Правильный robots.txt или как понравиться поисковым системам
Содержание:
- Для чего предназначен?
- Три закона робототехники Айзека Азимова
- Как поисковики сканируют страницу
- Другие примеры роботов-«роверов»
- Что такое robots.txt
- Для чего нужен robots.txt
- Как работают поисковые роботы и как они обрабатывают данный файл
- Для чего нужна проверка robots.txt
- Написание и проверка robots.txt
- Как создать robots.txt
- Robots.txt для WordPress
- Используемые директивы
- Операторы в robots.txt
- Technical robots.txt syntax
Для чего предназначен?
В предисловии я уже описал, что это такое. Теперь расскажу, зачем он нужен. Robots.txt – небольшой текстовой файл, который хранится в корне сайта. Он используется поисковыми системами. В нем четко прописаны правила индексации, т. е. какие разделы сайта нужно индексировать (добавлять в поиск), а какие – нет.

Обычно от индексации закрываются технические разделы сайта. Изредка в черный список попадают неуникальные страницы (копипаст политики конфиденциальности тому пример). Здесь же “роботам объясняются” принципы работы с разделами, которые нужно индексировать. Очень часто прописывают правила для нескольких роботов отдельно. Об этом мы и поговорим далее.
При правильной настройке robots.txt ваш сайт гарантированно вырастет в позициях поисковых систем
Роботы будут учитывать только полезный контент, обделяя вниманием дублированные или технические разделы
Три закона робототехники Айзека Азимова
Классик мировой фантастики сформулировал три основных правила поведения роботов, которые в теории должны быть заложены в роботах на уровне инстинктов. Они приписывали роботам некоторые ограничения действий, которые наделяли механизмы эмоциональной составляющей.
Появление законов
До формулирования трёх законов робототехники вся научная фантастика преподносила роботов как нечто угрожающее существованию человека. В произведениях часто встречался сюжет истребления роботами человечества. Азимов же, в своих рассказах пописывал устройства наделённые качествами, напоминающими совесть, честность, преданность.
В 1940 году беседа Азимова с его другом Джоном Кэмпбеллом по поводу последних новостей научной фантастики закончилась описанием трёх постулатов. По словам Кэмпбелла, он извлёк их из уже существующих произведений Айзека.
Значение законов
Обязательные правила поведения для всех роботов подчёркивают главенство человека над созданными им механизмами. Основной посыл заключен в приоритетной безопасности любого действия или бездействия устройства.

Однажды, в 1986 году в романе «Роботы и Империя» Айзек Азимов добавил нулевой закон. Добавление дополнительно закона обосновано его приоритетностью относительно остальных.
Нулевой закон утверждает, что действия робота должны быть направлены на интересы человечества, а не только отдельно взятого человека.
Таким образом, первоначальное и неотъемлемое значение робота — быть безоговорочным помощником человека, служить в интересах науки и всего человечества!
Как поисковики сканируют страницу
Роботы-краулеры Яндекса и Google посещают страницы сайта, оценивают содержимое, добавляют новые ресурсы и информацию о страницах в индексную базу поисковика. Боты посещают страницы регулярно, чтобы переносить в базу обновления контента, отмечать появление новых ссылок и их доступность.
Зачем нужно сканирование:
- Собрать данные для построения индекса — информацию о новых страницах и обновлениях на старых.
- Сравнить URL в индексе и в списке для сканирования.
- Убрать из очереди дублирующиеся URL, чтобы не скачивать их дважды.
Боты смотрят не все страницы сайта. Количество ограничено
краулинговым бюджетом, который складывается из количества URL, которое может просканировать бот-краулер. Бюджета на объемный сайт может не хватить. Есть риск, что краулинговый бюджет уйдет на сканирование неважных или «мусорных» страниц, а чтобы такого не произошло, веб-мастеры направляют краулеров с помощью файла robots.txt.
Боты переходят на сайт и находят в корневом каталоге файл robots.txt, анализируют доступ к страницам и переходят к карте сайта —
Sitemap, чтобы сократить время сканирования, не обращаясь к закрытым ссылкам. После изучения файла боты идут на главную страницу и оттуда переходят в глубину сайта.
