Html кодировка. в какую кодировку сохранять web-страницу
Содержание:
- Введение
- Работа с кодировкой текста
- Недостатки и достоинства
- Исправляем проблему с кодировкой с помощью смены кодировки
- Что такое кодировка сайта и как она работает
- Консоль Внедренца v.3.6.2
- Изменение кодировки по умолчанию
- Подробное описание
- Htaccess
- Выбор подходящей кодировкиChoosing the right encoding
- Что такое кодировка UTF-8
- Неправильная кодировка HTML страниц
- Неправильная кодировка результатов из базы данных MySQL
- Зачем нужна кодировка
- Комментарии
- Как определить кодировку файла или строки. Как конвертировать файлы в кодировку UTF-8 в Linux
- Изменение кодировки в Linux
Введение
Консольные приложения до сих пор остаются наиболее востребованным видом приложений, большинство разработчиков оттачивают архитектуру и бизнес-логику именно в консоли. При этом они нередко сталкиваются с проблемой локализации — русский текст, который вполне адекватно отражается в исходном файле, при выводе на консоль приобретает вид т.н. «кракозябр».
В целом, локализация консоли Windows при наличии соответствующего языкового пакета не представляется сложной. Тем не менее, полное и однозначное решение этой проблемы, в сущности, до сих пор не найдено. Причина этого, главным образом, кроется в самой природе консоли, которая, являясь компонентом системы, реализованным статическим классом System.Console, предоставляет свои методы приложению через системные программы-оболочки, такие как командная строка или командный процессор (cmd.exe), PowerShell, Terminal и другие. По сути, консоль находится под двойным управлением — приложения и оболочки, что является потенциально конфликтной ситуацией, в первую очередь в части использования кодировок.
Данный материал не предлагает строгий алгоритм действий, а направлен на описание узловых проблем, с которыми неизбежно сталкивается разработчик локализованного консольного приложения, а также некоторые возможные пути их разрешения. Предполагается, что это позволит разработчику сформировать стратегию работы с локализованной консолью и эффективно реализовать существующие технические возможности, большая часть которых хорошо описана и здесь опущена.
Работа с кодировкой текста
Кодировка текста – эта набор электронных цифровых выражений, которые преобразуются в понятные для пользователя символы. Существует много видов кодировки, у каждого из которых имеются свои правила и язык. Умение программы распознавать конкретный язык и переводить его на понятные для обычного человека знаки (буквы, цифры, другие символы) определяет, сможет ли приложение работать с конкретным текстом или нет. Среди популярных текстовых кодировок следует выделить такие:
Последнее наименование является самым распространенным среди кодировок в мире, так как считается своего рода универсальным стандартом.
Чаще всего, программа сама распознаёт кодировку и автоматически переключается на неё, но в отдельных случаях пользователю нужно указать приложению её вид. Только тогда оно сможет корректно работать с кодированными символами.

Наибольшее количество проблем с расшифровкой кодировки у программы Excel встречается при попытке открытия файлов CSV или экспорте файлов txt. Часто, вместо обычных букв при открытии этих файлов через Эксель, мы можем наблюдать непонятные символы, так называемые «кракозябры». В этих случаях пользователю нужно совершить определенные манипуляции для того, чтобы программа начала корректно отображать данные. Существует несколько способов решения данной проблемы.
Способ 1: изменение кодировки с помощью Notepad++
К сожалению, полноценного инструмента, который позволял бы быстро изменять кодировку в любом типе текстов у Эксель нет. Поэтому приходится в этих целях использовать многошаговые решения или прибегать к помощи сторонних приложений. Одним из самых надежных способов является использование текстового редактора Notepad++.
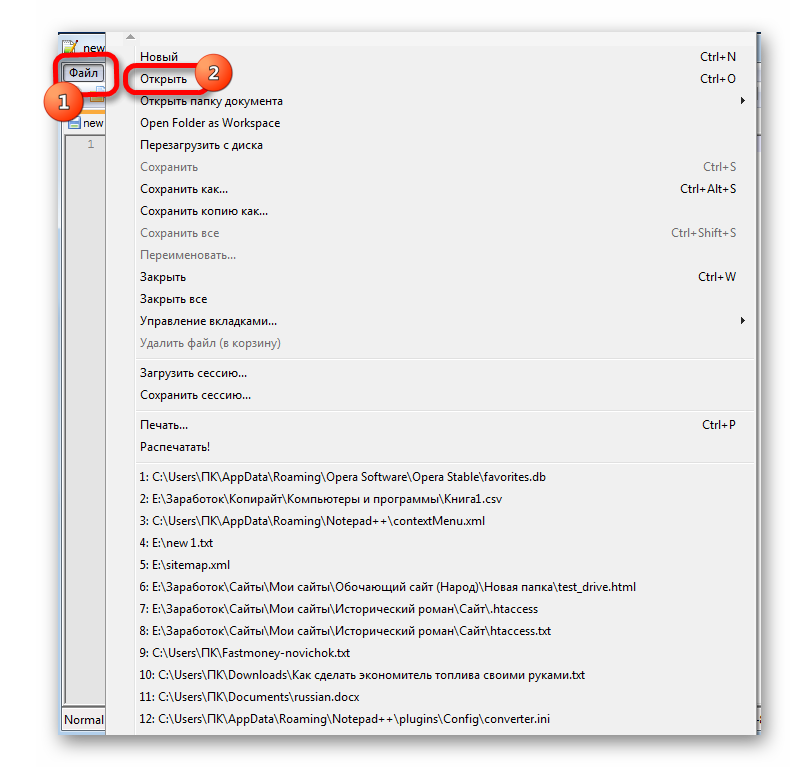




Несмотря на то, что данный способ основан на использовании стороннего программного обеспечения, он является одним из самых простых вариантов для перекодировки содержимого файлов под Эксель.
