуальное оформление страниц сайта, его структуру страниц и контент, положение в поисковой выдаче и какие изменения вносились в регистрационные данные за время существования ресурса.
Сервис Веб-архив
При его использовании сначала заходим на сайт https://web.archive.org/ и после вводим адрес страницы.
График ниже показывает количество сохранений: первое было в 1998 году.
Дни, в которые были сохранения, отмечены кружком. При клике на время во всплывающем окне, открывается сохраненная версия. Показано ниже:
Как выгрузить сайт из ВебАрхива, расскажем дальше.
Сервис Whois History
Для его использования заходим на сайт http://whoishistory.ru/ и вводим данные в поиске по доменам и IP, либо по домену:
Сервис покажет информацию по данным Whois, где собраны сведения от всех регистраторов доменных имен. Посмотреть можно возраст домена, кто владелец, какие изменения вносились в регистрационные данные и т.д.
archive.md
Адреса данного Архива Интернета:
На главной странице говорящие за себя поля:
- Архивировать страницу, которая сейчас онлайн
- Искать сохранённые страницы
Для поиска по сохранённым страницам можно как указывать конкретный URL, так и домены, например:
- microsoft.com покажет снимки с хоста microsoft.com
- *.microsoft.com покажет снимки с хоста microsoft.com и всех его субдоменов (например, www.microsoft.com)
- покажет архив данного url (поиск чувствителен к регистру)
- поиск архивных url начинающихся с http://twitter.com/burg
Данный сервис сохраняет следующие части страницы:
- Текстовое содержимое веб страницы
- Изображения
- Содержимое фреймов
- Контент и изображения загруженные или сгенерированные с помощью Javascript на сайтах Web 2.0
- Скриншоты размером 1024×768 пикселей.
Не сохраняются следующие части веб-страниц:
- Flash и загружаемый им контент
- Видео и звуки
- RSS и другие XML-страницы сохраняются ненадёжно. Большинство из них не сохраняются, или сохраняются как пустые страницы.
Архивируемая страница и все изображения должны быть менее 50 Мегабайт.
Для каждой архивированной страницы создаётся ссылка вида http://archive.is/XXXXX, где XXXXX это уникальный идентификатор страницы. Также к любой сохранённой странице можно получить доступ следующим образом:
- http://archive.is/2013/http://www.google.de/ — самый новый снимок в 2013 году.
- http://archive.is/201301/http://www.google.de/ — самый новый снимок в январе 2013.
- http://archive.is/20130101/http://www.google.de/ — самый новый снимок в течение дня 1 января 2013.
Дату можно продолжить далее, указав часы, минуты и секунды:
- http://archive.is/2013010103/http://www.google.de/
- http://archive.is/201301010313/http://www.google.de/
- http://archive.is/20130101031355/http://www.google.de/
Для улучшения читаемости, год, месяц, день, часы, минуты и секунды могут быть разделены точками, тире или двоеточиями:
- http://archive.is/2013-04-17/http://blog.bo.lt/
- http://archive.is/2013.04.17-12:08:20/http://blog.bo.lt/
Также возможно обратиться ко всем снимкам указанного URL:
http://archive.is/http://www.google.de/
Все сохранённые страницы домена:
http://archive.is/www.google.de
Все сохранённые страницы всех субдоменов
http://archive.is/*.google.de
Чтобы обратиться к самой последней версии страницы в архиве или к самой старой, поддерживаются адреса вида:
- http://archive.is/newest/http://reddit.com/
- http://archive.is/oldest/http://reddit.com/
Чтобы обратиться к определённой части длинной страницы имеется две опции:
В доменах поддерживаются национальные символы:
- http://archive.is/www.maroñas.com.uy
- http://archive.is/*.测试
Обратите внимание, что при создании архивной копии страницы архивируемому сайту отправляется IP адрес человека, создающего снимок страницы. Это делается через заголовок X-Forwarded-For для правильного определения вашего региона и показа соответствующего содержимого.