Какие страницы краулер просканирует быстрее:
-
Находятся ближе к главной.
Чем меньше кликов с главной ведет до страницы, тем она важнее и тем вероятнее ее посетит краулер. Количество переходов от главной до текущей страницы называется Click Distance from Index (DFI). -
Имеют много ссылок.
Если многие ссылаются на страницу, значит она полезная и имеет хорошую репутацию. Нормальным считается около 11-20 ссылок на страницу, перелинковка между своими материалами тоже считается. -
Быстро загружаются.
Проверьте скорость загрузки
инструментом, если она медленная — оптимизируйте код верхней части и уменьшите вес страницы.
Все посещения ботов-краулеров не фиксируют такие инструменты, как Google Analytics, но поведение ботов можно отследить в лог-файлах. Некоторые SEO-проблемы крупных сайтов можно решить с помощью
анализа лог-файлов который также поможет увидеть проблемы со ссылками и распределение краулингового бюджета.
Другие примеры роботов-«роверов»
В 2017 г. компания Starship Technologies начала в США дорожные испытания самоходных роботов-курьеров для доставки продуктов питания от ресторанов прямо к дверям покупателей. Сначала они понравились далеко не всем покупателям — роботов заливали соусом и переворачивали, однако постепенно стартап смог распространить свою деятельность более чем на сто городов.
Amazon Scout
В 2019 г. в эксплуатацию был запущен шестиколесный робот Scout для доставки товаров от Amazon. В первоначальных испытаниях приняли участие шесть экземпляров Scout, и тестирование проходило в полевых условиях. Другими словами, Scout доставляли реальные товары реальным покупателям. В августе 2019 г. Amazon провел испытания роботов-курьеров в Калифорнии. Примечательно, что лидара на крыше у Scout нет.
В марте 2019 г. тестирование собственных роботов-курьеров развернула американская логистическая компания FedEx. Ее изобретение получило усовершенствованную подвеску, позволяющую ему буквально взбираться по лестницам, а аккумулятора роботу хватает на преодоление 16 км пути. Грузоподъемность такого дрона — 45 кг.
Что такое robots.txt
Robots.txt — файл, который говорит поисковой системе, какие разделы и страницы вашего сайта нужно включать в поиск, а какие — нельзя. Ну то есть он говорит не поисковой системе напрямую, а её роботу, который обходит все сайты интернета. Вот что такое роботс. Этот файл всегда создается в универсальном формате .txt, который сможет открыть даже компьютер вашего деда.
Вот видос от Яндекса:
Основное назначение – контроль за доступом к публикуемой информации. При необходимости определенную информацию можно закрыть для роботов. Стандарт robots был принят в начале 1994 года, но спустя десятилетие продолжает жить.
Использование стандарта осуществляется на добровольной основе владельцами сайтов. Файл должен включать в себя специальные инструкции, на основе которых проводится проверка сайта поисковыми роботами.
Самый простой пример robots:
User-agent: * Allow: /
Данный код открывает весь сайт, структура которого должна быть безупречной.
Зачем закрывают какие-то страницы? Не проще ли открыть всё?
Смотрите — у каждого сайта есть свой лимит, который называется краулинговый бюджет. Это максимальное количество страниц одного конкретного сайта, которое может попасть в индекс. То есть, допустим, у какого-нибудь М-Видео краулинговый бюджет может составлять десять миллионов страниц, а у сайта дяди Вани, который вчера решил продавать огурцы через интернет — всего сотню страниц. Если вы откроете для индексации всё, то в индекс, скорее всего, попадет куча мусора, и с большой вероятностью этот мусор займет в индексе место некоторых нужных страниц. Вот чтобы такой хрени не случилось, и нужен запрет индексации.
Где находится Robots
Robots традиционно загружают в корневой каталог сайта.
Это корневой каталог, и в нем лежит роботс.
Для загрузки текстового файла обычно используется FTP доступ. Некоторые CMS, например WordPress или Joomla, позволяют создавать robots из админпанели.