Способ 2: применение Мастера текстов
Кроме того, совершить преобразование можно и с помощью встроенных инструментов программы, а именно Мастера текстов. Как ни странно, использование данного инструмента несколько сложнее, чем применение сторонней программы, описанной в предыдущем методе.

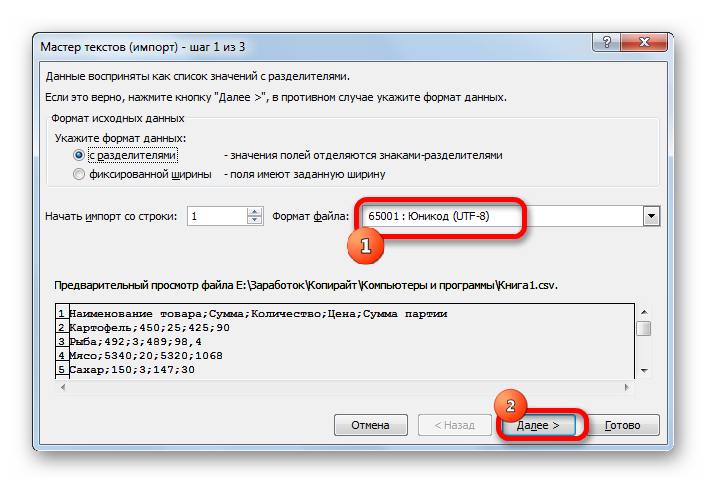
Переходим в директорию размещения импортируемого файла, выделяем его и кликаем по кнопке «Импорт».

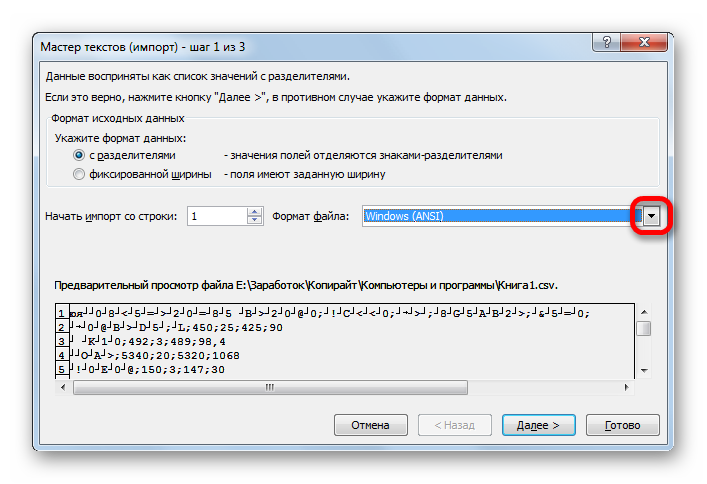
Если данные отображаются все равно некорректно, то пытаемся экспериментировать с применением других кодировок, пока текст в поле для предпросмотра не станет читаемым. После того, как результат удовлетворит вас, жмите на кнопку «Далее».
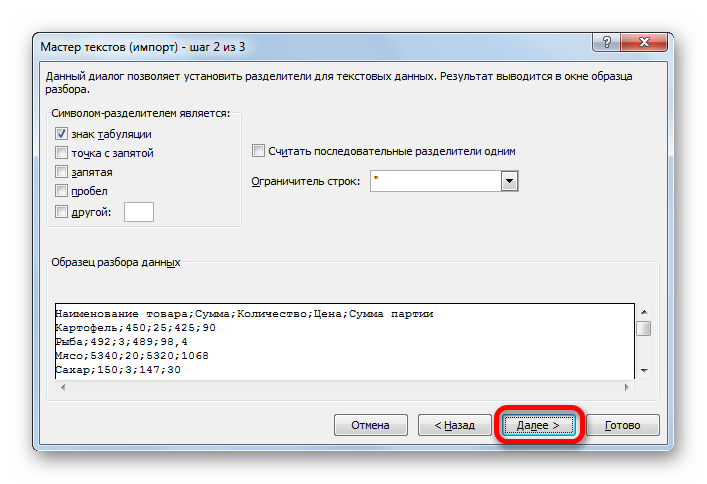
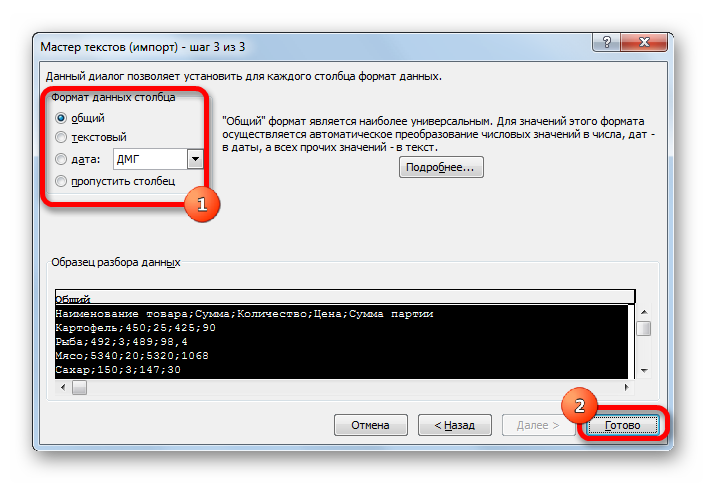
Тут настройки следует выставить, учитывая характер обрабатываемого контента. После этого жмем на кнопку «Готово».


