Php preg_match() function
Содержание:
- Регулярные выражения в PHP
- preg_grep()
- Мета-символы
- Параметры регулярных выражений
- Разделители¶
- Метасимволы
- Строковые методы, поиск и замена
- matchAll()
- Как создавать простые шаблоны?
- Как создавать сложные шаблоны со специальными символами?
- Примеры preg_match PHP
- Модификаторы¶
- Повторы¶
- Модификаторы
- Конструкции чередования
- Регулярные выражения PHP
- Квантификаторы
- PHP- функции Regexp POSIX
- Функция preg_replace
- Escape-знаки
- Основной синтаксис регулярных выражений в PHP
Регулярные выражения в PHP
PHP имеет встроенные функции, которые позволяют нам работать с регулярными выражениямии. Давайте теперь посмотрим на часто используемые функции регулярных выражений в PHP.
— эта функция используется для сопоставления с образцом в строке. Она возвращает истину, если совпадение найдено, и ложь, если совпадение не найдено. — эта функция используется для сопоставления с образцом в строке, а затем разбивает результаты в числовой массив. — эта функция используется для сопоставления с образцом строки и затем замены совпадения указанным текстом.Ниже приведен синтаксис функции регулярного выражения, такой как , или :
<?php
function_name('/pattern/',subject);
?>
«function_name (…)» это либо , , либо . «/…/» Косая черта обозначает начало и конец нашего регулярного выражения. «/ pattern /» — это шаблон, который нам нужен. «subject» — текстовая строка, с которой нужно сопоставить.
Давайте теперь посмотрим на практические примеры, которые реализуют вышеупомянутые функции регулярных выражений в PHP.
preg_grep()
Функция preg_grep() перебирает все элементы заданного массива и возвращает все элементы, в которых совпадает заданное регулярное выражение.
Синтаксис функции preg_grep():
array preg_grep(string шаблон, array массив)
Пример использования функции preg_grep() для поиска в массиве слов, начинающихся на р:
$foods = array("pasta", "steak", "fish", "potatoes");
// Поиск элементов, начинающихся с символа "р".
// за которым следует один или несколько символов
$p_foods = preg_grep("/p(\w+)/", $foods);
$х = 0;
while($x < sizeof($p_foods)) :
print $p_foods. "<br>";
$Х++;
endwhile;
Результат:
pasta potatoes
Назад |
Содержание раздела |
Общее Содержание |
Вперед
Мета-символы
Мета характер просто алфавитный символ предшествует обратный слэш , который действует , чтобы дать комбинации особое значение.
Например, вы можете искать большие денежные суммы, используя метасимвол ‘\ d’: / ( +) 000 / , Здесь \ d будет искать любую строку числового символа.
Ниже приведен список метасимволов, которые могут использоваться в регулярных выражениях типа PERL.
| Символ | Описание | |
|---|---|---|
| , | один символ | |
| \ s | символ пробела (пробел, табуляция, новая строка) | |
| \ S | не-пробельный символ | |
| \ d | цифра(0-9) | |
| \ D | — не цифра | |
| \ w | символ слова (az, AZ, 0-9, _) | |
| \ W | — символ без слова | |
| соответствует одному символу в заданном наборе | ||
| соответствует одному символу за пределами заданного набора | ||
| ( foo | bar | baz ) | соответствует любой из указанных альтернатив |
Параметры регулярных выражений
Можно определить параметры, управляющие интерпретацией шаблона регулярного выражения обработчиком регулярных выражений. Многие из этих параметров можно указать в шаблоне регулярного выражения либо в виде одной или нескольких констант RegexOptions. Этот краткий справочник перечисляет только встраиваемые параметры. Дополнительные сведения о встроенных параметрах и параметрах RegexOptions см. в статье Параметры регулярных выражений.
Встроенный параметр можно задать двумя способами:
- С помощью прочих конструкций , где минус (-) перед параметром или набором параметров отключает эти параметры. Например, включает сопоставление без учета регистра (), отключает многострочный режим () и отключает захват неименованных групп (). Параметр применяется к шаблону регулярного выражения от точки, в которой определен параметр, и действует либо до конца шаблона, либо до точки, в которой другая конструкция отменяет параметр.