Для чего нужен robots.txt
Файл robots.txt создается для настройки правильной индексации сайта поисковым системам. То есть в нем содержатся правила разрешений и запретов на определенные пути вашего сайта или тип контента. Но это не панацея. Все правила в файле robots не являются указаниями точно им следовать, а просто рекомендация для поисковых систем. Google например пишет:
Поисковые роботы сами решают что индексировать, а что нет, и как себя вести на сайте. У каждого поисковика свои задачи и свои функции. Как бы мы не хотели, этим способ их не укротить.
Но есть один трюк, который не касается напрямую тематики этой статьи. Чтобы полностью запретить роботам индексировать и показывать страницу в поисковой выдаче, нужно написать:
<meta name="robots" content="noindex" />
Вернемся к robots. Правилами в этой файле можно закрыть или разрешить доступ к следующим типам файлов:
- Неграфические файлы. В основном это html файлы, на которых содержится какая-либо информация. Вы можете закрыть дубликаты страниц, или страницы, которые не несут никакой полезной информации (страницы пагинации, страницы календаря, страницы с архивами, страницы с профилями и т.д.).
- Графические файлы. Если вы хотите, чтобы картинки сайта не отображались в поиске, вы можете это прописать в файле robots.
- Файлы ресурсов. Также с помощью robots вы можете заблокировать индексацию различных скриптов, файлы стилей CSS и другие маловажные ресурсы. Но не стоит блокировать ресурсы, которые отвечают за визуальную часть сайта для посетителей (например, если вы закроете css и js сайта, которые выводят красивые блоки или таблицы, этого не увидит поисковой робот, и будет ругаться на это).
Чтобы наглядно показать, как работает robots, посмотрите на картинку ниже:
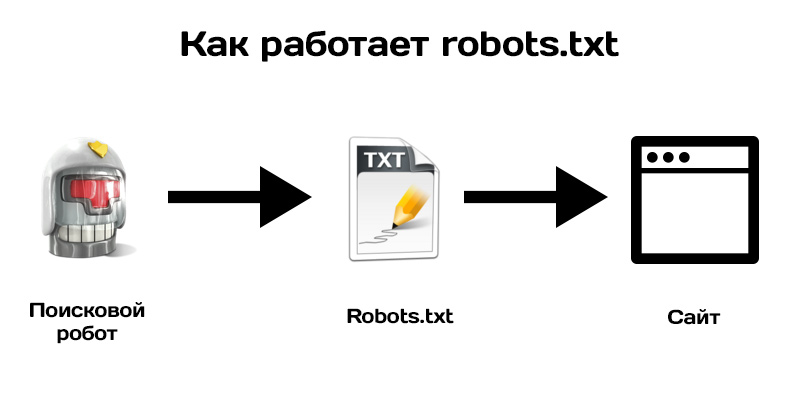
Поисковой робот, следуя на сайт, смотрит на правила индексации, затем начинает индексацию по рекомендациям файла.
В зависимости от настроек правил, поисковик знает, что можно индексировать, а что нет.
Как работают поисковые роботы и как они обрабатывают данный файл
В большинстве случаев, очень упрощенно, они работают так:
- Обходят Интернет;
- Проверяют, какие документы разрешено индексировать, а какие запрещено;
- Включает разрешенные документы в базу;
- Затем уже другие механизмы решают, какие страницы достаточно полезны для включения в индекс.
Вот ссылка на справку Яндекса о работе поисковых роботов, но там все довольно отдаленно описано.
По-разному ли Яндекс и Google воспринимают этот файл
Многие прописывают для роботов разных поисковиков разные директивы. Даже если список этих директив ничем не отличается.
А те, кто может ответить, аргументируют это так: мол, Google не воспринимает директиву Host и поэтому её нужно указывать только для Яндекса, и вот почему, мол, для яндексовского юзер-агента нужны отдельные директивы. Но я скажу так: если какой-то робот не воспринимает какую-то директиву, то он её просто проигнорирует. Так что лично я не вижу смысла указывать одни и те же директивы для разных роботов отдельно. Хотя, отчасти понимаю перестраховщиков.