Способ 3: сохранение файла в определенной кодировке
Бывает и обратная ситуация, когда файл нужно не открыть с корректным отображением данных, а сохранить в установленной кодировке. В Экселе можно выполнить и эту задачу.


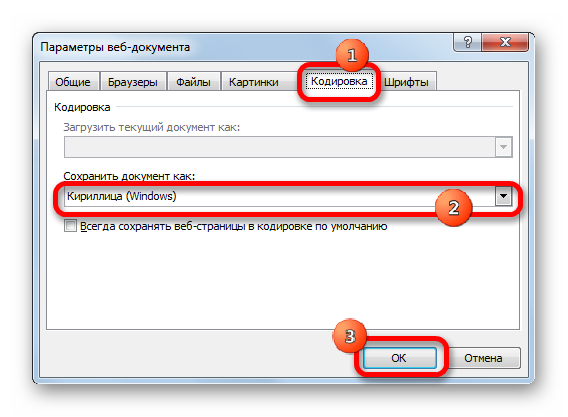

Документ сохранится на жестком диске или съемном носителе в той кодировке, которую вы определили сами. Но нужно учесть, что теперь всегда документы, сохраненные в Excel, будут сохраняться в данной кодировке. Для того, чтобы изменить это, придется опять заходить в окно «Параметры веб-документа» и менять настройки.
Существует и другой путь к изменению настроек кодировки сохраненного текста.


Теперь любой документ, сохраненный в Excel, будет иметь именно ту кодировку, которая была вами установлена.
Как видим, у Эксель нет инструмента, который позволил бы быстро и удобно конвертировать текст из одной кодировки в другую. Мастер текста имеет слишком громоздкий функционал и обладает множеством не нужных для подобной процедуры возможностей. Используя его, вам придется проходить несколько шагов, которые непосредственно на данный процесс не влияют, а служат для других целей. Даже конвертация через сторонний текстовый редактор Notepad++ в этом случае выглядит несколько проще. Сохранение файлов в заданной кодировке в приложении Excel тоже усложнено тем фактом, что каждый раз при желании сменить данный параметр, вам придется изменять глобальные настройки программы.
Источник
Недостатки и достоинства
UTF-8, в отличие от windows-1251 универсальная кодировка, в ней содержатся буквы различных алфавитов. Существует даже UTF-128, где есть вообще все языки – теулу, суахили, лаосский, мальтийский и так далее.

UTF-8 победнее, буквы занимают в разы меньше места и занимают всего один байт памяти, как и в 1251. В УТФ есть редкие символы из других языков или специальные символы. Они-то и весят по 5-6 байтов, но в документе используются крайне редко.
Когда вы создаете html документ для сайта, то указываете браузерам на какую таблицу им обращать внимание при расшифровке записей. Для этого необходимо вставить в тег head следующие данные
После символов «charset=» идет либо утф, либо виндовс, как в примере ниже
Для этого необходимо вставить в тег head следующие данные. После символов «charset=» идет либо утф, либо виндовс, как в примере ниже.
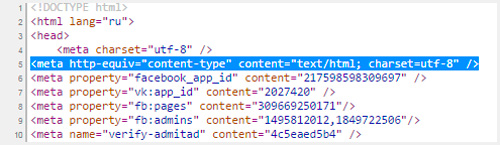
Если в дальнейшем вы захотите что-то поменять и вставить фразу на албанском, используя эту таблицу расшифровок, то ничего не получится, ведь этого языка кодировка не поддерживает. UTF‑8 без проблем позволит вам это сделать.
Если вас заинтересовало правильное создание сайта, то я могу порекомендовать вам курс Михаила Русакова « Создание и Раскрутка сайта от А до Я ».

