Шпаргалка по регулярным выражениям
Содержание:
- Perl programming language regular expression examples
- Мультипликаторы
- Параметры регулярных выражений
- Создание регулярного выражения
- Capturing groups
- Примеры
- POSIX Extended Regular Expressions
- Методы replaceFirst и replaceAll
- Символы¶
- Unicode категории (category)¶
- Где использовать регулярные выражения
- Special characters
- Строковые методы, поиск и замена
- Escaping
- regexp.exec(str)
- Квантификаторы
- More Detailed Examples
Perl programming language regular expression examples
Below are a few examples of regular expressions and pattern matching in Perl. Many of these examples are similar or the same to other programming languages and programs that support regular expressions.
$data =~ s/bad data/good data/i;
The above example replaces any «bad data» with «good data» using a case-insensitive match. So if the $data variable was «Here is bad data» it would become «Here is good data».
$data =~ s/a/A/;
This example replaces any lowercase a with an uppercase A. So if $data was «example» it would become «exAmple».
$data =~ s//*/;
The above example replaces any lowercase letter, a through z, with an asterisk. So if $data was «Example» it would become «E******».
$data =~ s/e$/es/;
This example uses the $ character, which tells the regular expression to match the text before it at the end of the string. So if $data was «example» it would become «examples».
$data =~ s/\./!/;
In the above example, we are replacing a period with an exclamation mark. Because the period is a metacharacter if you only entered a period without the \ ( escape) it is treated as any character. In this example, if $data were «example.» it would become «example!», however, if you did not have the escape it would replace every character and become «!!!!!!!!»
$data =~ s/^e/E/;
Finally, in this above example the caret ( ^ ) tells the regular expression to match anything at the beginning of the line. In this example, any lowercase «e» at the beginning of the line is replaced with a capital «E.» Therefore, if $data was «example» it would become «Example».
Tip
If you want to explore regular expressions even more in commands like grep, or regular expressions in programming language’s check out the O’Reilly book «Mastering regular expressions.»
Мультипликаторы
Мультипликаторы позволяют увеличить количество раз появления элемента в нашем регулярном выражении. Вот основной набор мультипликаторов:
— значение встречается 0 или более раз;
— значение встречается 1 или более раз;
— значение встречается 0 или 1 раз;
— значение встречается 5 раз;
— значение встречается от 3 до 7 раз;
— значение встречается не менее 2 раз.
Их действие распространяется на всё, что находится прямо перед ними. Это может быть обычный символ, например:
В примере, приведенном выше, мы ищем символ , за которым следует символ ноль или более раз. Вот почему в слове также является совпадением (это , за которым идет символ ноль раз).
Или это может быть метасимвол, например:
На первый взгляд такой результат может показаться вам немного странным. Регулярное выражение соответствует повторению ноль или более раз любого символа. Вы могли бы подумать, что при нахождении первого , будет сказано «да, я нашел совпадение», но на самом деле говорится, что « является любым символом, поэтому давайте посмотрим, на сколько длинным может быть соответствие», и поиск продолжится, пока не будет найден последний в строке.
Это то, что называется «жадным сопоставлением». Это нормальное поведение — пытаться найти самую большую строку, которая может соответствовать шаблону. Мы можем изменить это поведение и сделать его «нежадным», поместив вопросительный знак () после мультипликатора (что может показаться немного запутанным, поскольку вопросительный знак сам по себе является множителем):
Параметры регулярных выражений
Можно определить параметры, управляющие интерпретацией шаблона регулярного выражения обработчиком регулярных выражений. Многие из этих параметров можно указать в шаблоне регулярного выражения либо в виде одной или нескольких констант RegexOptions. Этот краткий справочник перечисляет только встраиваемые параметры. Дополнительные сведения о встроенных параметрах и параметрах RegexOptions см. в статье Параметры регулярных выражений.
Встроенный параметр можно задать двумя способами:
- С помощью прочих конструкций , где минус (-) перед параметром или набором параметров отключает эти параметры. Например, включает сопоставление без учета регистра (), отключает многострочный режим () и отключает захват неименованных групп (). Параметр применяется к шаблону регулярного выражения от точки, в которой определен параметр, и действует либо до конца шаблона, либо до точки, в которой другая конструкция отменяет параметр.