Для чего нужна проверка robots.txt
Иногда в результаты поиска система включает ненужные страницы вашего Интернет-ресурса, в чем нет необходимости. Может показаться, что ничего плохого в большом количестве страниц в индексе поисковой системы нет, но это не так:
- На лишних страницах пользователь не найдет никакой полезной информации для себя. С большей долей вероятности он и вовсе не посетит эти страницы либо задержится на них недолго;
- В выдаче поисковика присутствуют одни и те же страницы, адреса которых различны (то есть контент дублируется);
- Поисковым роботам приходится тратить много времени, чтобы проиндексировать совершенно ненужные страницы. Вместо индексации полезного контента они будут бесполезно блуждать по сайту. Поскольку индексировать полностью весь ресурс робот не может и делает это постранично (так как сайтов очень много), то нужная информация, которую вы бы хотели получить после ведения запроса, возможно, будет найдена не очень быстро;
- Очень сильно нагружается сервер.
В связи с этим является целесообразным закрытие доступа поисковым роботам к некоторым страницам веб-ресурсов.
Какие же файлы и папки можно запретить индексировать:
- Страницы поиска. Это спорный пункт. Иногда использование внутреннего поиска на сайте необходимо, для того чтобы создать релевантные страницы. Но делается это не всегда. Зачастую результатом поиска становится появление большого количества дублированных страниц. Поэтому рекомендуется закрыть страницы поиска для индексации.
- Корзина и страница, на которой оформляют/подтверждают заказ. Их закрытие рекомендовано для сайтов онлайн-торговли и других коммерческих ресурсов, использующих форму заказа. Попадание этих страниц в индекс поисковых систем крайне нежелательно.
- Страницы пагинации. Как правило, для них характерно автоматическое прописывание одинаковых мета-тегов. Кроме того, их используют для размещения динамического контента, поэтому в результатах выдачи появляются дубли. В связи с этим пагинация должна быть закрыта для индексации.
- Фильтры и сравнение товаров. Закрывать их нужно онлайн-магазинам и сайтам-каталогам.
- Страницы регистрации и авторизации. Закрывать их нужно в связи с конфиденциальностью вводимых пользователями при регистрации или авторизации данных. Недоступность этих страниц для индексации будет оценена Гуглом.
- Системные каталоги и файлы. Каждый ресурс в Интернете состоит из множества данных (скриптов, таблиц CSS, административной части), которые не должны просматриваться роботами.
Закрыть файлы и страницы для индексации поможет файл robots.txt.
Рекомендуемые статьи по данной теме:
- Проверка тИЦ сайта: 3 способа
- Внутренняя оптимизация сайта: пошаговый разбор
- Файл htaccess: применение, включение, настройка
robots.txt – это обычный текстовый файл, содержащий инструкции для поисковых роботов. Когда поисковый робот оказывается на сайте, то в первую очередь занимается поиском файла robots.txt. Если же он отсутствует (или пустой), то робот будет заходить на все страницы и каталоги ресурса (в том числе и системные), находящиеся в свободном доступе, и пытаться провести их индексацию. При этом нет гарантии, что будет проиндексирована нужная вам страница, поскольку он может и не попасть на нее.
robots.txt позволяет направлять поисковые роботы на нужные страницы и не пускать на те, которые индексировать не следует. Файл может инструктировать как всех роботов сразу, так и каждого в отдельности. Если страницу сайта закрыть от индексации, то она никогда не появится в выдаче поисковой системы. Создание файла robots.txt является крайне необходимым.
Местом нахождения файла robots.txt должен быть сервер, корень вашего ресурса. Файл robots.txt любого сайта доступен для просмотра в Сети. Чтобы увидеть его, нужно после адреса ресурса добавить /robots.txt.
Как правило, файлы robots.txt различных ресурсов отличаются друг от друга. Если бездумно скопировать файл чужого сайта, то при индексации вашего поисковыми роботами возникнут проблемы. Поэтому так необходимо знать, для чего нужен файл robots.txt и инструкции (директивы), используемые при его создании.