Он содержит в себе очень много – 256 уроков, затрагивающих HTML, CSS, JavaScript, PHP, MySQL и XML. Помимо языков программирования вы сможете понять как монетизировать сайт, то есть скорее и больше получать прибыль. Один из немногих курсов, в котором было бы так подробно разъяснено все, что нужно.
Сам я вот уже год обучаюсь в школе блоггеров Александра Борисова . Это занимает в разы больше времени, конца и края пока не видно, но зато не менее исчерпывающе и дисциплинирует. Мотивирует продолжать разработку.
Ну а если возникают вопросы, не нужно искать по интернету. Всегда есть грамотный наставник.

Что-то я отошел от темы. Давайте вернемся к кодировкам.
Исправляем проблему с кодировкой с помощью смены кодировки
Вместо смены шрифта, можно сменить кодировку, которая используется при работе cmd.exe. Узнать текущую кодировку можно введя в командной строке команду chcp , после ввода данной команды необходимо нажать Enter . 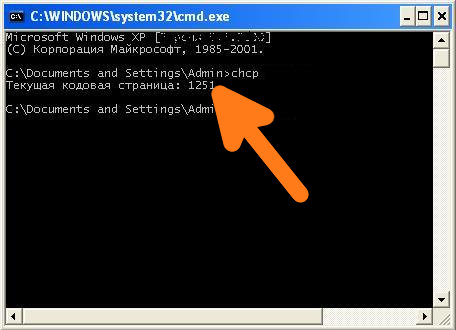
Как видно на скриншоте, текущая используемая кодировка Windows-1251
Для изменения кодировки нам необходимо воспользоваться командой chcp , где – это сам код кодировки, на которую мы хотим переключиться. Возможные значения:
- 1251 – Windows-кодировка (Кириллица);
- 866 – DOS-кодировка;
- 65001 – Кодировка UTF-8;
Т.е. для смены кодировки на DOS, команда примет следующий вид:
Для смены кодировки на UTF-8, команда примет следующий вид:
Для смены кодировки на Windows-1251, команда примет следующий вид:
Источник
Что такое кодировка сайта и как она работает
Кодировку можно представить в виде таблицы, состоящей из разных букв, цифр и других символов понятных человеку, которые закодированы определенным образом. Когда вы открываете текстовый файл, к которым относятся в том числе HTML-страницы, то компьютер считывает из заголовка файла в какой кодировке он был сохранен и выводит текст в соответствующей кодировке преобразовывая компьютерные данные в вид понятный человеку сопоставляя эти данные с таблицей кодировки. Если информация о кодировке из заголовка файла совпадает с кодировкой в которой сохранены данные в HTML-странице, то пользователь видит привычные ему буквы, цифры и другие символы. Если же есть несовпадение, то в результате пользователю выводится непонятный набор символов, особенно часто это происходит в старых почтовых программах. Если пользователь получил письмо с непонятными крякозябрами, то просто перебирая разные кодировки, обычно получается угадать и выбрать ту, в которой написано письмо, и в результате непонятный набор символов превращается в понятный человеку текст.
То же самое происходит и с HTML-страницами сайта. Если документ был сохранен, например, в кодировке UTF-8, а в самом документе прописан META-тег указывающий что это кодировка windows-1251, то браузер опять же будет сопоставлять сохраненные в файле данные с таблицей указанной ему кодировки и так как символы закодированы по-разному, то браузер выведет вместо привычного текста непонятный набор символов или же часть букв может быть в нормальном виде, а другие буквы или символы могут выводиться, например, в виде знаков вопроса. Все выше сказанное относится в том числе и к отображению имен файлов.
Создавая новый документ в текстовом редакторе лучше сразу убедиться что выбрана нужная кодировка. Современные редакторы позволяют преобразовать текст открытого документа из одной кодировки в другую, а стандартный Блокнот позволяет выбрать кодировку только при сохранении файла.
Консоль Внедренца v.3.6.2
Идея данной обработки заключается в создании простого, функционального и универсального инструментария для внедренцев и программистов 1С, который будет работать как в толстом клиенте на обычных и на управляемых формах, так и в тонком клиенте. Интерфейс и логика работы максимально идентичны у обычных форм и управляемых. Инструментарий включает в себя: Консоль кода, Консоль запросов, Консоль отчетов (СКД), Универсальную обработку объектов, Средства для работы с таблицами базы данных 1С, Редактирование регистров сведений базы, Инструмент по работе с табличными документами — загрузка данных из табличного документа.
1 стартмани
Изменение кодировки по умолчанию
В PowerShell есть две переменные по умолчанию, которые можно использовать для изменения поведения кодировки по умолчанию.
Дополнительные сведения см. в разделе about_Preference_Variables.
Начиная с PowerShell 5,1, операторы перенаправления ( и ) вызывают командлет. Таким образом, можно задать кодировку по умолчанию для них с помощью переменной предпочтений, как показано в следующем примере:
Используйте следующую инструкцию, чтобы изменить кодировку по умолчанию для всех командлетов, имеющих параметр Encoding .
Важно!
При размещении этой команды в профиле PowerShell предпочтение влияет на глобальные параметры сеанса, влияющие на все команды и скрипты, которые явно не задают кодировку.