- С помощью конструкции группированиячасть выражения, которая определяет параметры для только для указанной группы.
Механизм регулярных выражений .NET поддерживает следующие встроенные параметры:
| Параметр | Описание | Шаблон | Число соответствий |
|---|---|---|---|
| Использовать соответствие без учета регистра. | , в | ||
| Использовать многострочный режим. и соответствуют началу и концу строки (line), а не началу и концу строки (string). | Пример см. в подразделе «Многострочный режим» раздела Параметры регулярных выражений. | ||
| Не захватывать неименованные группы. | Пример см. в подразделе «Только явные захваты» раздела Параметры регулярных выражений. | ||
| Использовать однострочный режим. | Пример см. в подразделе «Однострочный режим» раздела Параметры регулярных выражений. | ||
| Игнорировать знаки пробела в шаблоне регулярного выражения, не преобразованные в escape-последовательность. | , в |
Разделители¶
Разделители строк
| Метасимвол | Находит |
|---|---|
| любой символ в строке, может включать разделители строк | |
| совпадение нулевой длины в начале строки | |
| совпадение нулевой длины в конце строки | |
| совпадение нулевой длины в начале строки | |
| совпадение нулевой длины в конце строки | |
| похож на но совпадает перед разделителем строки, а не сразу после него, как |
Примеры:
| RegEx | Находит |
|---|---|
| только если он находится в начале строки | |
| , только если он в конце строки | |
| только если это единственная строка в строке | |
| , , и так далее |
Метасимвол совпадает с точкой начала строки (нулевой длины). — в конце строки. Если включен , они совпадают с началами или концами строк внутри текста.
Обратите внимание, что в последовательности нет пустой строки. Примечание
Примечание
Если вы используете , то / также соответствует , , , или .
Метасимвол совпадает с точкой нулевой длины в начале строки, — в конце (после символов завершения строки). Модификатор на них не влияет. тоже самое что но совпадает с точкой перед символами завершения строки (LF and CR LF).
Метасимвол по умолчанию соответствует любому символу, но если вы выключите , то не будет совпадать с разделителями строк внутри строки.
Обратите внимание, что выражение не соответствует точке между , потому что это неразрывный разделитель строк. Но оно соответствует пустой строке в последовательности , поэтому из-за неправильного порядка кодов он не воспринимается как разделитель строк и считается просто двумя символами
Примечание
Многострочная обработка может быть настроена с помощью свойств и .
Таким образом, вы можете использовать разделители стиля Unix или стиль DOS / Windows или смешивать их вместе (как описано выше по умолчанию).
Если вы предпочитаете математически правильное описание, вы можете найти его на сайте www.unicode.org.
Метасимволы
В приведенных выше примерах использовались очень простые шаблоны. Метасимволы позволяют нам выполнять более сложные сопоставления с образцом, например проверять правильность адреса электронной почты. Давайте теперь посмотрим на часто используемые метасимволы.
| Метасимвол | Описание | Пример |
|---|---|---|
| . | Соответствует любому отдельному символу, кроме новой строки | /./ соответствует всему, что имеет один символ |
| ^ | Соответствует началу или строке/исключает символы | /^PH/ соответствует любой строке, начинающейся с PH |
| $ | Соответствует шаблону в конце строки | /ru$/ соответствует it-blog.ru и т.д. |
| * | Соответствует любому нулю (0) или более символов | /com*/ соответствует computer, communication и т. д. |
| + | Требуется, чтобы предшествующие символы появлялись хотя бы раз | /yah+oo/ соответствует yahoo |
| \ | Используется для экранирования метасимволов | /yahoo+\.com/ трактует точку как буквальное значение |
| Символы внутри скобках | // соответствует abc | |
| a-z | Соответствует строчным буквам | /a-z/ соответствует cool, happy и т.д. |
| A-Z | Соответствует заглавным буквам | /A-Z/ соответствует WHAT, HOW, WHY и т.д. |
| 0-9 | Соответствует любому числу от 0 до 9 | /0-4/ соответствует 0,1,2,3,4 |
Приведенный выше список содержит только наиболее часто используемые метасимволы в регулярных выражениях.