Сайт клуба программистов Новосибирского Государственного Университета Octopus
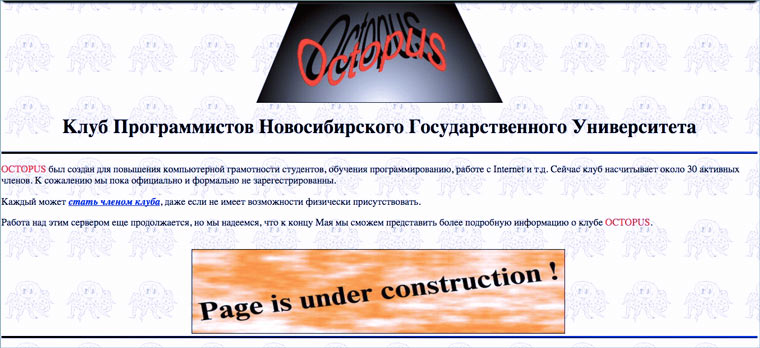
Многие сайты тех лет создавались следующим образом: собиралась группа энтузиастов в каком-нибудь научно-техническом учреждении (где был доступ к интернету) и создавали страницу с кратким рассказом о себе. Часто такие сайты оставались в полуготовом состоянии. Ведь тогда не было четкого видения как нужно делать сайт, зачем и, главное, для кого.
«Работа над этим сервером еще продолжается, но мы надеемся, что к концу Мая сможем представить более подробную информацию о клубе Octopus» — различные вариации подобной надписи встречаются в 1996 году на каждом углу. Сайт тогда часто называли сервером, а простую страницу с текстом верстали неделями (по самоучителю html и в свободное от работы время).
Сохраненная страница: 6 апреля 1997 года.
Возможности использования веб-архивов
Возможности сохраненной истории
Теперь каждый знает, что такое веб-архив, какие сайты предоставляют услуги сохранения копий проектов. Но многие до сих пор не понимают, как использовать представленную информацию. Возможности архивных данных выражаются в следующем:
- Выбор доменного имени. Не секрет, что многие веб-мастера используют уже прокачанные домены. Стоит понимать, что опытные юзеры отслеживают не только целевые параметры, но и историю предыдущего использования. Каждый пользователь сети желает знать, что приобретает: имелись ли ранее запреты или санкции, не попадал ли проект под фильтры.
- Восстановление сайта из архивов. Иногда случается беда, которая ставит под угрозу существование собственного проекта. Отсутствие своевременных бэкапов в профиле хостинга и случайная ошибка может привести к трагедии. Если подобное произошло, не стоит расстраиваться, ведь можно воспользоваться веб-архивом. О процессе восстановления поговорим ниже.
- Поиск уникального контента. Ежедневно на просторах интернета умирают сайты, которые наполнены контентом. Это случается с особым постоянством, из-за чего теряется огромный поток информации. Со временем такие страницы выпадают из индекса, и находчивый веб-мастер может позаимствовать информацию на личный проект. Конечно, существует проблема с поиском, но это вторичная забота.
Мы рассмотрели основные возможности, которые предоставляют веб-архивы, самое время перейти к более подробному изучению отдельных элементов.
Восстанавливаем сайт из веб-архива
Фиксация в веб-архиве за 2011–2016 годы
Никто не застрахован от проблем с сайтами. Большинство их них решается с использованием бэкапов. Но что делать, если сохраненной копии на сервере хостинга нет? Воспользоваться веб-архивом. Для этого следует:
- Зайти на специализированный ресурс, о которых мы говорили ранее.
- Внести собственное доменное имя в строку поиска и открыть проект в новом окне.
- Выбрать наиболее удачный снимок, который располагается ближе к проблемной дате и имеет полноценный вид.
- Исправить внутренние ссылки на прямые. Для этого используем ссылку «http://web.archive.org/web/любой_порядковый_номер_id_/Название сайта».
- Скопировать потерянную информацию или данные дизайна, которые будут применены для восстановления.
Заметим, что процесс несколько утомительный, с учетом скорости работы архива. Поэтому рекомендуем владельцам больших веб-ресурсов чаще выполнять бэкапы, что сохранит время и нервы.