Аналогичным образом следует включить такие команды в скрипты или модули, которые должны вести себя одинаково. Использование этих команд гарантирует, что командлеты ведут себя одинаково даже при запуске другого пользователя, на другом компьютере или в другой версии PowerShell.
Автоматическая переменная влияет на кодирование, используемое PowerShell для взаимодействия с внешними программами. Он не влияет на кодировку, которую операторы перенаправления вывода и командлеты PowerShell используют для сохранения в файлах.
Подробное описание
Юникод — это мировой стандарт кодировки символов. Система использует Юникод исключительно для обработки символов и строк. Подробное описание всех аспектов Юникода см. в стандарте Юникода.
Windows поддерживает Юникод и традиционные наборы символов. Традиционные кодировки, например кодовые страницы Windows, используют 8-разрядные значения или сочетания 8-разрядных значений для представления символов, используемых в определенном языке или географических регионах.
По умолчанию PowerShell использует набор символов Юникода. Однако несколько командлетов имеют параметр кодирования , который может указывать кодировку для другой кодировки. Этот параметр позволяет выбрать конкретную кодировку символов, необходимую для взаимодействия с другими системами и приложениями.
Следующие командлеты имеют параметр Encoding :
- Microsoft.PowerShell.Management
- Add-Content
- Get-Content
- Set-Content
- Microsoft.PowerShell.Utility
- Export-Clixml
- Export-Csv
- Export-PSSession
- Format-Hex
- Import-Csv
- Out-File
- Select-String
- Send-MailMessage
Htaccess
Если на сайте вы настойчиво решили использовать именно 1251, то вам следует найти или создать файл htaccess. Он отвечает за настройки конфигурации. В него придется добавить еще три строчки, чтобы все сошлось.
DefaultLanguage ru; AddDefaultCharset windows-1251; php_value default_charset “cp1251”
Я все же настоятельно рекомендую вам задумать о использовании UTF-8. Он более популярен, прост и богат
Какие бы решения вы не приняли сейчас, важно, чтобы впоследствии можно было все исправить. Добавить англоязычную версию сайта на этой кодировке будет в разы проще
Ничего не нужно исправлять.
Решение остается за вами. Подписывайтесь на рассылку, чтобы узнавать как можно быстрее создавать правильные сайты, где учиться, чтобы не повторять чужих ошибок, а также какие блоггеры получают больше посетителей.
До новых встреч и удачи в ваших начинаниях.
Выбор подходящей кодировкиChoosing the right encoding
Различные системы и приложения могут использовать различные кодировки:Different systems and applications can use different encodings:
- В .NET Standard, в Интернете и в среде Linux теперь в основном используется кодировка UTF-8.In .NET Standard, on the web, and in the Linux world, UTF-8 is now the dominant encoding.
- Во многих приложениях .NET Framework используется UTF-16.Many .NET Framework applications use UTF-16. По историческим причинам ее иногда называют «Юникод»; сейчас этот термин относится к более широкому стандарту, охватывающему UTF-8 и UTF-16.For historical reasons, this is sometimes called «Unicode», a term that now refers to a broad standard that includes both UTF-8 and UTF-16.
- В Windows многие приложения, которые были созданы еще до распространения Юникода, по-прежнему могут по умолчанию использовать Windows-1252.On Windows, many native applications that predate Unicode continue to use Windows-1252 by default.
Кодировки Юникода также используют понятие метки порядка следования байтов (BOM).Unicode encodings also have the concept of a byte-order mark (BOM). BOM ставится в начале текста, чтобы декодер мог определить, какая кодировка используется в тексте.BOMs occur at the beginning of text to tell a decoder which encoding the text is using. Для многобайтовых кодировок BOM также указывает порядок следования байтов кодировки.For multi-byte encodings, the BOM also indicates endianness of the encoding. BOM представляются байтами, которые редко встречаются в тексте в Юникоде. Это позволяет сделать обоснованное предположение, что текст записан в Юникоде, если присутствует метка BOM.BOMs are designed to be bytes that rarely occur in non-Unicode text, allowing a reasonable guess that text is Unicode when a BOM is present.
BOM не являются обязательными; в мире Linux они не так популярны, поскольку во всех прочих местах используется надежное соглашение UTF-8.BOMs are optional and their adoption isn’t as popular in the Linux world because a dependable convention of UTF-8 is used everywhere. Большинство приложений Linux предполагают, что текстовый ввод кодируется в UTF-8.Most Linux applications presume that text input is encoded in UTF-8. Хотя многие приложения Linux могут распознавать и правильно обрабатывать BOM, некоторые этого не делают, что приводит к появлению артефактов в тексте, открываемом с помощью этих приложений.While many Linux applications will recognize and correctly handle a BOM, a number do not, leading to artifacts in text manipulated with those applications.
Таким образом :Therefore :
- Если вы работаете в основном с приложениями Windows и Windows PowerShell, следует предпочтительно использовать такие кодировки, как UTF-8 с BOM или UTF-16.If you work primarily with Windows applications and Windows PowerShell, you should prefer an encoding like UTF-8 with BOM or UTF-16.