- С помощью конструкции группированиячасть выражения, которая определяет параметры для только для указанной группы.
Механизм регулярных выражений .NET поддерживает следующие встроенные параметры:
| Параметр | Описание | Шаблон | Число соответствий |
|---|---|---|---|
| Использовать соответствие без учета регистра. | , в | ||
| Использовать многострочный режим. и соответствуют началу и концу строки (line), а не началу и концу строки (string). | Пример см. в подразделе «Многострочный режим» раздела Параметры регулярных выражений. | ||
| Не захватывать неименованные группы. | Пример см. в подразделе «Только явные захваты» раздела Параметры регулярных выражений. | ||
| Использовать однострочный режим. | Пример см. в подразделе «Однострочный режим» раздела Параметры регулярных выражений. | ||
| Игнорировать знаки пробела в шаблоне регулярного выражения, не преобразованные в escape-последовательность. | , в |
Создание регулярного выражения
Регулярное выражение можно создать двумя способами:
-
Используя литерал регулярного выражения, например:
Литералы регулярных выражений вызывают предварительную компиляцию регулярного выражения при анализе скрипта. Если ваше регулярное выражение постоянно, то пользуйтесь им, чтобы увеличить производительность.
-
Вызывая функцию конструктор объекта , например:
Использование конструктора влечёт за собой компиляцию регулярного выражения во время исполнения скрипта. Используйте данный способ, если знаете, что выражение будет изменяться или не знаете шаблон заранее. Например вы получаете его из стороннего источника, при пользовательском вводе.
Capturing groups
Группы захвата(Capturing groups) — это способ рассматривать несколько символов как единое целое. Они создаются путем помещения символов, которые будут сгруппированы, в набор скобок.
Например, (dog) создает одну группу, содержащую буквы «d», «o» и «g».
Группы захвата нумеруются путем подсчета открывающих скобок слева направо. В выражении ((A) (B (C))), например, есть четыре такие группы —
- ((A)(B(C)))
- (A)
- (B(C))
- (C)
Чтобы узнать, сколько групп присутствует в выражении, вызовите метод groupCount для объекта соответствия. Метод groupCount возвращает int, показывающий количество групп захвата, присутствующих в шаблоне сопоставителя.
Существует также специальная группа, группа 0, которая всегда представляет все выражение. Эта группа не включена в общее количество, сообщенное groupCount.
В следующем примере показано, как найти строку цифр из заданной буквенно-цифровой строки:
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegexMatches {
public static void main( String args[] ) {
// Строка для сканирования, чтобы найти шаблон.
String line = "This order was placed for QT3000! OK?";
String pattern = "(.*)(\\d+)(.*)";
// Создаем объект Pattern
Pattern r = Pattern.compile(pattern);
// Теперь создаем объект соответствия.
Matcher m = r.matcher(line);
if (m.find( )) {
System.out.println("Found value: " + m.group(0) );
System.out.println("Found value: " + m.group(1) );
System.out.println("Found value: " + m.group(2) );
}else {
System.out.println("NO MATCH");
}
}
}
Это даст следующий результат:
Примеры
След. примеры показывают использование регулярных выражений.
След. пример иллюстрирует формирование регулярного выражения и использование и . Он очищает неправильно сформатированную исходную строку, которая содержит имена в неправильном порядке (имя идёт первым) разделённые пробелами, табуляцией и одной точкой с запятой. В конце, изменяется порядок следования имён (фамилия станет первой) и сортируется список.
В след. примере, ожидается что пользователь введёт телефонный номер и требуется проверить правильность символов набранных пользователем. Когда пользователь нажмёт кнопку «Check», скрипт проверит правильность введённого номера. Если номер правильный (совпадает с символами определёнными в регулярном выражении), то скрипт покажет сообщение благодарности для пользователя и подтвердит номер. Если нет, то скрипт проинформирует пользователя, что телефонный номер неправильный.