Оставить заявку
Вас также может заинтересовать: Что делать, если упала посещаемость сайта
Написание и проверка robots.txt
Теперь вы знаете, какими директивами и как пользоваться. Переходите к написанию файла:
- Откройте текстовый редактор, к примеру, Блокнот.
- Пропишите содержимое.
- Сохраните документ с именем robots в формате txt.
- Опубликуйте файл в корневой каталог.
Не загружайте готовый robots.txt сразу на веб-сайт. Сначала сделайте его проверку одним из методов:
-
В Google Search Console.
Для этого нужно открыть «Сканирование» — «Инструмент проверки файла robots.txt». Потом вставляем содержимое robots.txt в указанное поле и задаём адрес веб-сайта. Кликаем «Проверить».
Google автоматически укажет вам на имеющиеся ошибки и покажет предупреждения. При наличии таковых нужно внести корректировки.
Кроме того, пользуясь инструментами системы, вы можете получать уведомления о появившихся ошибках — они будут доступны в админке Console.
-
В Яндекс.Вебмастер.
Откройте «Инструменты» — «Анализ robots.txt». Всё происходит аналогично предыдущему способу — вводим адрес веб-сайта, копируем и вставляем содержимое написанного файла.
Кликаем «Проверить» и получаем результаты — ошибки и предупреждения.
Как создать robots.txt
Создать файл можно тремя способами, выбор зависит от целей и навыков. Сервисы облегчают работу с robots.txt, но ручная коррекция все-таки потребуется. Поэтому для каждого варианта, хоть и в разной степени, придется самостоятельно разобраться с темой или обратиться к специалисту.
Ручное создание
Файл robots.txt можно создать в любом текстовом редакторе, например, в Блокноте и Microsoft Word. В документе прописывают специальный код-инструкцию, в нем указывают, какие элементы не подлежат индексации. После этого его сохраняют в формате.txt под названием «robots».
Готовый текстовый документ загружается в корневую папку с названием сайта, где находится файл index.html и файлы базового движка. Чтобы загрузить robots.txt на сервер, используют:
- панель управления сервером;
- консоль или пульт управления в CMS;
- любой FTP-клиент.
Система каждый раз будет обращаться к роботу, чтобы понять, что можно индексировать на сайте, а что нет.
Онлайн-генераторы
Специальные сервисы помогут автоматически сгенерировать нужный файл, например, такой инструмент есть на сайте CY-PR. Генераторы облегчают работу тем, кто владеет сразу несколькими сайтами, так как прописывать характеристики для каждого достаточно долго. Автоматизация упростит процесс, но корректировать автоматически сгенерированные файлы придется вручную. Чтобы устранять возможные ошибки, нужно изучить базовый синтаксис robots.txt.
Готовые шаблоны
В интернете представлено много шаблонов файла robots.txt, которые подходят для всех популярных движков (WordPress, Drupal). В шаблоне прописаны стандартные директивы, поэтому файл не нужно создавать полностью вручную.
Если учесть индивидуальные особенности проекта, на его основе можно сделать качественный robots.txt. Но для этого тоже необходимы хотя бы минимальные знания синтаксиса, потому что шаблон не может предоставить корректно настроенный, готовый к работе, файл.
Robots.txt для WordPress
Для создания файла нам нужно точно так же забросить robots.txt в корень сайта. Изменять его содержимое в таком случае можно будет с помощью все тех же FTP и файловых менеджеров.
Есть и более удобный вариант – создать файл с помощью плагинов. В частности, такая функция есть у Yoast SEO. Править роботс прямо из админки куда удобнее, поэтому сам я использую именно такой способ работы с robots.txt.