- Если вы работаете на разных платформах, следует отдавать предпочтение UTF-8 с BOM.If you work across platforms, you should prefer UTF-8 with BOM.
- Если вы работаете главным образом в контексте Linux, следует отдавать предпочтение UTF-8 без BOM.If you work mainly in Linux-associated contexts, you should prefer UTF-8 without BOM.
-
Windows-1252 и latin-1 — устаревшие кодировки, которых по возможности следует избегать.Windows-1252 and latin-1 are essentially legacy encodings that you should avoid if possible.
Тем не менее некоторые приложения предыдущих версий в Windows зависят от их.However, some older Windows applications may depend on them. - Также стоит отметить, что подписывание скриптов зависит от кодировки, то есть изменение кодировки в подписанном скрипте потребует повторного подписывания.It’s also worth noting that script signing is encoding-dependent, meaning a change of encoding on a signed script will require resigning.
Что такое кодировка UTF-8
UTF-8 – в настоящее время распространённая кодировка, реализующая представление Юникода, совместимое с 8-битным кодированием текста. Нашла широкое применение в операционных системах и веб-пространстве. Текст, состоящий только из символов Юникода с номерами меньше 128, при записи в UTF-8 превращается в обычный текст ASCII. Остальные символы Юникода изображаются последовательностями длиной от 2 до 6 байт.
Символ в кодировке UTF-8 может кодироваться аж 6 байтами (пока используется только 4 и больше не планируется). Для русского языка, например, символ занимает 2 байта. Все символы, которые есть в таблице символов – поддерживаются этой кодировкой. К примеру, если вам нужен знак копирайта (), то вам не нужно искать особый шрифт или же изображать символов в графическом формате.
Неправильная кодировка HTML страниц
Создадим тестовый файлик:
sudo gedit /var/www/html/encoding.html
Скопируем в него следующий HTML код, в котором отсутствует указание кодировки и посмотрим, какие проблемы могут с ним возникнуть и как их решить:
<html>
<head>
<title>Проверка кодировки</title>
</head>
<body>
<h1>Тестовый файл для проверки кодировки</h1>
</body>
</html>
Откроем этот файл в браузере http://localhost/encoding.html
Как можно видеть, кодировка браузером определена неправильно:
Имеется несколько способов исправить эту ситуацию. Начнём с самого простого – явно указать кодировку для веб-страницы. Это делается метатегом, который должен быть расположен внутри тэга head:
<meta http-equiv="content-type" content="text/html; charset=utf-8" />
Добавим эту строку к нашему тестовому файлику, чтобы получилось так:
<html>
<head>
<title>Проверка кодировки</title>
<meta http-equiv="content-type" content="text/html; charset=utf-8" />
</head>
<body>
<h1>Тестовый файл для проверки кодировки</h1>
</body>
</html>
Как мы можем убедиться на следующем скриншоте, проблема решена:
Если кодировка вашего файла отличается от UTF-8, то вместо неё поставьте windows-1251 или ту, которая соответствует кодировке веб-страницы. Чтобы научиться определять кодировку файлов, посмотрите эту инструкцию.
Это был самый простой способ исправления проблемы с кодировкой – без изменения настроек сервера.
Вернём наш тестовый файл в исходное состояние и продолжим изучение способов указания кодировки.
Если файлы .htaccess включены настройками Apache, то эти файлы можно использовать чтобы указывать кодировку отправляемых веб-сервером страниц. Чтобы включить поддержку файлов .htaccess в конфигурационном файле Apache ( /etc/apache2/apache2.conf ) найдите группу строк
<Directory /var/www/> Options Indexes FollowSymLinks AllowOverride None Require all granted </Directory>
И в ней замените
AllowOverride None
на
AllowOverride All
После этого сервер нужно перезапустить.
sudo systemctl restart apache2.service
Файл .htaccess должен быть размещён в той же директории, что и сайт. Мой сайт размещён в корневой директории веб-сервера. Если у вас также, то теперь в папке /var/www/html/ создайте файл .htaccess и добавьте в него директиву AddDefaultCharset после которой укажите желаемую кодировку. Примеры
AddDefaultCharset UTF-8
ИЛИ
AddDefaultCharset windows-1251
Можно указать кодировку, которая будет применена только к файлам определённого формата:
AddCharset utf-8 .atom .css .js .json .rss .vtt .xml
Набор файлов может быть любым, например:
AddCharset utf-8 .html .css .php .txt .js
Следующий вариант является альтернативным и также позволяет устанавливать кодировку для файлов определённого типа, для него нужно, чтобы был включён mod_headers:
<Files ~ "\.html?$">
Header set Content-Type "text/html; charset=utf-8"
</Files>
Ещё один вариант, который также можно использовать в файле .htaccess для установки кодировки UTF-8:
IndexOptions +Charset=utf-8
Если сайт на PHP, то дополнительно может понадобиться продублировать кодировку с php_value default_charset:
AddDefaultCharset windows-1251 php_value default_charset "cp1251"
Можно вместо создания файла .htaccess установить кодировку в конфигурационном файле веб-сервера. Для Apache CentOS/Fedora это файл httpd.conf, а на Debian/Ubuntu это файл apache2.conf. Добавьте следующую строку для установки кодировки и перезапустите веб-сервер, чтобы изменения вступили в силу:
AddDefaultCharset UTF-8
Неправильная кодировка результатов из базы данных MySQL
Если ваш сайт состоит из статической части (шаблон) и динамической, которая формируется из данных, получаемых из базы данных, то может возникнуть ситуация, когда часть сайта имеет правильную кодировку, а другая часть сайта имеет неправильную. В этом случае бесполезно менять настройки веб-сервера – поскольку всё равно часть страницы будет иметь неправильную кодировку.