Ищем уникальный контент для собственного сайта
Уникальный контент из веб-архива
Некоторые веб-мастера используют интересный способ получения нового, никому не нужного контента. Ежедневно сотни сайтов уходят в небытие, а вместе с ними теряется информация. Чтобы стать владельцем контента, нужно выполнить следующее:
- Внести URLв строку поиска.
- На сайте аукциона доменных имен скачать файлы с именем ru.
- Открыть полученные файлы с использованием excel и начать отбор по параметру наличия проектной информации.
- Найденные в списке проекты ввести на странице поиска веб-архива.
- Открыть снимок и получить доступ к информационному потоку.
Рекомендуем отслеживать контент на наличие плагиата, это позволит найти действительно достойные тексты. А на этом все! Теперь каждый знает о возможностях и методах использования веб-архива. Используйте знание с умом и выгодой.
Как посмотреть удаленную страницу в веб-архиве
Веб-архив – это специальный сервис, который хранит на своем сервере данные со всех страниц, которые есть в интернете. Даже, если сайт перестанет существовать, то его копия все равно останется жить в этом хранилище.
В архиве также хранятся все версии интернет страниц. С помощью календаря разрешено смотреть, как выглядел тот или иной сайт в разное время.
В веб-архиве можно найти и удаленные страницы с ВК. Для этого необходимо выполнить следующие действия.
- Зайти на сайт https://archive.org/.
- В верхнем блоке поиска ввести адрес страницы, которая вам нужна. Скопировать его из адресной строки браузера, зайдя на удаленный аккаунт ВК.
Используя интернет-архив вы, естественно, не сможете написать сообщение, также как узнать когда пользователь был в сети. Но посмотреть его последние добавленные записи и фото очень даже можно.
Страница найдена
Если искомая страница сохранена на сервере веб-архива, то он выдаст вам результат в виде календарного графика. На нем будут отмечены дни, в которые вносились изменения, добавлялась или удалялась информация с профиля ВК.
Выберите дату, которая вам необходима, чтобы увидеть, как выглядела страница. Используйте стрелочки «вперед» и «назад», чтобы смотреть следующий или предыдущий день либо вернитесь на первую страницу поиска и выберите подходящее число в календаре.
Страница не найдена
Может случиться, что необходимая страница не нашлась на сайте WayBackMachine. Это не значит, что вы что-то сделали не правильно, такое часто случается. Возможно, аккаунт пользователя был закрыт от поисковиков и посторонних сайтов и поэтому не попал в архив. WayBackMachine самый популярный сайт, но он не единственный в своем роде. Попробуйте найти в Яндексе или Гугле другие веб-архиви. Искомая страница могла сохраниться на их серверах.
Попытайте удачу в поисках архивной версии профиля на этих сайтах:
- archive.is;
- webcitation.org;
- freezepage.com;
- perma.cc.
Также обязательно попробуйте найти страничку на русскоязычном аналоге http://web-arhive.ru/.
Кто такой Тим Бернерс Ли
У Бернерса Ли идеальный образ значимой фигуры в IT-индустрии.
Он знаком с технологиями с детства. Его родители были математиками и занимались разработкой одного из первых компьютеров в мире «Марк I».
Учась в Оксфордском королевском колледже, Тим устроил хакерскую атаку на учебное заведение. За это ему запретили пользоваться университетскими десктопами.
Ломал сетку, до того как это стало мэйнстримом.
С начала запуска Веба британец настаивал, что интернет должен быть общедоступным и децентрализованным.
Он даже не попытался заработать на правах на технологию и отказался патентовать ее.
«Если бы эта технология была проприетарной, и я полностью ее контролировал, она бы, скорее всего, не взлетела. Невозможно предложить то, что было бы общедоступным, и при этом вы сохранили контроль над ним», — говорил ученый.
Тим Бернерс Ли слева, Роберт Кайо справа
Помимо причастности к созданию первого сайта, Тим Бернерс Ли считается изобретателем URI, URL, HTTP и HTML. Именно эти технологии можно найти в info.cern.ch.