Давайте теперь рассмотрим довольно сложный пример, который проверяет действительность адреса электронной почты.
<?php
$my_email = "name@company.com
";
if (preg_match("/^+@+\.{2,5}$/", $my_email)) {
echo "$my_email это действительный адрес электронной почты";
}
else
{
echo "$my_email это не действительный адрес электронной почты";
}
?>
Строковые методы, поиск и замена
Следующие методы работают с регулярными выражениями из строк.
Все методы, кроме replace, можно вызывать как с объектами типа regexp в аргументах, так и со строками, которые автоматом преобразуются в объекты RegExp.
Так что вызовы эквивалентны:
var i = str.search(/\s/)
var i = str.search("\\s")
При использовании кавычек нужно дублировать \ и нет возможности указать флаги. Если регулярное выражение уже задано строкой, то бывает удобна и полная форма
var regText = "\\s" var i = str.search(new RegExp(regText, "g"))
Возвращает индекс регулярного выражения в строке, или -1.
Если Вы хотите знать, подходит ли строка под регулярное выражение, используйте метод (аналогично RegExp-методы ). Чтобы получить больше информации, используйте более медленный метод (аналогичный методу ).
Этот пример выводит сообщение, в зависимости от того, подходит ли строка под регулярное выражение.
function testinput(re, str){
if (str.search(re) != -1)
midstring = " contains ";
else
midstring = " does not contain ";
document.write (str + midstring + re.source);
}
Если в regexp нет флага , то возвращает тот же результат, что .
Если в regexp есть флаг , то возвращает массив со всеми совпадениями.
Чтобы просто узнать, подходит ли строка под регулярное выражение , используйте .
Если Вы хотите получить первый результат — попробуйте r.
В следующем примере используется, чтобы найти «Chapter», за которой следует 1 или более цифр, а затем цифры, разделенные точкой. В регулярном выражении есть флаг , так что регистр будет игнорироваться.
str = "For more information, see Chapter 3.4.5.1"; re = /chapter (\d+(\.\d)*)/i; found = str.match(re); alert(found);
Скрипт выдаст массив из совпадений:
- Chapter 3.4.5.1 — полностью совпавшая строка
- 3.4.5.1 — первая скобка
- .1 — внутренняя скобка
Следующий пример демонстрирует использование флагов глобального и регистронезависимого поиска с . Будут найдены все буквы от А до Е и от а до е, каждая — в отдельном элементе массива.
var str = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz"; var regexp = //gi; var matches = str.match(regexp); document.write(matches); // matches =
Метод replace может заменять вхождения регулярного выражения не только на строку, но и на результат выполнения функции. Его полный синтаксис — такой:
var newString = str.replace(regexp/substr, newSubStr/function)
- Объект RegExp. Его вхождения будут заменены на значение, которое вернет параметр номер 2
- Строка, которая будет заменена на .
- Строка, которая заменяет подстроку из аргумента номер 1.
- Функция, которая может быть вызвана для генерации новой подстроки (чтобы подставить ее вместо подстроки, полученной из аргумента 1).
Метод не меняет строку, на которой вызван, а просто возвращает новую, измененную строку.
Чтобы осуществить глобальную замену, включите в регулярное выражение флаг .
Если первый аргумент — строка, то она не преобразуется в регулярное выражение, так что, например,
var ab = "a b".replace("\\s","..") // = "a b"
Вызов replace оставил строку без изменения, т.к искал не регулярное выражение , а строку «\s».
В строке замены могут быть такие спецсимволы:
| Pattern | Inserts |
| Вставляет «$». | |
| Вставляет найденную подстроку. | |
| Вставляет часть строки, которая предшествует найденному вхождению. | |
| Вставляет часть строки, которая идет после найденного вхождения. | |
| or | Где или — десятичные цифры, вставляет подстроку вхождения, запомненную -й вложенной скобкой, если первый аргумент — объект RegExp. |
Если Вы указываете вторым параметром функцию, то она выполняется при каждом совпадении.