Нужно начать с определения кодировки ваших таблиц. Можно посмотреть в phpMyAdmin:
Обратите внимание на столбец «Сравнение», запись «utf8_unicode_ci» означает, что используется кодировка UTF-8.
Можно подключиться к СУБД MySQL и проверить кодировку таблиц без phpMyAdmin. Для этого:
mysql -u root -p
Если вы забыли имя базы данных, то выполните команду:
SHOW DATABASES;
Предположим, я хочу посмотреть кодировку для таблиц в базе данных information_schema
USE information_schema;
Если вы забыли имя таблиц, выполните:
SHOW TABLES;
Далее выполните команду, в которой имя_таблицы замените на настоящее имя таблицы:
SHOW FULL COLUMNS FROM имя_таблицы;
Например:
SHOW FULL COLUMNS FROM GLOBAL_STATUS;
Вы увидите примерно следующее:
Смотрите столбец Collation. В моём случае там utf8_general_ci, это, как и utf8_unicode_ci, кодировка UTF-8. Кстати, если вы не знаете в чём разница между кодировками utf8_general_ci, utf8_unicode_ci, utf8mb4_general_ci, utf8mb4_unicode_ci, а также какую кодировку выбрать для базы данных MySQL, то посмотрите эту статью.
Теперь, когда мы узнали кодировку (в моём случае это UTF-8), то при каждом подключении к СУБД MySQL нужно выполнять последовательно запросы:
SET NAMES UTF8 SET CHARACTER SET UTF8 SET character_set_client = UTF8 SET character_set_connection = UTF8 SET character_set_results = UTF8
В PHP это можно сделать примерно так:
$this->mysqli = new mysqli($server, $username, $password, $basename);
if ($this->mysqli->connect_error) {
$this->errorHandler_c->logError(1, 'Connect Error (' . $this->mysqli->connect_errno . ') ' . $this->mysqli->connect_error, $_SERVER );
}
$this->mysqli->query("SET NAMES UTF8");
$this->mysqli->query("SET CHARACTER SET UTF8");
$this->mysqli->query("SET character_set_client = UTF8");
$this->mysqli->query("SET character_set_connection = UTF8");
$this->mysqli->query("SET character_set_results = UTF8");
Обратите внимание, что UTF8 вам нужно заменить на ту кодировку, которая используется для ваших таблиц.
Зачем нужна кодировка
Кодировка (Charset) — способ отображения кода на экране, соответствие набора символов набору числовых значений. О ней сообщает строка Content-Type и сервер в header запросе.
Студентка списывала реферат с формулами, а на сайте слетела кодировка. Реальная история
Google рекомендует всегда указывать сведения о кодировке, чтобы текст точно корректно отображался в браузере пользователя.
Кодировка влияет на SEO?
Разберемся, как кодировка на сайте влияет на индексацию в Яндекс и Google.
Яндекс четко заявляет:
Позиция Google такая же. Поисковики не рассматривают Charset как фактор ранжирования или сигнал для индексирования, тем не менее, она косвенно влияет на трафик и позиции.
Если кодировка сервера не совпадает с той, что указана на сайте, пользователи увидят нечитабельные символы вместо контента. На таком сайте сложно что-либо понять, так что скорее всего пользователи сбегут, а на сайте будут расти отказы.
Пример страницы со слетевшей кодировкой
Поэтому она важна для SEO, хоть и влияет на него косвенно через поведенческие. Пользователи должны видеть читабельный текст на человеческом языке, чтобы работать с сайтом.
Комментарии
Добрый день! Необходимо конвертировать текст из ASCII (отрезанный старший бит) в Windows-1251. Каким образом можно модифицировать макрос для решения задачи?
Добрый день. Парни, есть такая проблема, сам я из Казахстана, юзер пишет текст в ворде, например слово «СЛОВО», где буква С была написана на англ.языке, а все остальное слово на русском, или есть такие слова где русский язык и казахский (с казахской клавиатуры). Теперь при проверке на плагиат выходит ошибка кодировки, программа не понимает таких слов из двух или более языков, посоветуйте пожалуйста выход из такой ситуации, слышал что можно с помощью макросов, вот только с макросами не дружу, но в целом с понятия имею.