Если точнее, Бернерс Ли придумал:
- язык разметки HTML для создания веб-страниц
- протокол HTTP для передачи данных в Вебе
- систему унифицированных адресов ресурсов URL для поиска документа или страницы
Эти технологии применяются в интернете и сейчас.
Главная страница сайта
Цель проекта банальна для эпохальной технологии на начальной стадии — упростить работу команде. Марк Цукерберг затем же создавал Facebook, чтобы ему и его одногруппникам было проще общаться друг с другом.
ЦЕРН отклонил идею, но Бернерс Ли проявил настойчивость и продолжил разрабатывать сайт, уже в команде с Робертом Кайо.
Так раньше выглядел ЦЕРН, Европейская организация по ядерным исследованиям, крупнейшая в мире лаборатория физики высоких энергий.
Ученый предложил сделать так, чтобы гипертекст был доступен одновременно нескольким компьютерам, подключенным к интернету.
«Меня расстраивало, на разных компьютерах содержалась разная информация. И чтобы получить к ней доступ к нескольким источникам, нужно задействовать несколько компьютеров», — говорил Бернерс Ли.
NeXT. Компьютер, на котором был создан первый веб-сайт.
У британца была и более масштабная задача. В ЦЕРН приезжали люди из университетов со всего мира, и привозили с собой компьютеры со всеми видами программного обеспечения. Проблемой была невозможность использования одной программы на компьютерах с разными видами софта.
Бернерс Ли искал ее решение. Изначально он думал о создании ряда программ, берущих информацию из одной системы и конвертирующих ее формат для показа в другой.
Но оптимизировать программы под каждый софт — долго, энергозатратно и дорого. Британец выбрал другой способ: просто дать доступ к информации всем сразу.
Интерфейс Юзнета.
До создания и развития веба популярностью пользовалась компьютерная сеть Юзнет (Usenet).
Она также использовалась для общения и передачи файлов. Но принцип был другим: отличие в том, что Юзнет состоял не из страниц, а из новостных групп и работал по протоколу NTTP.
Кстати, эта сеть стала фундаментом в развитии веба. Именно в ней появились первые интернет-сообщества. Ее пользователи ввели понятия «ник», «смайл», «флуд», «троллинг» и прочие термины, без которых мы не представляем интернет-сообщество.
Бернерс Ли выступает за реорганизацию интернета.
Сегодня Бернерс Ли активно выступает за открытость интернета. К локализации персональных данных пользователей своей страны и идеям суверенного интернета он относится скептически.
Тим говорит, что любое разделение сети на сегменты — очень плохая идея. Причина бурного развития Веба заключалась в том, что интернет был негосударственным, открытым и общедоступным
Потеря исходных файлов
Самой частой причиной является удаление сайта с хостинга хостер-провайдером за неуплату (не продление услуги). Так же бывает, что владелец сайта не имеет доступа к хостингу или почте на которую зарегистрирован хостинг-аккаунт, так как все доступы находятся у разработчика который внезапно пропал. В первую очередь, это вина заказчика. Всегда регистрируйте аккаунты на свою электронную почту, чтобы не потерять доступ и вовремя получать уведомления об оплате.
Еще частой причиной являются вирусы. Например у пользователя нет исходных файлов сайта, а то что «лежит» на сервере заражено вредоносной программой. Причем найти источник вируса бывает достаточно проблематично.
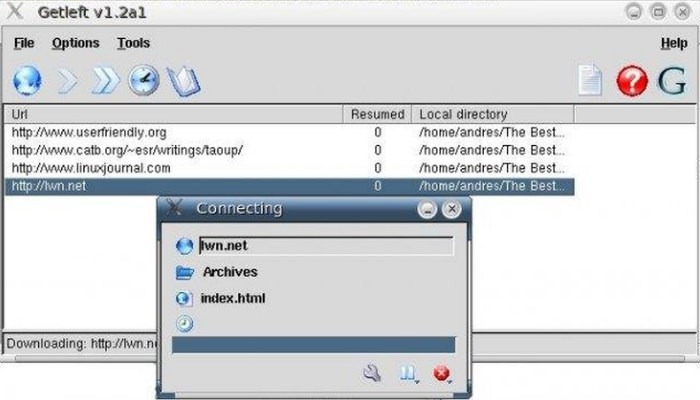
GetLeft
Этот граббер с открытым исходным кодом существует уже давно, и на это есть веские причины. GetLeft — это небольшая утилита, позволяющая загружать различные компоненты сайта, включая HTML и изображения.