В функции можно динамически генерировать и возвращать строку подстановки.
Первый параметр функции — найденная подстрока. Если первым аргументом является объект , то следующие параметров содержат совпадения из вложенных скобок. Последние два параметра — позиция в строке, на которой произошло совпадение и сама строка.
Например, следующий вызов возвратит XXzzzz — XX , zzzz.
function replacer(str, p1, p2, offset, s)
{
return str + " - " + p1 + " , " + p2;
}
var newString = "XXzzzz".replace(/(X*)(z*)/, replacer)
Как видите, тут две скобки в регулярном выражении, и потому в функции два параметра , .
Если бы были три скобки, то в функцию пришлось бы добавить параметр .
Следующая функция заменяет слова типа на :
function styleHyphenFormat(propertyName)
{
function upperToHyphenLower(match)
{
return '-' + match.toLowerCase();
}
return propertyName.replace(//, upperToHyphenLower);
}
matchAll()
Подобно методу , возвращает все совпадения при использовании флага в шаблоне. Однако работает он по-другому. Метод возвращает объект . Есть несколько способов извлечь из него все совпадения.
Во-первых, можно пройтись по объекту циклом и вернуть или записать все совпадения. Также можно использовать , чтобы создать массив из содержимого объекта, или оператор spread, который даст точно такой же результат, как и .
// Синтаксис метода match()// ‘проверяемый текст’.match(/шаблон/)// Создание текста для проверкиconst myString = ‘The world of code is not full of code.’// Описание шаблонаconst myPattern = /code/g// Обратите внимание, что используется флаг ‘g’// Использование matchAll() для поиска совпадений в текстеconst matches = myString.matchAll(myPattern)// Использование цикла for…of для получения всех совпаденийfor (const match of matches) { console.log(match)}// [// [// ‘code’,// index: 13,// input: ‘The world of code is not full of code.’,// groups: undefined// ],// [// ‘code’,// index: 33,// input: ‘The world of code is not full of code.’,// groups: undefined// ]// ]// Использование Array.from() для получения всех совпаденийconst matches = Array.from(myString.matchAll(myPattern))// [// [// ‘code’,// index: 13,// input: ‘The world of code is not full of code.’,// groups: undefined// ],// [// ‘code’,// index: 33,// input: ‘The world of code is not full of code.’,// groups: undefined// ]// ]// Использование оператора spread для получения всех совпаденийconst matches = // [// [// ‘code’,// index: 13,// input: ‘The world of code is not full of code.’,// groups: undefined// ],// [// ‘code’,// index: 33,// input: ‘The world of code is not full of code.’,// groups: undefined// ]// ]
Как создавать простые шаблоны?
Вы узнали, как создавать и использовать регулярные выражения. Теперь давайте рассмотрим процесс создания шаблонов. Простейший способ составлять регулярные выражения —применение простых шаблонов. Это значит, что необходимо создать строку с особым текстом, а затем проверить, имеет ли какая-то другая строка совпадения с этим текстом.
// Создание простого шаблона// с использованием литерала регулярного выраженияconst myPattern = /JavaScript/// Проверка строки на совпадения с шаблономmyPattern.test('One of the most popular languages is also JavaScript.')// true// Проверка строки на совпадения с шаблономmyPattern.test('What happens if you combine Java with scripting?')// false
Как создавать сложные шаблоны со специальными символами?
До сих пор мы использовали регулярные выражения из простых шаблонов. Их может быть достаточно для каких-то простых задач. Однако для сложных случаев такие выражения не подойдут. Настало время создавать и использовать более сложные шаблоны. Здесь в игру вступают специальные символы. Давайте рассмотрим те из них, которые наиболее часто используются в регулярных выражениях.