Внутри незахватывающих скобок открывающую скобку , затем закрывающую скобку (закрывающая незахватывающая скобка ), затем тире, слеш, или десятичная точка, и когда это выражение найдено, запоминает символ , следующие за ним и запомненные три цифры , следующее соответствие тире, слеша или десятичной точки , и следующие четыре цифры
Регулярное выражение ищет сначала 0 или одну открывающую скобку , , затем 0 или одну закрывающую скобку , потом одно тире, слеш или точка и когда найдёт это, запомнит символ, след. три цифры, followed by the remembered match of a dash, forward slash, or decimal point , followed by four digits .
Событие «Изменить» активируется, когда пользователь подтвердит ввод значения регулярного выражения, нажав клавишу «Enter».
autoPreviousNext("JSGChapters");
POSIX Extended Regular Expressions
The Extended Regular Expressions or ERE flavor standardizes a flavor similar to the one used by the UNIX egrep command. “Extended” is relative to the original UNIX grep, which only had bracket expressions, dot, caret, dollar and star. An ERE support these just like a BRE. Most modern regex flavors are extensions of the ERE flavor. By today’s standard, the POSIX ERE flavor is rather bare bones. The POSIX standard was defined in 1986, and regular expressions have come a long way since then.
The developers of egrep did not try to maintain compatibility with grep, creating a separate tool instead. Thus egrep, and POSIX ERE, add additional metacharacters without backslashes. You can use backslashes to suppress the meaning of all metacharacters, just like in modern regex flavors. Escaping a character that is not a metacharacter is an error.
The quantifiers ?, +, {n}, {n,m} and {n,} repeat the preceding token zero or once, once or more, n times, between n and m times, and n or more times, respectively. Alternation is supported through the usual vertical bar |. Unadorned parentheses create a group, e.g. (abc){2} matches abcabc. The POSIX standard does not define backreferences. Some implementations do support \1 through \9, but these are not part of the standard for ERE. ERE is an extension of the old UNIX grep, not of POSIX BRE.
And that’s exactly how far the extension goes.
Методы replaceFirst и replaceAll
Методы replaceFirst и replaceAll заменяют текст, соответствующий заданному регулярному выражению. replaceFirst заменяет первое вхождение, а replaceAll заменяет все вхождения.
Вот пример, объясняющий их работу:
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegexMatches {
private static String REGEX = "dog";
private static String INPUT = "The dog says meow. " + "All dogs say meow.";
private static String REPLACE = "cat";
public static void main(String[] args) {
Pattern p = Pattern.compile(REGEX);
// получаем объект соответствия
Matcher m = p.matcher(INPUT);
INPUT = m.replaceAll(REPLACE);
System.out.println(INPUT);
}
}
И теперь вывод:
Символы¶
Серия символов соответствует этой серии символов во входной строке.
| RegEx | Находит |
|---|---|
Непечатные символы (escape-коды)
Для представления непечатаемого символа в регулярном выражении используется с шестнадцатеричным кодом. Если код длиннее 2 цифр (более U+00FF), то он обрамляется в фигурные скобки.
RegEx
Находит
символ с 2-значным шестнадцатеричным кодом
символ с 1-4 значным шестнадцатеричным кодом
(обратите внимание на пробел в середине)
Существует ряд предопределенных для непечатных символов, как в языке :
| RegEx | Находит |
|---|---|
| tab (HT/TAB), тоже что | |
| символ новой строки (LF), то же что | |
| возврат каретки (CR), тоже что | |
| form feed (FF), то же что | |
| звонок (BEL), тоже что | |
| escape (ESC), то же что | |
| … |
chr(0) по chr(25). |
Unicode категории (category)¶
В стандарте Unicode есть именованные категории символов (Unicode category). Категория обозначается одной буквой, и еще одна добавляется, чтобы указать подкатегорию. Например «L» это буква в любом регистре, «Lu» — буквы в верхнем регистре, «Ll» — в нижнем.