Как вы решите создать этот файл – дело ваше, нам важнее понять, какие именно директивы там должны быть. На своих сайтах под управлением WordPress использую такой вариант:
User-agent: * # правила для всех роботов, за исключением Гугла и Яндекса
Disallow: /cgi-bin # папка со скриптами
Disallow: /? # параметры запросов с домашней страницы
Disallow: /wp- # файлы самой CSM (с приставкой wp-)
Disallow: *?s= # \
Disallow: *&s= # все, что связано с поиском
Disallow: /search/ # /
Disallow: /author/ # архивы авторов
Disallow: /users/ # и пользователей
Disallow: */trackback # уведомления от WP о том, что на вас кто-то ссылается
Disallow: */feed # фид в xml
Disallow: */rss # и rss
Disallow: */embed # встроенные элементы
Disallow: /xmlrpc.php # WordPress API
Disallow: *utm= # UTM-метки
Disallow: *openstat= # Openstat-метки
Disallow: /tag/ # тэги (при наличии)
Allow: */uploads # открываем загрузки (картинки и т. д.)
User-agent: GoogleBot # для Гугла
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: /xmlrpc.php
Disallow: *utm=
Disallow: *openstat=
Disallow: /tag/
Allow: */uploads
Allow: /*/*.js # открываем JS-файлы
Allow: /*/*.css # и CSS
Allow: /wp-*.png # и картинки в формате png
Allow: /wp-*.jpg # \
Allow: /wp-*.jpeg # и в других форматах
Allow: /wp-*.gif # /
Allow: /wp-admin/admin-ajax.php # работает вместе с плагинами
User-agent: Yandex # для Яндекса
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: /xmlrpc.php
Disallow: /tag/
Allow: */uploads
Allow: /*/*.js
Allow: /*/*.css
Allow: /wp-*.png
Allow: /wp-*.jpg
Allow: /wp-*.jpeg
Allow: /wp-*.gif
Allow: /wp-admin/admin-ajax.php
Clean-Param: utm_source&utm_medium&utm_campaign # чистим UTM-метки
Clean-Param: openstat # и про Openstat не забываем
Sitemap: # прописываем путь до карты сайта
Host: https://site.ru # главное зеркало
Внимание! При копировании строк в файл – не забудьте удалить все комментарии (текст после #). Такой вариант robots.txt наиболее популярен среди вебмастеров, которые используют WP
Идеальный ли он? Нет. Вы можете попытаться что-то добавить или наоборот убрать. Но учтите, что при оптимизации текстовика роботов нередки ошибки. О них мы поговорим далее
Такой вариант robots.txt наиболее популярен среди вебмастеров, которые используют WP. Идеальный ли он? Нет. Вы можете попытаться что-то добавить или наоборот убрать. Но учтите, что при оптимизации текстовика роботов нередки ошибки. О них мы поговорим далее.
Используемые директивы
User-agent
Все блоки правил начинаются с директивы User-agent, в которой указывается название робота, для которого задается правило. Запись вида User-agent: * означает, что правило задается для всех поисковых роботов.
Например, при следующей записи правило будет применено только к основному индексирующему боту Яндекса:
User-agent: YandexBot
Правило будет применено ко всем роботам Яндекса и Google:
User-agent: Yandex User-agent: Googlebot
Правило будет применено вообще ко всем роботам:
User-agent: *
Disallow и Allow
Директивы используются, чтобы запретить и разрешить доступ к определенным разделам сайта.
Например, можно запретить индексацию всего сайта (Disallow: /), кроме определенного каталога (Allow: /catalog):
User-agent: имя_бота Disallow: / Allow: /catalog
Запретить индексацию страниц, начинающихся с /catalog, но разрешить для страниц, начинающихся с /catalog/auto и /catalog/new:
User-agent: имя_бота Disallow: /catalog Allow: /catalog/auto Allow: /catalog/new
В каждой строке указывается только одна директория. Для запрещения (или разрешения) доступа к нескольким каталогам, для каждого требуется отдельная запись.
С помощью Disallow можно ограничить доступ к сайту для нежелательных ботов, тем самым снизив создаваемую ими нагрузку. Например, чтобы запретить доступ ко всему сайту для MJ12bot и AhrefsBot — ботов сервиса majestic.com и ahrefs.com — используйте:
User-agent: MJ12bot User-agent: AhrefsBot Disallow: /
Аналогичным образом устанавливается блокировка и для других ботов (скажем, DotBot, SemrushBot и других).
Примечания:
- Пустая директива Disallow: равнозначна Allow: /, то есть «не запрещать ничего».