Примеры preg_match PHP
1.
if (!preg_match("/^*\@*\.{2,6}$/i", $email)) exit("Неправильный адрес");
2.
// \S означает "не пробел", а + -
// "любое число букв, цифр или точек". Модификатор 'i' после '/'
// заставляет PHP не учитывать регистр букв при поиске совпадений.
// Модификатор 's', стоящий рядом с 'i', говорит, что мы работаем
// в "однострочном режиме" (см. ниже в этой главе).
preg_match('/(\S+)@(+)/is', "Привет от somebody@mail.ru!", $p);
// Имя хоста будет в $p, а имя ящика (до @) - в $p.
echo "В тексте найдено: ящик - $p, хост - $p";
3.
if (!preg_match("|^{13,16}$|", $var)) ...
4.
if (preg_match("/(^+(*))$/" , $filename)==NULL) {
echo "invalid filename";
exit;
}
/\.(?:z(?:ip|{2})|r(?:ar|{2})|jar|bz2|gz|tar|rpm)$/i
/\.(?:mp3|wav|og(?:g|a)|flac|midi?|rm|aac|wma|mka|ape)$/i
/\.(?:exe|msi|dmg|bin|xpi|iso)$/i
/\.(?:jp(?:e?g|e|2)|gif|png|tiff?|bmp|ico)$/i
/\.(?:mpeg|ra?m|avi|mp(?:g|e|4)|mov|divx|asf|qt|wmv|m\dv|rv|vob|asx|ogm)$/i
5.
preg_match_all('/(8|7|\+7){0,1}{0,}({2}){0,}(({2}{0,}{2}{0,}{3})|({3}{0,}{2}{0,}{2})|({3}{0,}{1}{0,}{3})|({2}{0,}{3}{0,}{2}))/',
$text, $regs );
6.
if (preg_match("/^{8,20}$/",$string)) echo "yes"; else echo "no";
7.абвгДДДеёааббаабб
if (preg_match("/(.)\\1\\1/",$string)) echo "yes"; else echo "no";
8.
preg_match("/abc/", $string); // true если найдёт в любом месте
preg_match("/^abc/", $string); // true если найдёт в начале
preg_match("/abc$/", $string); // true если найдёт в конце
9.
preg_match("/(ozilla.|MSIE.3)/i", $_SERVER);
Модификаторы¶
Синтаксис для одного модификатора: чтобы включить, и чтобы выключить. Для большого числа модификаторов используется синтаксис: .
Можно использовать внутри регулярного выражения. Это может быть особенно удобно, поскольку оно имеет локальную область видимости. Оно влияет только на ту часть регулярного выражения, которая следует за оператором .
И если оно находится внутри подвыражения, оно будет влиять только на это подвыражение, а именно на ту часть подвыражения, которая следует за оператором. Таким образом, в это влияет только на подвыражение , поэтому оно будет соответствовать , но не .
Повторы¶
Повтор
За любым элементом регулярного выражения может следовать допустимое число повторений элемента.
| RegEx | Находит |
|---|---|
| ровно раз | |
| по крайней мере раз | |
| по крайней мере , но не более чем раз | |
| ноль или более, аналогично | |
| один или несколько, похожие на | |
| ноль или единица, похожая на |
То есть цифры в фигурных скобках определяются минимальное и максимальное количество повторов (совпадений во входном тексте).
эквивалентно и означает . совпадает или более раз.
Теоретически значение n и m не ограничены (можно использовать максимальное значение для 32-х битного числа).
| RegEx | Находит |
|---|---|
| , и | |
| , , но не | |
| , и , но не | |
| , , и т. д. | |
| , или , но не | |
| , или экземпляров ( это ) |
Жадность
в режиме захватывают как можно больше из входного текста, в режиме — как можно меньше.
По умолчанию все повторы являются . Используйте Чтобы сделать любой повтор .