- Cc — Control
- Cf — Формат
- Co — Частное использование
- Cs — Заменитель (Surrrogate)
- Ll — Буква нижнего регистра
- Lm — Буква-модификатор
- Lo — Прочие буквы
- Lt — Titlecase Letter
- Lu — Буква в верхнем регистре
- Mc — Разделитель
- Me — Закрывающий знак (Enclosing Mark)
- Mn — Несамостоятельный символ, как умляут над буквой (Nonspacing Mark)
- Nd — Десятичная цифра
- Nl — Буквенная цифра — например, китайская, римская, руническая и т.д. (Letter Number)
- No — Другие цифры
- Pc — Connector Punctuation
- Pd — Dash Punctuation
- Pe — Close Punctuation
- Pf — Final Punctuation
- Pi — Initial Punctuation
- Po — Other Punctuation
- Ps — Open Punctuation
- Sc — Currency Symbol
- Sk — Modifier Symbol
- Sm — Математический символ
- So — Прочие символы
- Zl — Разделитель строк
- Zp — Разделитель параграфов
- Zs — Space Separator
Метасимвол это один символ указанной Unicode категории (category). Синтаксис: или если категория обозначается одним символом, для 2-символьных категорий.
Метасимвол это символ не из Unicode категории (category).
Где использовать регулярные выражения
SEO-специалисты прибегают к регулярным выражениям при работе с Google Analytics, Яндекс.Метрикой, RewriteRule в .htaccess, в текстовых редакторах, при работе с краулерами (Netpeak Spider).
Расскажу о нескольких регулярных выражених, которые часто мне помогают.
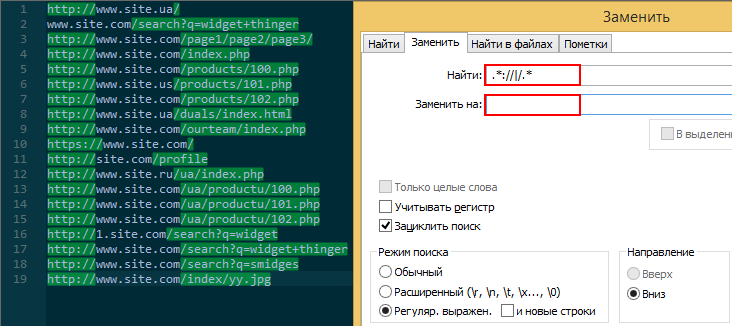
1. Выделить всё, кроме домена:
Использую, когда есть большой список URL-адресов (например, внешних ссылок) и для анализа нужно вычленить только домен. В NotePad++ с помощью функции замены меняю на пустую строку и получаю чистый список доменов:
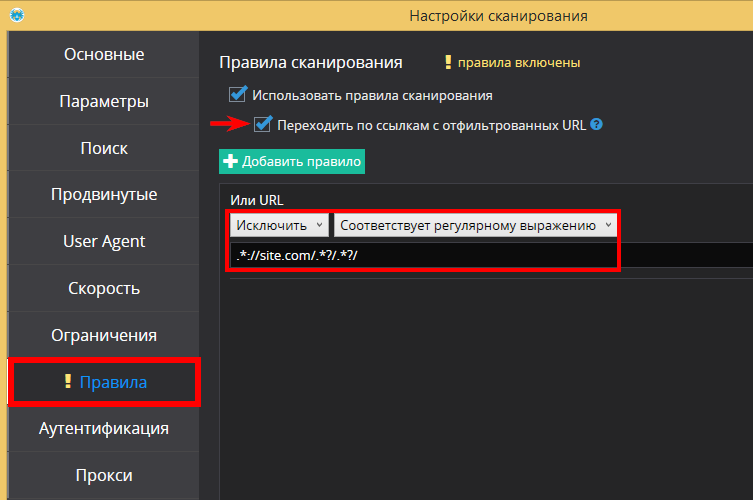
2. Выделить URL заданной вложенности:
Здесь конструкция (/.*?/) обозначает один уровень вложенности.
Использую это выражение, когда нужно задать максимально разрешенную вложенность URL при сканировании сайта в Netpeak Spider.
Чтобы просканировать все URL адреса только первого уровня вложенности, в сервисе нужно задать такие настройки:
Special characters
Escapes also allow you to specify individual characters that are otherwise hard to type. You can specify individual unicode characters in five ways, either as a variable number of hex digits (four is most common), or by name:
-
: 2 hex digits.
-
: 1-6 hex digits.
-
: 4 hex digits.
-
: 8 hex digits.
-
, e.g. matches the basic smiling emoji.
Similarly, you can specify many common control characters:
-
: bell.
-
: match a control-X character.
-
: escape ().