- В директивах может использоваться символ $ для обозначения точного соответствия указанному параметру. Например, запись Disallow: /catalog аналогична Disallow: /catalog * и запретит доступ ко всем страницам с /catalog (/catalog, /catalog1, /catalog-new, /catalog/clothes и др.).Использование $ это изменит. Disallow: /catalog$ запретит доступ к /catalog, но разрешит /catalog1, /catalog-new, /catalog/clothes и др.
Sitemap
При использовании файла sitemap.xml для описания структуры сайта, можно указать путь к нему с помощью соответствующей директивы:
User-agent: * Disallow: Sitemap: https://mydomain.com/путь_к_файлу/mysitemap.xml
Можно перечислить несколько файлов Sitemap, каждый в отдельной строке.
Host
Директива используется для указания роботам Яндекса основного зеркала сайта и полезна, когда сайт доступен по нескольким доменам.
User-agent: Yandex Disallow: /catalog1$ Host: https://mydomain.com
Примечания:
- Директива Host может быть только одна; если в файле указано несколько, роботом будет учтена только первая.
- Необходимо указывать протокол https, если он используется. Если вы используете http, зеркало можно записать в виде mydomain.com
- Для корректного прочтения директивы, ее нужно указывать в блоке правил User-agent после директив Disallow и Allow.
Crawl-delay
Директива устанавливает минимальный интервал в секундах между обращениями робота к сайту, что может быть полезно для снижения создаваемой роботами нагрузки. Чем выше указанное значение, тем меньше страниц робот загрузит за сессию.
Значения можно указывать целыми или дробными числами (разделитель — точка).
User-agent: Yandex Disallow: Crawl-delay: 0.5
Примечания:
- Для корректного прочтения директивы, ее нужно указывать в блоке правил User-agent после директив Disallow и Allow.
Clean-param
Директива используется для робота Яндекса. Она позволяет исключить из индексации страницы с динамическими параметрами в URL-адресах (это могут быть идентификаторы сессий, пользователей, рефереров), чтобы робот не индексировал одно и то же содержимое повторно, повышая тем самым нагрузку на сервер.
Например, на сайте есть страницы:
www.mydomain.ru/news.html?&parm1=1&parm2=2 www.mydomain.ru/news.html?&parm2=2&parm3=3
По факту по обоим адресам отдается одна и та же страница — www.mydomain.ru/news.html, при этом в URL присутствуют дополнительные динамические параметры.
Чтобы робот не индексировал каждую подобную страницу, можно использовать директиву:
User-agent: Yandex Disallow: Clean-param: parm1&parm2&parm3 /news.html
Через знак & указываются параметры, которые робот должен игнорировать. Далее указывается страница, для которой применяется данное правило
Операторы в robots.txt
Прежде, чем мы перейдём к обзору директив, ознакомимся с дополнительными операторами. Про символ # мы поговорили выше. Кроме него вам могут потребоваться следующие операторы:
«*» сообщает, что допускается любое число символов или таковые отсутствуют;
«$» поясняет, что находящийся перед ним символ является последним.
Директива User-agent
Адресует ваши команды определённому боту-поисковику. Именно с неё вы начинаете прописывать robots.txt.
(правила задаются для всех роботов Яндекса)
(правила задаются для всех роботов Google)
(правила задаются для всех поисковых систем)
Обращаю ваше внимание: когда поисковой робот обнаруживает своё имя после User-agent, то он не воспринимает все команды, которые вы зададите в блоке User-agent: *. И ещё, у отдельных поисковых систем существует целая группа ботов, команды для которых можно задавать в индивидуальном порядке
При этом блоки с рекомендациями для таких ботов разбиваются путём оставления пустой строки
И ещё, у отдельных поисковых систем существует целая группа ботов, команды для которых можно задавать в индивидуальном порядке. При этом блоки с рекомендациями для таких ботов разбиваются путём оставления пустой строки.