Для строки :
| RegEx | Находит |
|---|---|
| пустую строку | |
Вы можете переключить все повторы в режим (, ниже мы используем ).
| RegEx | Находит |
|---|---|
Модификаторы
Доступны несколько модификаторов, которые могут облегчить вашу работу с регулярными выражениями , например, чувствительность к регистру, поиск по нескольким линиям и т.д.
| Модификатор | Описание |
|---|---|
| i | Делает регистр без учета регистра |
| m | Указывает, что если строка имеет новую строку или каретку возвращаемые символы, теперь будут выполняться операторы ^ и $ сопоставление с границей новой строки, а не граница строки |
| o | оценивает выражение только один раз |
| s | Позволяет использовать. для соответствия символу новой строки |
| x | Позволяет использовать пробел в выражении для ясности |
| g | Глобально находит все совпадения |
| cg | Позволяет продолжить поиск даже после сбоя глобального соответствия |
Конструкции чередования
Конструкции изменения модифицируют регулярное выражение, включая сопоставление по принципу «либо-либо». Такие конструкции состоят из языковых элементов, приведенных в следующей таблице. Дополнительные сведения см. в разделе Конструкции чередования.
| Конструкция изменения | Описание | Шаблон | Число соответствий |
|---|---|---|---|
| Соответствует любому элементу, разделенному вертикальной чертой (). | , в | ||
| expression yes no | Соответствует да в случае соответствия шаблона регулярного выражения, определяемого выражением; в противном случае соответствует дополнительной части нет. Выражение интерпретируется как утверждение нулевой ширины. | , в | |
| name yes no | Соответствует да в случае соответствия именованной или нумерованной группы захвата имя; в противном случае соответствует дополнительной части нет. | , в |
Регулярные выражения PHP
PHP содержит встроенные функции, которые позволяют работать с регулярными выражениями. Теперь рассмотрим часто используемые функции регулярных выражений PHP.
- preg_match — используется для выполнения сопоставления с шаблоном строки. Она возвращает true, если совпадение найдено, и false, если совпадение не найдено;
- preg_split — используется для разбивки строки по шаблону, результат возвращается в виде числового массива;
- preg_replace – используется для поиска по шаблону и замены на указанную строку.
Ниже приведен синтаксис функций регулярных выражений, таких как preg_match, preg_split или PHP regexp replace:
<?php
имя_функции('/шаблон/',объект);
?>
, где
«имя_функции» — это либо preg_match, либо preg_split, либо preg_replace.«/…/» — косые черты обозначают начало и конец регулярного выражения.«‘/шаблон/’» — шаблон, который нам нужно сопоставить.«объект» — строка, с которой нужно сопоставлять шаблон.
Теперь рассмотрим практические примеры использования упомянутых выше функций.
Preg match PHP
В первом примере функция preg_match используется для выполнения простого сопоставления шаблоном для слова guru в заданном URL-адресе.
В приведенном ниже коде показан вариант реализации данного примера:
<?php
$my_url = "www.guru99.com";
if (preg_match("/guru/", $my_url))
{
echo "the url $my_url contains guru";
}
else
{
echo "the url $my_url does not contain guru";
}
?>
«preg_match (‘/ guru /’, $ my_url)»
Здесь:
«preg_match(…)» — функция PHP match regexp.«‘/Guru/’» — шаблон регулярного выражения.«$My_url» — переменная, содержащая текст, с которым нужно сопоставить шаблон.
Preg split PHP
Рассмотрим другой пример, в котором используется функция preg_split.
Мы возьмем фразу и разобьем ее на массив; шаблон предназначен для поиска единичного пробела:
<?php
$my_text="I Love Regular Expressions";
$my_array = preg_split("/ /", $my_text);
print_r($my_array );
?>
Preg replace PHP
Рассмотрим функцию preg_replace, которая выполняет сопоставление с шаблоном и заменяет найденный результат другой строкой.