-
: form feed ().
-
: line feed ().
-
: carriage return ().
-
: horizontal tabulation ().
-
match an octal character. ‘ooo’ is from one to three octal digits, from 000 to 0377. The leading zero is required.
Строковые методы, поиск и замена
Следующие методы работают с регулярными выражениями из строк.
Все методы, кроме replace, можно вызывать как с объектами типа regexp в аргументах, так и со строками, которые автоматом преобразуются в объекты RegExp.
Так что вызовы эквивалентны:
var i = str.search(/\s/)
var i = str.search("\\s")
При использовании кавычек нужно дублировать \ и нет возможности указать флаги. Если регулярное выражение уже задано строкой, то бывает удобна и полная форма
var regText = "\\s" var i = str.search(new RegExp(regText, "g"))
Возвращает индекс регулярного выражения в строке, или -1.
Если Вы хотите знать, подходит ли строка под регулярное выражение, используйте метод (аналогично RegExp-методы ). Чтобы получить больше информации, используйте более медленный метод (аналогичный методу ).
Этот пример выводит сообщение, в зависимости от того, подходит ли строка под регулярное выражение.
function testinput(re, str){
if (str.search(re) != -1)
midstring = " contains ";
else
midstring = " does not contain ";
document.write (str + midstring + re.source);
}
Если в regexp нет флага , то возвращает тот же результат, что .
Если в regexp есть флаг , то возвращает массив со всеми совпадениями.
Чтобы просто узнать, подходит ли строка под регулярное выражение , используйте .
Если Вы хотите получить первый результат — попробуйте r.
В следующем примере используется, чтобы найти «Chapter», за которой следует 1 или более цифр, а затем цифры, разделенные точкой. В регулярном выражении есть флаг , так что регистр будет игнорироваться.
str = "For more information, see Chapter 3.4.5.1"; re = /chapter (\d+(\.\d)*)/i; found = str.match(re); alert(found);
Скрипт выдаст массив из совпадений:
- Chapter 3.4.5.1 — полностью совпавшая строка
- 3.4.5.1 — первая скобка
- .1 — внутренняя скобка
Следующий пример демонстрирует использование флагов глобального и регистронезависимого поиска с . Будут найдены все буквы от А до Е и от а до е, каждая — в отдельном элементе массива.
var str = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz"; var regexp = //gi; var matches = str.match(regexp); document.write(matches); // matches =
Метод replace может заменять вхождения регулярного выражения не только на строку, но и на результат выполнения функции. Его полный синтаксис — такой:
var newString = str.replace(regexp/substr, newSubStr/function)
- Объект RegExp. Его вхождения будут заменены на значение, которое вернет параметр номер 2
- Строка, которая будет заменена на .
- Строка, которая заменяет подстроку из аргумента номер 1.
- Функция, которая может быть вызвана для генерации новой подстроки (чтобы подставить ее вместо подстроки, полученной из аргумента 1).
Метод не меняет строку, на которой вызван, а просто возвращает новую, измененную строку.
Чтобы осуществить глобальную замену, включите в регулярное выражение флаг .
Если первый аргумент — строка, то она не преобразуется в регулярное выражение, так что, например,
var ab = "a b".replace("\\s","..") // = "a b"
Вызов replace оставил строку без изменения, т.к искал не регулярное выражение , а строку «\s».
В строке замены могут быть такие спецсимволы:
| Pattern | Inserts |
| Вставляет «$». | |
| Вставляет найденную подстроку. | |
| Вставляет часть строки, которая предшествует найденному вхождению. | |
| Вставляет часть строки, которая идет после найденного вхождения. | |
| or | Где или — десятичные цифры, вставляет подстроку вхождения, запомненную -й вложенной скобкой, если первый аргумент — объект RegExp. |
Если Вы указываете вторым параметром функцию, то она выполняется при каждом совпадении.
В функции можно динамически генерировать и возвращать строку подстановки.
Первый параметр функции — найденная подстрока. Если первым аргументом является объект , то следующие параметров содержат совпадения из вложенных скобок. Последние два параметра — позиция в строке, на которой произошло совпадение и сама строка.