Поисковые роботы Google:
- Googlebot — основной бот системы;
- Googlebot-Image — обрабатывает изображения;
- Googlebot-Video — отслеживает видео-контент;
- Googlebot-Mobile — работает со страницами для мобильных девайсов;
- Adsbot-Google — анализирует качество рекламы на веб-страницах для персональных компьютеров;
- Googlebot-News — определяет веб-страницы, которые следует внести в Новости Google.
Поисковые роботы Yandex:
- YandexBot — основной бот системы;
- YandexImages — обрабатывает изображения;
- YandexNews — определяет веб-страницы для добавления в Яндекс.Новости;
- YandexMedia — отслеживает мультимедиа контент;
- YandexMobileBot — работает со страницами для мобильных девайсов.
Директива Disallow
Самая популярная команда — выдаёт запрет на индексацию страниц.
Примеры:
(закрытие доступа ко всему веб-ресурсу)
(закрытие доступа к панели администратора)
(закрытие доступа на обработку документов заданного типа)
Директива Allow
Даёт право обрабатывать поисковикам заданные вами веб-страницы. Это особенно актуально в процессе ведения техработ на сайте.
Например, вы модернизируете веб-ресурс, но каталог с товарами не подлежит изменениям. Вы закрываете доступ к своему сайту, а ботов направляете только к нужному вам разделу.
Пример:
Директива Host
До недавнего времени применялась для показа роботам Яндекса основного зеркала веб-сайта — с www или без.
Весной 2018 г. российская ИТ-компания проинформировала пользователей, что директива заменяется на редирект 301 — универсальный метод для всех работающих поисковиков, который указывает на основной сайт.
На сегодняшний день эта команда бесполезна. Но если она проставлена в файле, то ничего страшного — поисковые боты её просто игнорируют.
Директива Sitemap
Предназначена для указания пути к Карте вашего ресурса. По-хорошему, sitemap.xml должен храниться в корне веб-сайта. В случае, когда путь отличается, эта команда позволяет найти поисковикам Карту.
Директива Clean-param
Её задача — пояснить боту, что нет необходимости в индексировании страницы с определёнными параметрами. Это относится к динамическим ссылкам, ведь они периодически формируются в ходе работы веб-сайта и образуют дубли — то есть одинаковая страница становится доступна на нескольких адресах.
Тогда применяется «ref» — параметр, позволяющий выявить источник ссылки.
Пример:
Результат:
Таким образом поисковик сведёт все URL к одной странице. Она будет участвовать в поисковой выдаче при условии её наличия на веб-сайте:
Директива Crawl-Delay
Команда предназначена, чтобы уведомить бота-поисковика о продолжительности загрузки страницы (в секундах). Она позволяет снизить нагрузку на веб-ресурс. Это актуально, когда веб-сайт размещён на слабом сервере.
Выглядит это так:
(вы уведомили поисковика, что можно скачивать данные каждые 3.5 секунд)
Technical robots.txt syntax
Robots.txt syntax can be thought of as the “language” of robots.txt files. There are five common terms you’re likely come across in a robots file. They include:
-
User-agent: The specific web crawler to which you’re giving crawl instructions (usually a search engine). A list of most user agents can be found here.
-
Disallow: The command used to tell a user-agent not to crawl particular URL. Only one «Disallow:» line is allowed for each URL.
-
Allow (Only applicable for Googlebot): The command to tell Googlebot it can access a page or subfolder even though its parent page or subfolder may be disallowed.
-
Crawl-delay: How many seconds a crawler should wait before loading and crawling page content. Note that Googlebot does not acknowledge this command, but crawl rate can be set in Google Search Console.
-
Sitemap: Used to call out the location of any XML sitemap(s) associated with this URL. Note this command is only supported by Google, Ask, Bing, and Yahoo.
Pattern-matching
When it comes to the actual URLs to block or allow, robots.txt files can get fairly complex as they allow the use of pattern-matching to cover a range of possible URL options. Google and Bing both honor two regular expressions that can be used to identify pages or subfolders that an SEO wants excluded. These two characters are the asterisk (*) and the dollar sign ($).
- * is a wildcard that represents any sequence of characters
- $ matches the end of the URL
Google offers a great list of possible pattern-matching syntax and examples here.