Приведенный ниже код ищет в строке слово guru. Он заменяет его кодом css, который задает цвет фона:
<?php
$text = "We at Guru99 strive to make quality education affordable to the masses. Guru99.com";
$text = preg_replace("/Guru/", '<span style="background:yellow">Guru</span>', $text);
echo $text;
?>
Квантификаторы
Квантор указывает количество вхождений предшествующего элемента (знака, группы или класса знаков), которое должно присутствовать во входной строке, чтобы было зафиксировано соответствие. Кванторы состоят из языковых элементов, приведенных в следующей таблице. Для получения дополнительной информации см. Квантификаторы.
| Квантификатор | Описание | Шаблон | Число соответствий |
|---|---|---|---|
| Соответствует предыдущему элементу ноль или более раз. | , , | ||
| Соответствует предыдущему элементу один или более раз. | в , в | ||
| Соответствует предыдущему элементу ноль или один раз. | , | ||
| n | Предыдущий элемент повторяется ровно n раз. | в , , и в | |
| n | Предыдущий элемент повторяется как минимум n раз. | , , | |
| n m | Предыдущий элемент повторяется как минимум n раз, но не более чем m раз. | , в | |
| Предыдущий элемент не повторяется вообще или повторяется, но как можно меньшее число раз. | , , | ||
| Предыдущий элемент повторяется один или несколько раз, но как можно меньшее число раз. | в , в | ||
| Предыдущий элемент не повторяется или повторяется один раз, но как можно меньшее число раз. | , | ||
| n | Предыдущий элемент повторяется ровно n раз. | в , , и в | |
| n | Предыдущий элемент повторяется как минимум n раз (как можно меньше). | , , | |
| n m | Предыдущий элемент повторяется не менее n и не более m раз (как можно меньше). | , , в |
PHP- функции Regexp POSIX
PHP в настоящее время предлагает семь функций для поиска строк с использованием регулярных выражений в стиле POSIX —
| Значение | Описание |
|---|---|
| ereg() | Функция ereg() ищет строку, указанную строкой для строки, заданной шаблоном, возвращает true, если шаблон найден, и false в противном случае. |
| ereg_replace () | Функция ereg_replace() ищет строку, указанную в шаблоне, и заменяет шаблон заменой, если найден. |
| eregi() | Функция eregi() выполняет поиск по всей строке, заданной шаблоном, для строки, указанной строкой. Поиск не чувствителен к регистру. |
| eregi_replace() | Функция eregi_replace() работает точно так же, как и ereg_replace(), за исключением того, что поиск шаблона в строке не чувствителен к регистру. |
| Split() | Функция split() будет разделять строку на различные элементы, границы каждого элемента на основе появления шаблона в строке. |
| spliti() | Функция spliti() работает точно так же, как и sibling split(), за исключением того, что она не чувствительна к регистру. |
| sql_regcase() | Функция sql_regcase() может рассматриваться как служебная функция, преобразующая каждый символ в строку входных параметров в выражение в квадратных скобках, содержащее два символа. |
Функция preg_replace
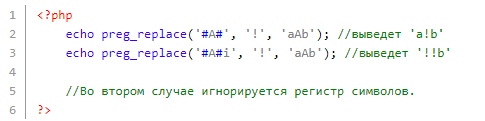
Основные функции PHP (match, split и replace), предназначенные для работы с регулярками, мы уже перечислили. В этой статье рассмотрим особенности функционирования preg_replace: данная функция напоминает str_replace, — функцию для поиска и замены, только лишь в качестве первого параметра здесь принимается не просто строка, а регулярное выражение. Разница следующая:

Здесь нужно обратить внимание на решетки # — в них помещена буква «а» — их называют ограничителями используемых в коде регулярных выражений. После ограничителей пишутся модификаторы — команды, меняющие общие свойства регулярки
Тот же модификатор i заставит проигнорировать регистр символов:
Escape-знаки
Обратная косая черта (\) в регулярных выражениях указывает, что следующий за ней символ либо является специальным знаком (как показано в следующей таблице), либо должен интерпретироваться буквально. Дополнительные сведения см. в разделе Escape-символы.