GetLeft очень удобен для пользователя, что и объясняет его долговечность. Для начала просто запустите программу и введите URL-адрес сайта, затем GetLeft автоматически анализирует веб-сайт и предоставит вам разбивку страниц, перечисляя подстраницы и ссылки. Затем вы можете вручную выбрать, какие части сайта вы хотите загрузить, установив соответствующий флажок.
После того, как вы продиктовали, какие части сайта вы хотите зазрузить, нажмите на кнопку. GetLeft загрузит сайт в выбранную вами папку. К сожалению, GetLeft не обновлялся какое-то время.
Спасибо, что читаете! Подписывайтесь на мои каналы в Telegram, и . Только там последние обновления блога и новости мира информационных технологий.
Респект за пост! Спасибо за работу!
Хотите больше постов? Узнавать новости технологий? Читать обзоры на гаджеты? Для всего этого, а также для продвижения сайта, покупки нового дизайна и оплаты хостинга, мне необходима помощь от вас, преданные и благодарные читатели. Подробнее о донатах читайте на специальной странице.
Есть возможность стать патроном, чтобы ежемесячно поддерживать блог донатом, или воспользоваться Яндекс.Деньгами, WebMoney, QIWI или PayPal:
Заранее спасибо! Все собранные средства будут пущены на развитие сайта. Поддержка проекта является подарком владельцу сайта.
Twitter (март 2006): привет из девяностых
Даже сервис микроблоггинга Twitter использовал Flash в силу отсутствия достойной альтернативы. И если его суть за одиннадцать с лишним лет практически не изменилась, дизайн даже близко перестал напоминать первоначальный «привет из 1990-х», став максимально лёгким. И, конечно, в логотипе появилась знаменитая птичка.

Ноябрь 2006
Apple.com (1992 год): когда яблочко падает далеко от яблони
Для мегакорпорации Apple в 1990-х Интернет был скорее вспомогательной, нежели целевой площадкой. Только в «нулевых» с развитием iTunes ситуация изменилась. Тем не менее, даже без Стива Джобса (к тому моменту покинувшего Apple и ещё не вернувшегося) компания старалась использовать это перспективное направление для создания собственной экосистемы.

1992 год
Правда, дизайн и наполнение сайта до возвращения Джобса к родным пенатам говорят о том, что попытки провалились. Apple.com превратился в заурядную площадку, полностью потеряв свою идентичность — равно как и вся компания.

Апрель 1997
Как архивировать фото, видео и Истории
Чтобы добавить какой-либо медиафайл в Архив, пользователь должен:
- Открыть публикацию на своей странице – нажать три точки сверху.
- В выпадающем меню: «Архивировать».
После, можно посмотреть архивированные фото перейдя в соответствующий раздел. Найти архив с заранее архивированными фото в Инстаграме проще по датам и снимку, который был добавлен.
С помощью такой функции, в памяти учетной записи сохраняются фотографии сроком более одного года. Вернуть архивированные фото в Инстаграме возможно в любой момент, когда пользователь захочет разнообразить Ленту.
В настройках Истории доступно два параметра: сохранять в Архив и на смартфона. Но все публикации, которые ранее не были отмечены как архивируемые, добавлены в раздел не будут. Их нельзя восстановить или найти в Архиве Инстаграма.
В Архив можно добавить:
- фотографии. Публикации из Ленты с описанием, геолокацией и комментариями;
- Stories. Любые записи: начиная от целого набора коротких видео и заканчивая изображениями;
- видео. Вне зависимости от продолжительности и качества;
- карусели. Фото и видео альбомы, которые были добавлены на страницу.
При архивировании сохраняются лайки и комментарии. Но информация из статистики будет утеряна. Восстанавливая архивированные фото в Инстаграме, информация о количестве ранее просмотревших удаляется.