Огромное СПАСИБО за такой функционал! Полдня истратил, пока нашел, как же из Excel перевести данные в UTF-8. И тут такой подарок! Это просто супер!
Здравствуйте, подскажите как пересохранить xls файл в формат csv с кодировкой utf8 без BOM разделитель ; с именем исходного файла
Алексей, ну есть же в конце статьи отдельная функция для вашего случая. Вызывается так:
Скажите пожалуйста, хотелось бы на выходе получить файл в кодировке UTF-8 без BOM вызываю так: ChangeFileCharset filename, «UTF-8», «Windows-1251» все нормально, но файл получается UTF-8 а хотелось бы UTF-8 без BOM Это возможно? Если да, то как указать во втором параметре вызова функции?
Здравствуйте, Павел В общем случае, кодировку txt файла никак не угадать (не проверить) Можно лишь попробовать угадать, анализируя первые байты текста (правда, верно угадать можно с вероятностью, очень близкой к 100%)
Изменить кодировку без перезаписи файла — никак. Смена кодировки текстового файла — это изменение байтового представления этого текста (после перекодировки, файл может увеличиться или уменьшаться в размере в 2 раза)
Готовый макрос предложить не могу (ни разу подобное не делал, и кода немало получится)
Варианты решения проблемы: 1) ручная обработка, при помощи текстового редактора Notepad++ В нём можно открыть сразу кучу файлов, а потом, переключаясь между ними, смотреть текущую кодировку, и, при необходимости, перекодировать одним нажатием кнопки (см. меню Кодировки в Notepad++)
У меня почему-то при кодировании анси в уникод, не прокатил параметр «utf-8», а получилось только с «Unicode».
Источник
Как определить кодировку файла или строки. Как конвертировать файлы в кодировку UTF-8 в Linux
В этой инструкции мы опишем что такое кодировка символов и рассмотрим несколько примеров конвертации файлов из одной кодировки в другую с использованием инструмента командной строки. Наконец, мы узнаем, как на Linux конвертировать несколько файлов из одного набора символов (charset) в UTF-8 кодировку.
Возможно, вы уже в курсе, что компьютер не понимает и не сохраняет буквы, числа или что-то ещё чем обычно оперируют люди. Компьютер работает с битами. Бит имеет только два возможных значения: 0 или 1, «истина» или «ложь», «да» или «нет». Все другие вещи, вроде букв, цифр, изображений должны быть представлены в битах, чтобы компьютер мог их обрабатывать.
Говоря простыми словами, кодировка символов – это способ информирования компьютера о том, как интерпретировать исходные нули и единицы в реальные символы, где символ представлен набором чисел. Когда мы печатаем текст в файле, слова и предложения, которые мы формируем, готовятся из разных символов, а символы упорядочиваются в кодировку.
Имеются различные схемы кодирования, среди них такие как ASCII, ANSI, Unicode. Ниже пример ASCII кодировки.
Изменение кодировки в Linux
Использование команды iconv
В Linux для конвертации текста из одной кодировки в другую используется команда iconv.
Синтаксис использования iconv имеет следующий вид:
Где -f или —from-code означает кодировку исходного файла -t или —to-encoding указывают кодировку нового файла. Флаг -o является необязательным, если его нет, то содержимое документа в новой кодировке будет показано в стандартном выводе.
Чтобы вывести список всех кодировок, запустите команду:
Конвертирование файлов из windows-1251 в UTF-8 кодировку
Далее мы научимся, как конвертировать файлы из одной схемы кодирования (кодировки) в другую. В качестве примера наша команда будет конвертировать из windows-1251 (которая также называется CP1251) в UTF-8 кодировку.
Допустим, у нас есть файл mypoem_draft.txt его содержимое выводится как
Мы начнём с проверки кодировки символов в файле, просмотрим содержимое файла, выполним конвертирование и просмотрим содержимое файла ещё раз.

Примечание: если к кодировке, в который мы конвертируем файл добавить строку //IGNORE, то символы, которые невозможно конвертировать, будут отбрасываться и после конвертации показана ошибка.
Если к конечной кодировке добавляется строка //TRANSLIT, конвертируемые символы при необходимости и возможности будут транслитерированы. Это означает, когда символ не может быть представлен в целевом наборе символов, он может быть заменён одним или несколькими выглядящими похоже символами. Символы, которые вне целевого набора символов и не могут быть транслитерированы, в выводе заменяются знаком вопроса (?).
Изменение кодировки программой enca
Программа enca не только умеет определять кодировку, но и может конвертировать текстовые файлы в другую кодировку. Особенностью программы является то, что она не создаёт новый файл, а изменяет кодировку в исходном. Желаемую кодировку нужно указать после ключа -x:
Конвертация строки в правильную кодировку
Команда iconv может конвертировать строки в нужную кодировку. Для этого строка передаётся по стандартному вводу. Достаточно использовать только опцию -f для указания кодировки, в которую должна быть преобразована строка. Т.е. используется команда следующего вида:

Также для изменения кодировки применяются программы:
Источник