Например, следующий вызов возвратит XXzzzz — XX , zzzz.
function replacer(str, p1, p2, offset, s)
{
return str + " - " + p1 + " , " + p2;
}
var newString = "XXzzzz".replace(/(X*)(z*)/, replacer)
Как видите, тут две скобки в регулярном выражении, и потому в функции два параметра , .
Если бы были три скобки, то в функцию пришлось бы добавить параметр .
Следующая функция заменяет слова типа на :
function styleHyphenFormat(propertyName)
{
function upperToHyphenLower(match)
{
return '-' + match.toLowerCase();
}
return propertyName.replace(//, upperToHyphenLower);
}
Escaping
If “” matches any character, how do you match a literal “”? You need to use an “escape” to tell the regular expression you want to match it exactly, not use its special behaviour. Like strings, regexps use the backslash, , to escape special behaviour. So to match an , you need the regexp . Unfortunately this creates a problem. We use strings to represent regular expressions, and is also used as an escape symbol in strings. So to create the regular expression we need the string .
If is used as an escape character in regular expressions, how do you match a literal ? Well you need to escape it, creating the regular expression . To create that regular expression, you need to use a string, which also needs to escape . That means to match a literal you need to write — you need four backslashes to match one!
In this vignette, I use to denote the regular expression, and to denote the string that represents the regular expression.
An alternative quoting mechanism is : all the characters in are treated as exact matches. This is useful if you want to exactly match user input as part of a regular expression.
regexp.exec(str)
The method method returns a match for in the string . Unlike previous methods, it’s called on a regexp, not on a string.
It behaves differently depending on whether the regexp has flag .
If there’s no , then returns the first match exactly as . This behavior doesn’t bring anything new.
But if there’s flag , then:
- A call to returns the first match and saves the position immediately after it in the property .
- The next such call starts the search from position , returns the next match and saves the position after it in .
- …And so on.
- If there are no matches, returns and resets to .
So, repeated calls return all matches one after another, using property to keep track of the current search position.
In the past, before the method was added to JavaScript, calls of were used in the loop to get all matches with groups:
This works now as well, although for newer browsers is usually more convenient.
We can use to search from a given position by manually setting .
For instance:
If the regexp has flag , then the search will be performed exactly at the position , not any further.
Let’s replace flag with in the example above. There will be no matches, as there’s no word at position :
That’s convenient for situations when we need to “read” something from the string by a regexp at the exact position, not somewhere further.
Квантификаторы
Квантификаторы можно использовать для сопоставления символов более одного раза. Существует несколько типов, которые перечислены в синтаксисе Java Regex. Наиболее часто используемые:
String regex = "Hello*";
Это регулярное выражение сопоставляет строки с текстом «Hell», за которым следует ноль или более символов. Таким образом, регулярное выражение будет соответствовать «Hell», «Hello», «Helloo» и т. д.
Если бы квантификатором был символ + вместо символа *, строка должна была бы заканчиваться 1 или более символами o.
String regex = "Hell\\+";
Будет соответствовать строке «Hell+»;
String regex = "Hello{2}";
Будет соответствовать строке «Helloo»(с двумя символами o в конце).
String regex = "Hello{2,4}";
Будет соответствовать строкам “Helloo”, “Hellooo” и “Helloooo”. Другими словами, строка «Hell» с 2, 3 или 4 символами в конце.
More Detailed Examples
Numeric Ranges. Since regular expressions work with text rather than numbers, matching specific numeric ranges requires a bit of extra care.
Matching a Floating Point Number. Also illustrates the common mistake of making everything in a regular expression optional.
Matching Valid Dates. A regular expression that matches 31-12-1999 but not 31-13-1999.
Finding or Verifying Credit Card Numbers. Validate credit card numbers entered on your order form. Find credit card numbers in documents for a security audit.
Matching Complete Lines. Shows how to match complete lines in a text file rather than just the part of the line that satisfies a certain requirement. Also shows how to match lines in which a particular regex does not match.
Removing Duplicate Lines or Items. Illustrates simple yet clever use of capturing parentheses or backreferences.
Regex Examples for Processing Source Code. How to match common programming language syntax such as comments, strings, numbers, etc.
Two Words Near Each Other. Shows how to use a regular expression to emulate the “near” operator that some tools have.