| Escape-символ | Описание | Шаблон | Число соответствий |
|---|---|---|---|
| Соответствует знаку колокольчика, \u0007. | в | ||
| В классе символов соответствует знаку BACKSPACE, \u0008. | в | ||
| Соответствует знаку табуляции, \u0009. | , в | ||
| Соответствует знаку возврата каретки, \u000D. ( не эквивалентен знаку начала новой строки, .) | в | ||
| Соответствует знаку вертикальной табуляции, \u000B. | в | ||
| Соответствует знаку перевода страницы, \u000C. | в | ||
| Соответствует знаку новой строки, \u000A. | в | ||
| Соответствует escape-знаку, \u001B. | в | ||
| nnn | Использует восьмеричное представление для указания символа (nnn состоит из двух или трех цифр). | , в | |
| nn | Использует шестнадцатеричное представление для указания символа (nn состоит ровно из двух цифр). | , в | |
| Xx | Соответствует управляющему символу ASCII, который задан как X или x, где X или x является буквой управляющего символа. | в (Ctrl-C) | |
| nnnn | Совпадение со знаком Юникода в шестнадцатеричном представлении (строго четыре цифры, представленные как nnnn). | , в | |
| Если за этим знаком следует символ, не распознанный как escape-символ из этой и других таблиц данной темы, то соответствует в точности этому символу. Например, — это то же самое, что и , а — то же самое, что и . Это позволяет обработчику регулярных выражений распознавать языковые элементы (такие как *или ?) и символьные литералы (представленные как или ). | и в |
Основной синтаксис регулярных выражений в PHP
Чтобы использовать регулярные выражения, сначала вам нужно изучить синтаксис шаблонов. Мы можем сгруппировать символы внутри шаблона следующим образом:
- Обычные символы, которые следуют один за другим, например,
- Индикаторы начала и окончания строки в виде и
- Индикаторы подсчета, такие как , ,
- Логические операторы, такие как
- Группирующие операторы, такие как , ,
Пример шаблона регулярного выражения для проверки правильности адреса электронного ящика выглядит следующим образом:
^+@+\.{2,5}$
Код PHP для проверки электронной почты с использованием Perl-совместимого регулярного выражения выглядит следующим образом:
<?php
$pattern = "/^+@+\.{2,5}$/";
$email = "some-email@test.com";
if (preg_match($pattern, $email)) {
echo "Проверка пройдена успешно!";
} else {
echo "Проверка не пройдена!";
}
?>
Теперь давайте посмотрим на подробный разбор синтаксиса шаблона при регулярном выражении:
| Регулярное выражение (шаблон) | Проходит проверку (объект) | Не проходит проверку (объект) | Комментарий |
| Hello world | Hello Ivan | Проходит, если шаблон присутствует где-либо в объекте | |
| world class | Hello world | Проходит, если шаблон присутствует в начале объекта | |
| Hello world | world class | Проходит, если шаблон присутствует в конце объекта | |
| This WoRLd | Hello Ivan | Выполняет поиск в нечувствительном к регистру режиме | |
| world | Hello world | Строка содержит только «world» | |
| worl, world, worlddd | wor | Присутствует 0 или больше «d» после «worl» | |
| world, worlddd | worl | Присутствует по крайней мере одна «d» после «worl» | |
| worl, world, worly | wor, wory | Присутствует 0 или 1 «d» после «worl» | |
| world | worly | Присутствует одна «d» после «worl» | |
| world, worlddd | worly | Присутствует одна или больше «d» после «worl» | |
| worldd, worlddd | world | Присутствует 2 или 3 «d» после «worl» | |
| wo, world, worldold | wa | Присутствует 0 или больше «rld» после «wo» | |
| earth, world | sun | Строка содержит «earth» или «world» | |
| world, wwrld | wrld | Содержит любой символ вместо точки | |
| world, earth | sun | Строка содержит ровно 5 символов | |
| abc, bbaccc | sun | В строке есть «a», или «b» или «c» | |
| world | WORLD | В строке есть любые строчные буквы | |
| world, WORLD, Worl12 | 123 | В строке есть любые строчные или прописные буквы | |
| earth | w, W | Фактический символ не может быть «w» или «W» |
Теперь перейдем к более сложному регулярному выражению с подробным объяснением.